Unsupervised Representation Learning for 3D Mesh Parameterization with Semantic and Visibility Objectives
作者: AmirHossein Zamani, Bruno Roy, Arianna Rampini
分类: cs.GR, cs.CV
发布日期: 2025-09-29 (更新: 2026-01-02)
🔗 代码/项目: GITHUB
💡 一句话要点
提出一种无监督3D网格参数化方法,优化语义对齐和可见性,提升纹理生成质量。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 3D网格参数化 UV映射 无监督学习 语义分割 可见性优化
📋 核心要点
- 现有3D生成模型依赖手动网格参数化(UV映射),该过程耗时且需要专业技能,成为3D内容创作的瓶颈。
- 论文提出一种无监督框架,通过语义分割和可见性优化,自动生成高质量的UV映射,无需人工干预。
- 实验结果表明,该方法生成的UV图集在纹理生成方面优于现有方法,并减少了可见的缝合线伪影。
📝 摘要(中文)
本文提出了一种无监督可微框架,用于自动化3D网格参数化过程,旨在克服现有方法在语义感知和可见性感知方面的不足。该方法通过语义和可见性目标来增强标准的几何保持UV学习。在语义感知方面,该流程首先将网格分割成语义3D部分,然后应用无监督学习的逐部分UV参数化骨干网络,最后将各部分的图表聚合为统一的UV图集。在可见性感知方面,使用环境光遮蔽(AO)作为曝光代理,并通过反向传播一个软可微的AO加权缝合线目标,引导切割缝合线朝向遮挡区域。通过与最先进方法进行定性和定量评估,结果表明,该方法生成的UV图集能够更好地支持纹理生成,并减少了与现有基线相比可感知的缝合线伪影。
🔬 方法详解
问题定义:现有3D网格参数化方法依赖于手动UV映射,耗时耗力。自动方法通常忽略语义信息(相似部件对齐)和可见性(缝合线位置),导致纹理生成质量下降,产生明显的缝合线伪影。
核心思路:论文的核心思路是利用无监督学习,通过引入语义感知和可见性感知的目标函数,自动生成高质量的UV映射。语义感知确保UV图表在语义上对齐相似的3D部件,而可见性感知则引导缝合线位于不太容易被观察到的区域。
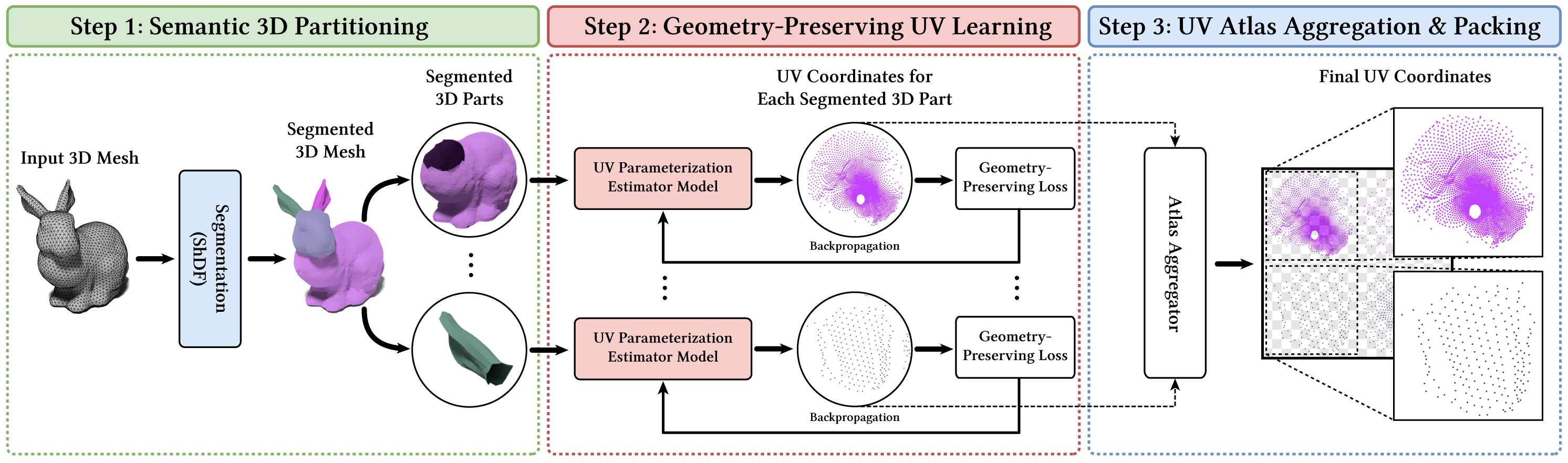
技术框架:整体框架包含三个主要阶段:1) 语义分割:将3D网格分割成语义上有意义的部件。2) 逐部分UV参数化:对每个部件应用无监督学习的UV参数化骨干网络,生成局部UV图。3) 图集聚合:将各个部件的UV图聚合为一个统一的UV图集。同时,利用环境光遮蔽(AO)信息,优化缝合线的位置。
关键创新:该方法最重要的创新点在于将语义信息和可见性信息融入到无监督UV参数化学习中。通过语义分割和AO加权损失函数,引导网络学习更符合人类感知的UV映射,减少了人工干预的需求。与现有方法相比,该方法能够生成语义对齐且缝合线隐藏的UV图集。
关键设计:语义分割可以使用现有的3D分割算法。逐部分UV参数化骨干网络可以使用各种几何保持的UV学习方法。关键在于AO加权缝合线损失函数的设计,该函数利用AO值作为权重,惩罚位于高可见性区域的缝合线。具体而言,损失函数可以设计为AO值的加权和,AO值越高,损失越大,从而推动缝合线向遮挡区域移动。
🖼️ 关键图片

📊 实验亮点
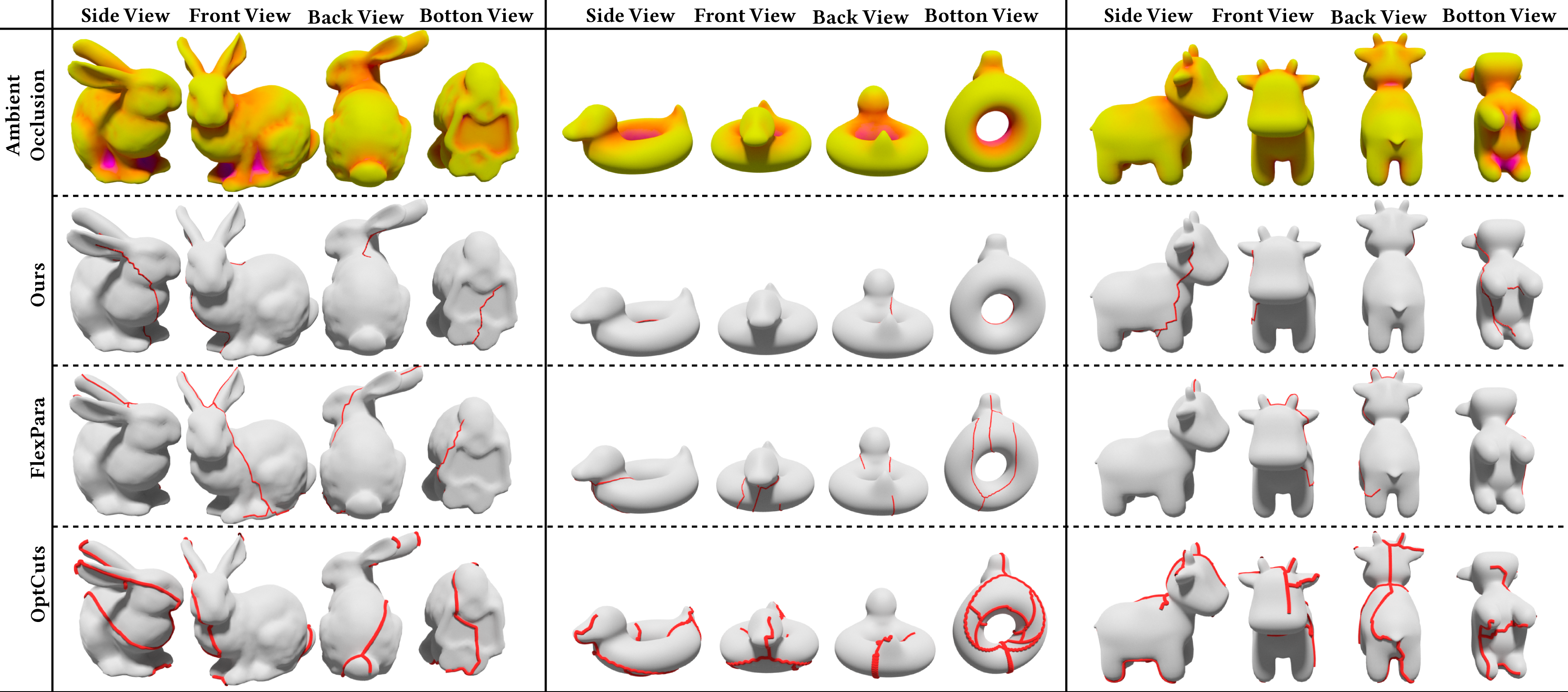
实验结果表明,该方法生成的UV图集在语义对齐和缝合线隐藏方面优于现有方法。定性结果显示,生成的纹理在语义上更加一致,缝合线伪影更少。定量评估(具体指标未知)也证实了该方法的有效性,表明其能够更好地支持纹理生成,并减少可感知的缝合线伪影。
🎯 应用场景
该研究成果可应用于游戏开发、电影制作、虚拟现实、增强现实等领域,显著降低3D内容创作的成本和时间。通过自动生成高质量的UV映射,艺术家可以更专注于纹理设计和艺术创作,提高生产效率和最终产品的质量。此外,该方法还可以用于3D扫描数据的自动处理,加速数字化流程。
📄 摘要(原文)
Recent 3D generative models produce high-quality textures for 3D mesh objects. However, they commonly rely on the heavy assumption that input 3D meshes are accompanied by manual mesh parameterization (UV mapping), a manual task that requires both technical precision and artistic judgment. Industry surveys show that this process often accounts for a significant share of asset creation, creating a major bottleneck for 3D content creators. Moreover, existing automatic methods often ignore two perceptually important criteria: (1) semantic awareness (UV charts should align semantically similar 3D parts across shapes) and (2) visibility awareness (cutting seams should lie in regions unlikely to be seen). To overcome these shortcomings and to automate the mesh parameterization process, we present an unsupervised differentiable framework that augments standard geometry-preserving UV learning with semantic- and visibility-aware objectives. For semantic-awareness, our pipeline (i) segments the mesh into semantic 3D parts, (ii) applies an unsupervised learned per-part UV-parameterization backbone, and (iii) aggregates per-part charts into a unified UV atlas. For visibility-awareness, we use ambient occlusion (AO) as an exposure proxy and back-propagate a soft differentiable AO-weighted seam objective to steer cutting seams toward occluded regions. By conducting qualitative and quantitative evaluations against state-of-the-art methods, we show that the proposed method produces UV atlases that better support texture generation and reduce perceptible seam artifacts compared to recent baselines. Our implementation code is publicly available at: https://github.com/AHHHZ975/Semantic-Visibility-UV-Param.