3DiFACE: Synthesizing and Editing Holistic 3D Facial Animation
作者: Balamurugan Thambiraja, Malte Prinzler, Sadegh Aliakbarian, Darren Cosker, Justus Thies
分类: cs.GR, cs.AI, cs.CV
发布日期: 2025-09-30
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出3DiFACE,用于合成和编辑具有真实头部运动的整体3D面部动画
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 3D面部动画 语音驱动 扩散模型 风格个性化 运动编辑
📋 核心要点
- 现有语音驱动的3D面部动画方法难以生成具有精确控制和真实头部运动的个性化动画,且编辑复杂耗时。
- 3DiFACE提出一种整体语音驱动的3D面部动画方法,利用全卷积扩散模型和稀疏引导运动扩散实现多样性和可控性。
- 实验结果表明,该方法能够根据音频输入生成和编辑多样化的3D面部动画,并在保真度和多样性之间取得平衡。
📝 摘要(中文)
现有的语音驱动3D面部动画方法在创建具有精确控制和真实头部运动的个性化3D动画方面仍然面临挑战。编辑这些动画尤其复杂且耗时,需要精确的控制,通常由高技能动画师处理。大多数现有工作侧重于控制合成动画的风格或情感,无法编辑/重新生成输入动画的某些部分。此外,它们忽略了多个合理的嘴唇和头部运动可以匹配相同音频输入的事实。为了解决这些挑战,我们提出了3DiFACE,一种用于整体语音驱动3D面部动画的新方法。我们的方法为单个音频输入生成多样且合理的嘴唇和头部运动,并允许通过关键帧和插值进行编辑。具体来说,我们提出了一个完全卷积扩散模型,可以利用我们训练语料库中的音素级别多样性。此外,我们采用说话风格个性化和一种新颖的稀疏引导运动扩散,以实现精确的控制和编辑。通过定量和定性评估,我们证明了我们的方法能够根据单个音频输入生成和编辑多样化的整体3D面部动画,并在高保真度和多样性之间进行控制。
🔬 方法详解
问题定义:现有语音驱动3D面部动画方法的主要痛点在于难以生成具有真实头部运动和精确控制的个性化动画。编辑这些动画需要专业技能,且现有方法无法灵活地编辑或重新生成动画的特定部分。此外,现有方法通常忽略了同一段语音可以对应多种合理的唇部和头部运动的可能性。
核心思路:3DiFACE的核心思路是利用扩散模型学习语音和面部运动之间的复杂映射关系,并引入说话风格个性化和稀疏引导运动扩散机制,从而实现对生成动画的多样性和可控性。通过扩散模型,可以生成多种合理的面部运动,而个性化和稀疏引导则允许用户精确地编辑和控制动画。
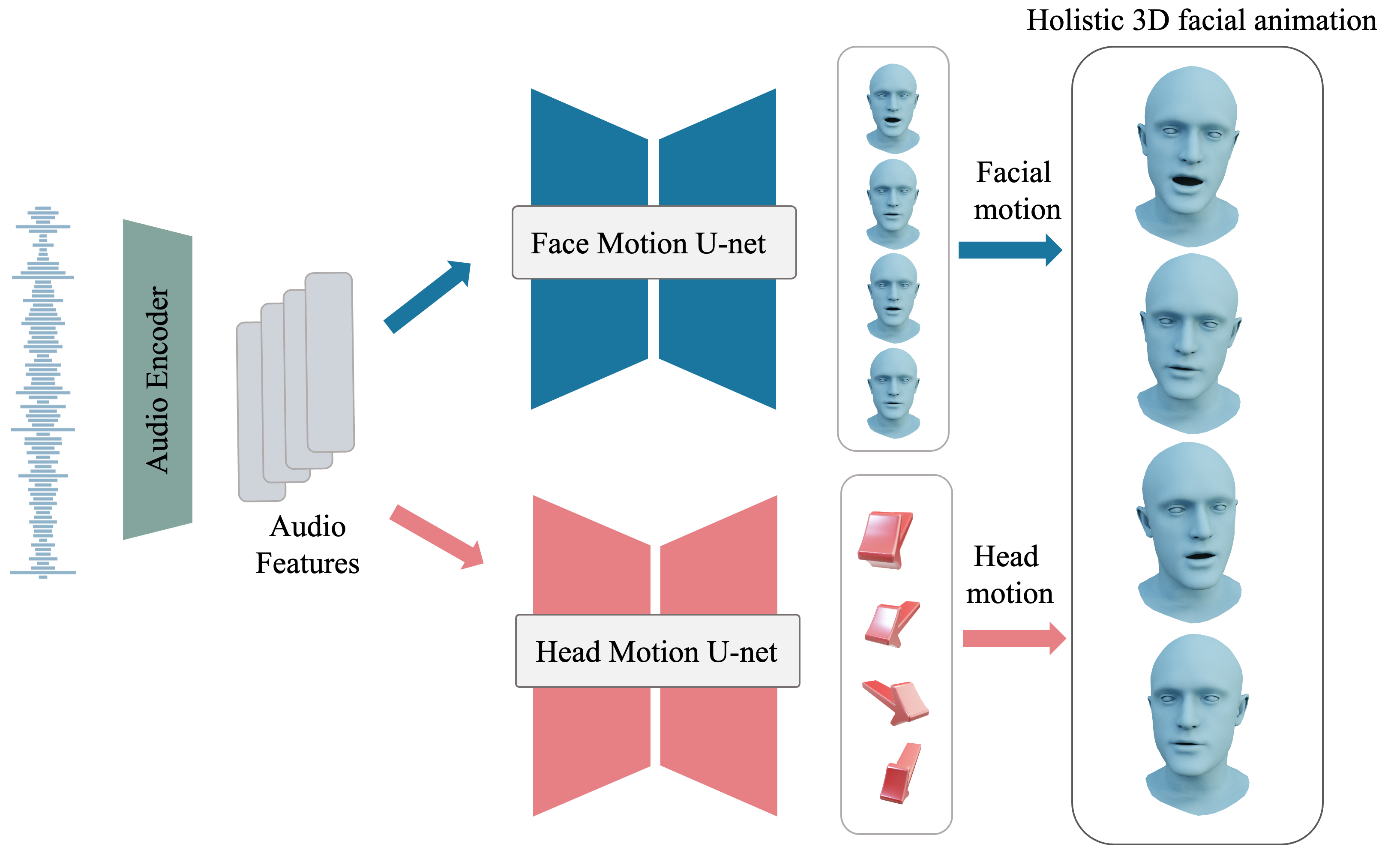
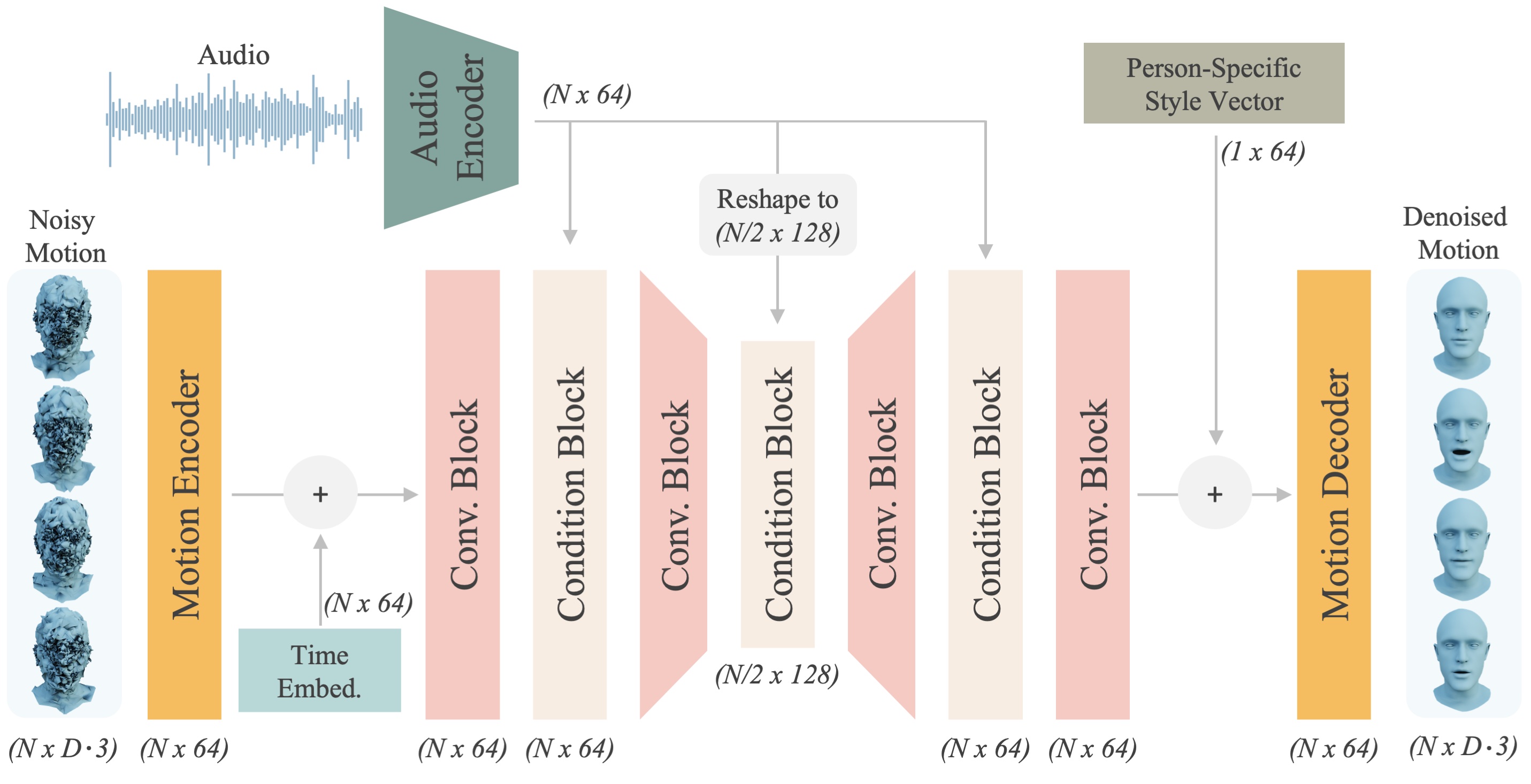
技术框架:3DiFACE的整体框架包含以下几个主要模块:1) 音频特征提取模块,用于提取输入音频的特征表示;2) 全卷积扩散模型,用于学习音频特征到3D面部运动的映射;3) 说话风格个性化模块,用于调整生成动画的风格;4) 稀疏引导运动扩散模块,用于实现对动画的精确控制和编辑。整个流程是从音频输入开始,经过特征提取和扩散模型生成初始动画,然后通过个性化和稀疏引导进行调整和编辑,最终得到所需的3D面部动画。
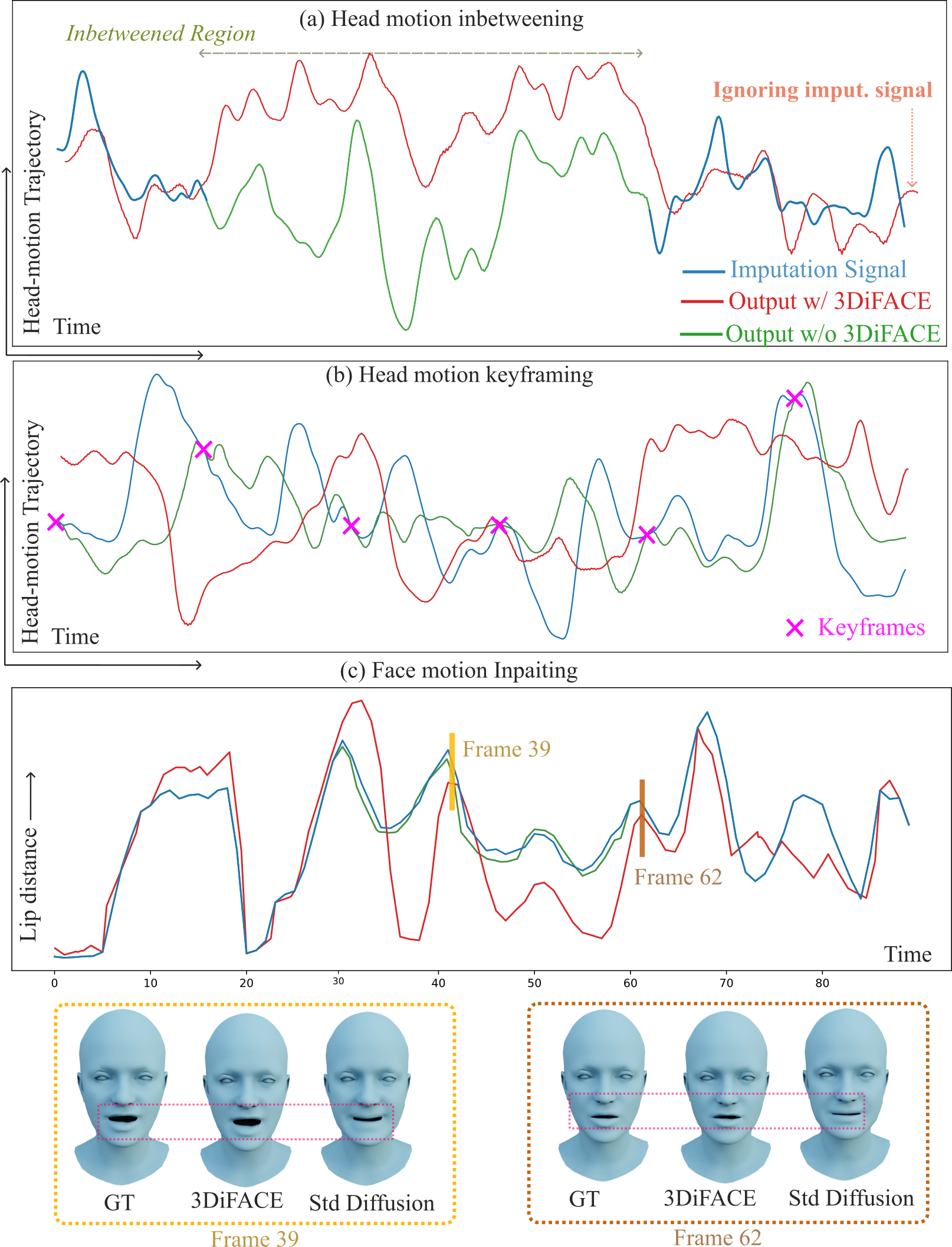
关键创新:3DiFACE的关键创新在于以下几个方面:1) 提出了一个全卷积扩散模型,能够有效地学习语音和面部运动之间的复杂关系,并生成多样化的面部运动;2) 引入了说话风格个性化机制,允许用户调整生成动画的风格;3) 提出了稀疏引导运动扩散方法,实现了对动画的精确控制和编辑,用户可以通过关键帧等方式对动画进行干预。
关键设计:在技术细节方面,3DiFACE采用了全卷积网络作为扩散模型的基础架构,并使用了音素级别的多样性训练数据。损失函数方面,可能使用了L1或L2损失来衡量生成动画和目标动画之间的差异。稀疏引导运动扩散可能通过在扩散过程中引入稀疏的关键帧约束来实现,具体实现细节未知。
🖼️ 关键图片
📊 实验亮点
论文通过定量和定性实验验证了3DiFACE的有效性。实验结果表明,该方法能够生成多样且逼真的3D面部动画,并在保真度和多样性之间取得良好的平衡。用户可以通过关键帧等方式对动画进行精确的编辑和控制。具体的性能数据和对比基线未知。
🎯 应用场景
3DiFACE技术可广泛应用于虚拟形象定制、游戏角色动画、电影特效制作、在线教育等领域。该技术能够根据语音自动生成逼真的3D面部动画,并允许用户进行精细的编辑和控制,极大地提高了动画制作的效率和质量。未来,该技术有望应用于更广泛的人机交互场景,例如智能客服、虚拟助手等。
📄 摘要(原文)
Creating personalized 3D animations with precise control and realistic head motions remains challenging for current speech-driven 3D facial animation methods. Editing these animations is especially complex and time consuming, requires precise control and typically handled by highly skilled animators. Most existing works focus on controlling style or emotion of the synthesized animation and cannot edit/regenerate parts of an input animation. They also overlook the fact that multiple plausible lip and head movements can match the same audio input. To address these challenges, we present 3DiFACE, a novel method for holistic speech-driven 3D facial animation. Our approach produces diverse plausible lip and head motions for a single audio input and allows for editing via keyframing and interpolation. Specifically, we propose a fully-convolutional diffusion model that can leverage the viseme-level diversity in our training corpus. Additionally, we employ a speaking-style personalization and a novel sparsely-guided motion diffusion to enable precise control and editing. Through quantitative and qualitative evaluations, we demonstrate that our method is capable of generating and editing diverse holistic 3D facial animations given a single audio input, with control between high fidelity and diversity. Code and models are available here: https://balamuruganthambiraja.github.io/3DiFACE