Learning to Ball: Composing Policies for Long-Horizon Basketball Moves
作者: Pei Xu, Zhen Wu, Ruocheng Wang, Vishnu Sarukkai, Kayvon Fatahalian, Ioannis Karamouzas, Victor Zordan, C. Karen Liu
分类: cs.GR, cs.AI, cs.LG, cs.RO
发布日期: 2025-09-26
备注: ACM Transactions on Graphics (Proceedings of SIGGRAPH Asia 2025). Website: http://pei-xu.github.io/basketball. Video: https://youtu.be/2RBFIjjmR2I. Code: https://github.com/xupei0610/basketball
期刊: ACM Transactions on Graphics (December 2025)
DOI: 10.1145/3763367
💡 一句话要点
提出一种策略集成框架,用于学习篮球动作等长时程多阶段任务的控制策略。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 强化学习 策略组合 长时程任务 篮球动作 软路由
📋 核心要点
- 现有强化学习方法在处理篮球动作等长时程任务时,难以实现策略的无缝组合和技能间的平滑过渡。
- 论文提出一种新颖的策略集成框架,通过高层软路由实现子任务间的无缝过渡,从而解决长时程任务的策略组合问题。
- 实验表明,该方法能够有效控制模拟角色完成篮球动作,并能根据用户实时指令完成长时程任务,无需轨迹参考。
📝 摘要(中文)
针对篮球动作等多阶段、长时程任务中强化学习方法在策略组合和技能过渡方面的挑战,本文提出了一种新的策略集成框架。长时程任务通常包含具有明确目标的不同子任务,以及目标不明确但对整个任务成功至关重要的过渡子任务。现有方法如混合专家和技能链在各个策略之间缺乏共同探索状态或不同阶段之间缺乏明确的初始和终止状态时表现不佳。本文进一步引入了一个高层软路由,以实现子任务之间无缝且鲁棒的过渡。该框架在一系列基本篮球技能和具有挑战性的过渡上进行了评估。实验结果表明,该方法训练的策略可以有效地控制模拟角色与球互动,并完成由实时用户命令指定的长时程任务,而无需依赖球的轨迹参考。
🔬 方法详解
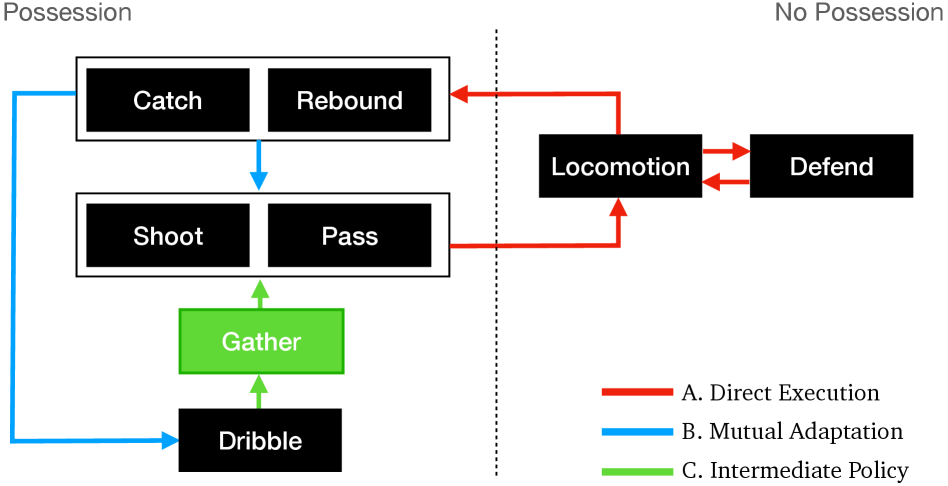
问题定义:论文旨在解决长时程、多阶段任务(例如篮球动作)中,如何学习有效的控制策略的问题。现有方法,如混合专家和技能链,在处理子任务之间状态空间重叠较少或缺乏明确的初始/终止状态的任务时表现不佳,导致策略组合困难,过渡不流畅。这些方法难以应对篮球动作中复杂的技能切换和环境交互。
核心思路:论文的核心思路是将长时程任务分解为多个子任务,并为每个子任务学习独立的策略。然后,通过一个高层软路由(soft router)来动态地选择和组合这些策略,从而实现子任务之间的平滑过渡。这种方法允许各个策略专注于特定的技能,同时利用软路由来处理策略之间的衔接问题。
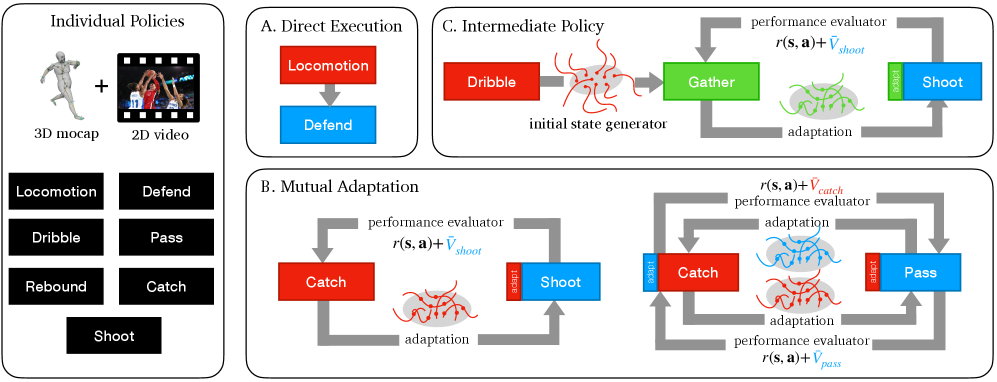
技术框架:整体框架包含两个主要部分:1) 多个独立的策略模块,每个模块负责一个特定的子任务(例如运球、投篮);2) 一个高层软路由模块,负责根据当前状态动态地选择合适的策略模块。软路由接收当前状态作为输入,输出一个策略选择的概率分布,然后根据这个分布对各个策略模块的输出进行加权平均,得到最终的控制动作。
关键创新:论文的关键创新在于引入了高层软路由来实现策略的动态组合。与传统的硬切换方法相比,软路由允许策略之间存在重叠和混合,从而实现更平滑和自然的过渡。此外,该方法不需要预先定义子任务之间的明确边界,而是通过学习的方式来自动发现最优的过渡策略。
关键设计:软路由通常实现为一个神经网络,其输入是当前状态,输出是各个策略模块的选择概率。损失函数的设计需要考虑两个方面:1) 保证每个策略模块能够有效地完成其对应的子任务;2) 保证软路由能够学习到合理的策略选择策略。具体的损失函数可能包括策略模块的奖励函数、软路由的交叉熵损失等。策略模块可以使用各种强化学习算法进行训练,例如PPO、DDPG等。
🖼️ 关键图片

📊 实验亮点
该方法在模拟篮球环境中进行了评估,实验结果表明,该方法能够有效地控制模拟角色完成一系列基本篮球技能和具有挑战性的过渡动作。与传统的技能链方法相比,该方法能够实现更平滑和自然的过渡,并且能够更好地适应用户的实时指令。实验结果还表明,该方法不需要依赖球的轨迹参考,可以直接从原始状态空间学习控制策略。
🎯 应用场景
该研究成果可应用于游戏AI、虚拟角色控制、机器人运动规划等领域。例如,可以用于开发更智能的篮球游戏AI,使其能够执行更复杂的篮球动作和战术。此外,该方法还可以应用于其他需要复杂技能组合的机器人任务,例如家庭服务机器人、工业机器人等。未来,该技术有望实现更自然、流畅的人机交互。
📄 摘要(原文)
Learning a control policy for a multi-phase, long-horizon task, such as basketball maneuvers, remains challenging for reinforcement learning approaches due to the need for seamless policy composition and transitions between skills. A long-horizon task typically consists of distinct subtasks with well-defined goals, separated by transitional subtasks with unclear goals but critical to the success of the entire task. Existing methods like the mixture of experts and skill chaining struggle with tasks where individual policies do not share significant commonly explored states or lack well-defined initial and terminal states between different phases. In this paper, we introduce a novel policy integration framework to enable the composition of drastically different motor skills in multi-phase long-horizon tasks with ill-defined intermediate states. Based on that, we further introduce a high-level soft router to enable seamless and robust transitions between the subtasks. We evaluate our framework on a set of fundamental basketball skills and challenging transitions. Policies trained by our approach can effectively control the simulated character to interact with the ball and accomplish the long-horizon task specified by real-time user commands, without relying on ball trajectory references.