MoAngelo: Motion-Aware Neural Surface Reconstruction for Dynamic Scenes
作者: Mohamed Ebbed, Zorah Lähner
分类: cs.GR, cs.AI, cs.CV
发布日期: 2025-09-19
💡 一句话要点
MoAngelo:用于动态场景的运动感知神经表面重建
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 动态场景重建 神经表面重建 变形场 NeuralAngelo 多视角视频 三维重建 几何保真度 模板变形
📋 核心要点
- 动态场景重建面临计算和表示上的挑战,现有方法提取的网格质量不高,难以兼顾几何细节。
- 该论文提出了一种基于模板的动态重建框架,通过优化变形场来跟踪和细化初始帧的高质量静态重建结果。
- 实验表明,该方法在ActorsHQ数据集上实现了比现有技术更高的重建精度,尤其是在几何细节方面。
📝 摘要(中文)
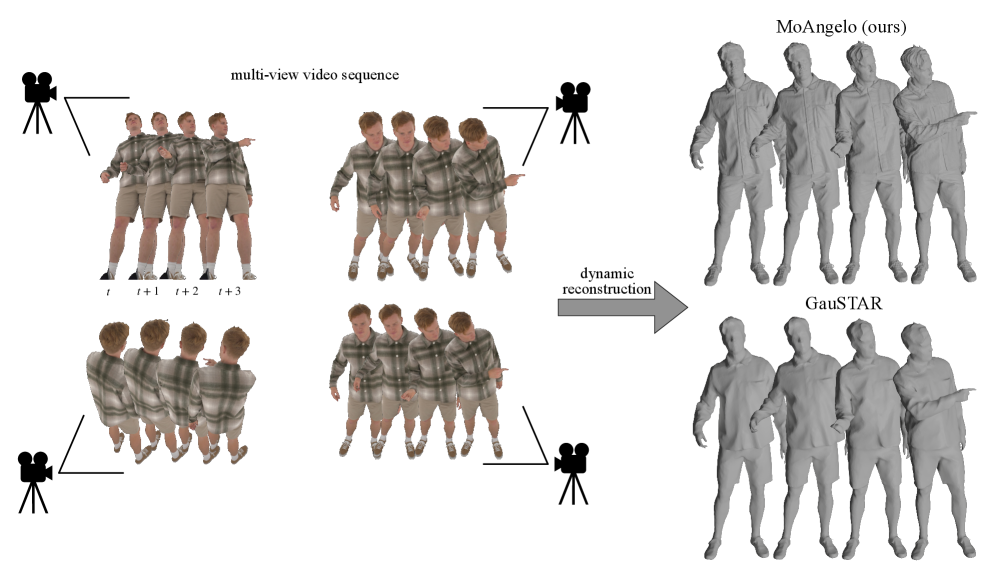
从多视角视频中重建动态场景是计算机视觉领域的一个根本性挑战。虽然最近的神经表面重建方法在静态3D重建中取得了显著成果,但将这些方法扩展到动态场景并保持相当的质量,会带来巨大的计算和表示挑战。现有的动态方法侧重于新视角合成,因此,它们提取的网格往往存在噪声。即使是旨在实现几何保真度的方法,由于问题的不适定性,也经常导致过于平滑的网格。我们提出了一个用于高细节动态重建的新框架,该框架扩展了静态3D重建方法NeuralAngelo以适应动态环境。为此,我们首先使用NeuralAngelo从初始帧进行高质量的模板场景重建,然后联合优化变形场,以跟踪模板并根据时间序列对其进行细化。这种灵活的模板允许更新几何体,以包括无法用变形场建模的变化,例如遮挡部分或拓扑结构的变化。我们在ActorsHQ数据集上展示了与先前最先进方法相比更优越的重建精度。
🔬 方法详解
问题定义:论文旨在解决动态场景下高质量三维表面重建的问题。现有方法,特别是那些侧重于新视角合成的方法,在动态场景中重建的网格往往存在噪声,几何细节不足,难以达到静态场景重建的精度。即使是追求几何保真度的方法,也容易产生过于平滑的结果,无法捕捉到动态场景中的复杂形变和拓扑变化。
核心思路:论文的核心思路是利用一个高质量的静态重建结果作为模板,然后通过优化变形场来跟踪和细化这个模板,使其适应动态场景中的变化。这种方法避免了直接从动态数据中重建网格的困难,而是将问题转化为一个变形问题,从而更容易获得高质量的结果。同时,允许对模板进行更新,以适应变形场无法建模的变化,如拓扑结构改变。
技术框架:该方法首先使用NeuralAngelo从初始帧重建一个高质量的静态模板。然后,对于后续的每一帧,该方法都会优化一个变形场,将模板变形到当前帧。这个变形场是通过最小化一个损失函数来学习的,该损失函数包括一个数据项(确保变形后的模板与当前帧的观测一致)和一个正则化项(确保变形场的光滑性)。此外,该方法还允许在必要时更新模板,以适应变形场无法建模的变化。
关键创新:该方法最重要的创新点在于将动态场景重建问题转化为一个基于模板的变形问题。这种方法避免了直接从动态数据中重建网格的困难,从而更容易获得高质量的结果。此外,该方法还允许在必要时更新模板,以适应变形场无法建模的变化,从而提高了方法的鲁棒性。
关键设计:该方法使用NeuralAngelo作为静态重建的基线方法,保证了初始模板的质量。变形场的优化使用了LBFGS优化器,损失函数包括光度一致性损失和几何一致性损失,以保证重建的准确性和几何细节。模板更新的策略是基于重建误差的,当重建误差超过一个阈值时,就会对模板进行更新。
🖼️ 关键图片


📊 实验亮点
该论文在ActorsHQ数据集上进行了实验,结果表明,该方法在重建精度方面优于现有的最先进方法。尤其是在几何细节方面,该方法能够重建出更精细的表面结构。定量结果表明,该方法在Chamfer Distance和Normal Consistency等指标上均取得了显著提升。
🎯 应用场景
该研究成果可应用于虚拟现实、增强现实、电影特效、游戏开发等领域。高质量的动态场景重建能够为这些应用提供更逼真、更沉浸式的体验。例如,在虚拟现实中,用户可以与动态场景进行交互;在电影特效中,可以创建更逼真的角色动画。
📄 摘要(原文)
Dynamic scene reconstruction from multi-view videos remains a fundamental challenge in computer vision. While recent neural surface reconstruction methods have achieved remarkable results in static 3D reconstruction, extending these approaches with comparable quality for dynamic scenes introduces significant computational and representational challenges. Existing dynamic methods focus on novel-view synthesis, therefore, their extracted meshes tend to be noisy. Even approaches aiming for geometric fidelity often result in too smooth meshes due to the ill-posedness of the problem. We present a novel framework for highly detailed dynamic reconstruction that extends the static 3D reconstruction method NeuralAngelo to work in dynamic settings. To that end, we start with a high-quality template scene reconstruction from the initial frame using NeuralAngelo, and then jointly optimize deformation fields that track the template and refine it based on the temporal sequence. This flexible template allows updating the geometry to include changes that cannot be modeled with the deformation field, for instance occluded parts or the changes in the topology. We show superior reconstruction accuracy in comparison to previous state-of-the-art methods on the ActorsHQ dataset.