ContraGS: Codebook-Condensed and Trainable Gaussian Splatting for Fast, Memory-Efficient Reconstruction
作者: Sankeerth Durvasula, Sharanshangar Muhunthan, Zain Moustafa, Richard Chen, Ruofan Liang, Yushi Guan, Nilesh Ahuja, Nilesh Jain, Selvakumar Panneer, Nandita Vijaykumar
分类: cs.GR, cs.CV
发布日期: 2025-09-03
💡 一句话要点
ContraGS:提出基于码本压缩和可训练高斯溅射方法,实现快速、内存高效的3D重建。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D高斯溅射 码本压缩 贝叶斯推断 MCMC采样 内存优化
📋 核心要点
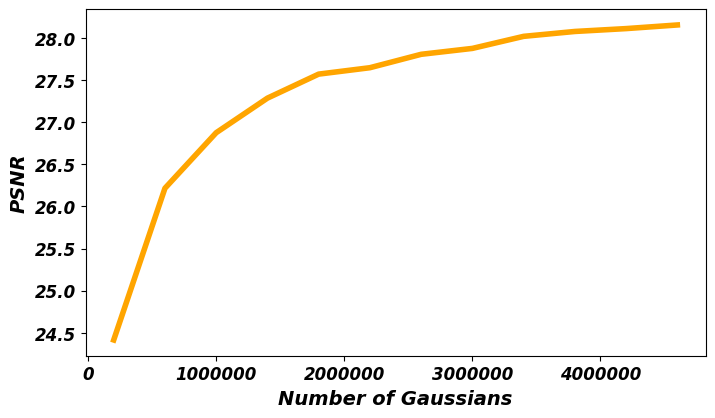
- 现有3D高斯溅射方法在高质量重建时需要大量高斯函数,导致GPU内存消耗巨大,训练和渲染速度慢。
- ContraGS通过引入码本压缩高斯参数,并在压缩域上直接训练,有效降低内存占用,同时保持模型质量。
- 实验表明,ContraGS显著降低了训练时的峰值内存,并加速了训练和渲染过程,同时保持了接近SOTA的重建质量。
📝 摘要(中文)
3D高斯溅射(3DGS)是一种先进的技术,用于高质量和实时渲染地建模真实场景。通常,可以通过使用大量的3D高斯函数来实现更高质量的表示。然而,使用大量的3D高斯函数会显著增加GPU设备内存,用于存储模型参数。因此,大型模型需要具有高内存容量的强大GPU进行训练,并且由于内存访问和数据移动的低效率,训练/渲染延迟会更慢。在这项工作中,我们介绍了ContraGS,一种可以直接在压缩的3DGS表示上进行训练的方法,而无需减少高斯计数,从而在模型质量上几乎没有损失。ContraGS利用码本在整个训练过程中紧凑地存储一组高斯参数向量,从而显著减少内存消耗。虽然码本已被证明在压缩完全训练的3DGS模型方面非常有效,但直接使用码本表示进行训练是一个尚未解决的挑战。ContraGS通过将参数估计表示为贝叶斯推断问题,解决了码本压缩表示中学习不可微参数的问题。为此,ContraGS提供了一个框架,该框架有效地使用MCMC采样来对这些压缩表示的后验分布进行采样。通过ContraGS,我们证明了ContraGS显著降低了训练期间的峰值内存(平均3.49倍),并加速了训练和渲染(平均分别为1.36倍和1.88倍),同时重新训练接近最先进的质量。
🔬 方法详解
问题定义:现有3D高斯溅射方法在追求高质量重建时,需要使用大量的高斯函数,这导致模型参数量巨大,显著增加了GPU内存的消耗。同时,由于需要频繁地访问和移动大量数据,训练和渲染的速度也受到限制。因此,如何在不降低模型质量的前提下,降低内存占用,加速训练和渲染,是当前3D高斯溅射方法面临的一个重要挑战。
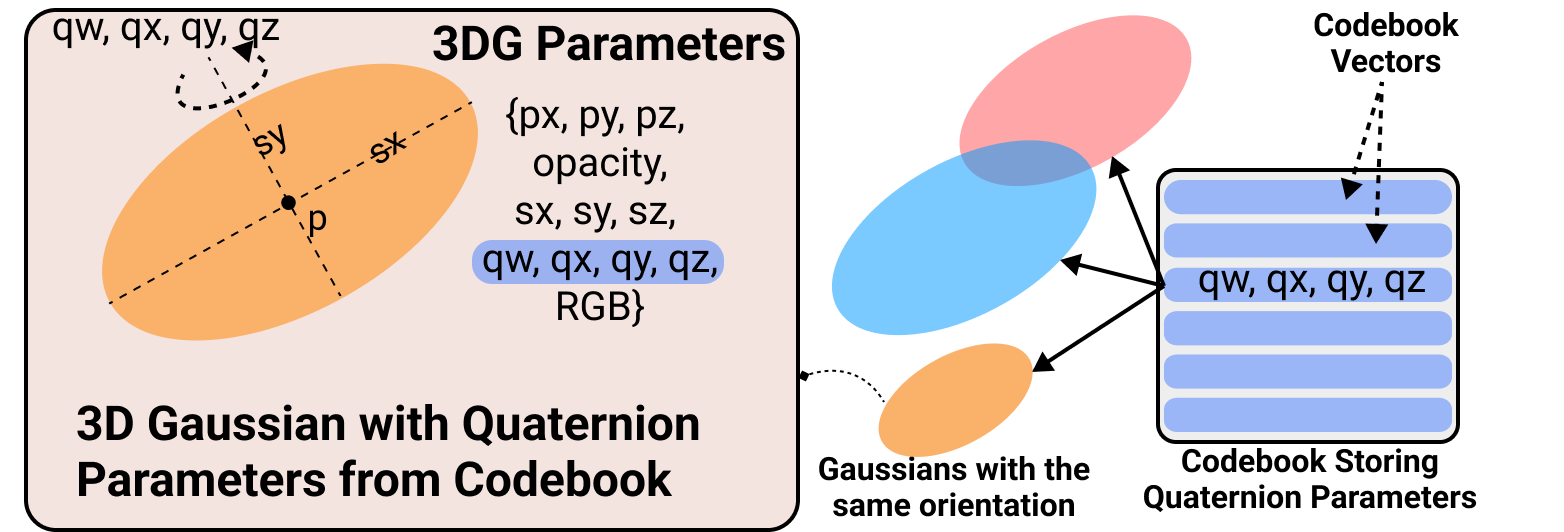
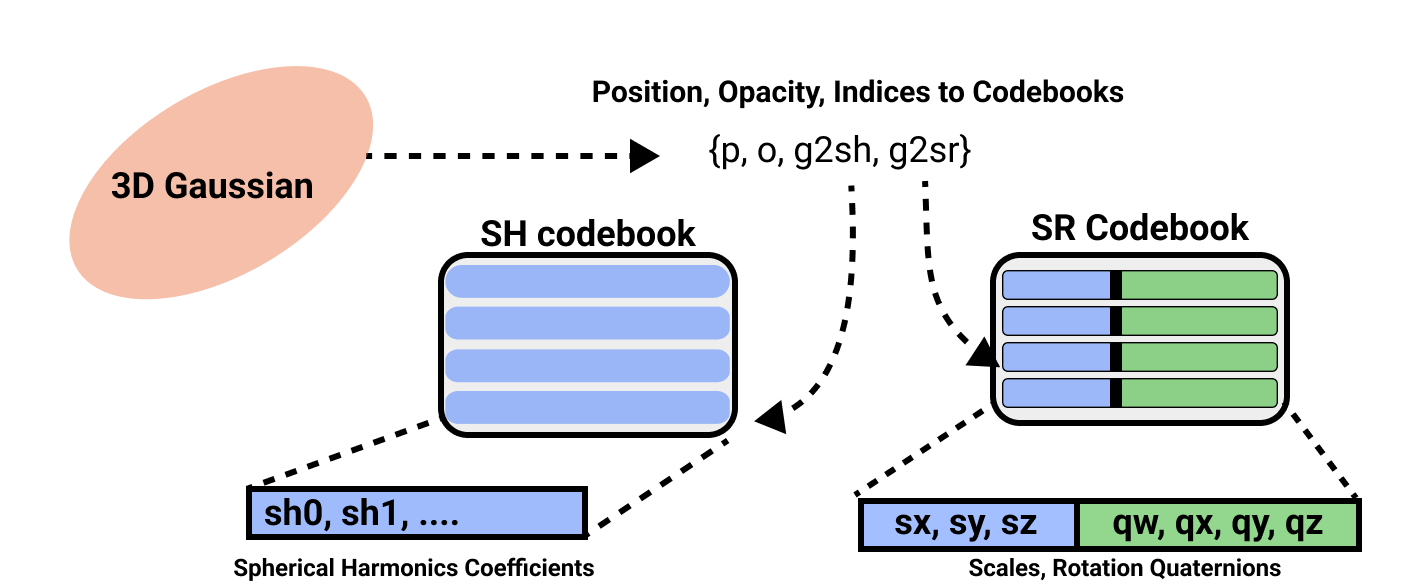
核心思路:ContraGS的核心思路是在训练过程中,使用码本对高斯参数进行压缩。具体来说,将高斯参数向量量化到码本中的码字,从而用码字的索引来表示高斯参数。这样,只需要存储码本和每个高斯函数的码字索引,就可以大大降低内存占用。同时,ContraGS提出了一种基于贝叶斯推断的方法,来解决在码本压缩表示上直接训练的问题。
技术框架:ContraGS的整体框架包括以下几个主要步骤:1. 初始化:初始化一组3D高斯函数,并为每个高斯函数分配一个码字索引。2. 前向传播:根据当前的高斯参数和码本,渲染图像。3. 损失计算:计算渲染图像与真实图像之间的损失。4. 参数更新:使用MCMC采样,对码本和高斯参数进行更新。具体来说,将参数估计问题建模为一个贝叶斯推断问题,并使用MCMC采样来对参数的后验分布进行采样。
关键创新:ContraGS最重要的技术创新点在于,它提出了一种在码本压缩表示上直接训练3D高斯溅射模型的方法。与传统的先训练再压缩的方法不同,ContraGS可以在训练过程中就对模型进行压缩,从而大大降低内存占用,并加速训练和渲染。此外,ContraGS还提出了一种基于贝叶斯推断的方法,来解决在码本压缩表示上直接训练的问题。
关键设计:ContraGS的关键设计包括:1. 码本的设计:码本的大小和码字的初始化方式会影响模型的性能。论文中使用了K-means聚类算法来初始化码本。2. MCMC采样:MCMC采样的步长和采样次数会影响模型的收敛速度和最终性能。论文中使用了Metropolis-Hastings算法进行采样。3. 损失函数:论文中使用了L1损失和SSIM损失的组合,来衡量渲染图像与真实图像之间的差异。
🖼️ 关键图片
📊 实验亮点
ContraGS在多个数据集上进行了实验,结果表明,ContraGS可以在显著降低内存占用的同时,保持接近SOTA的重建质量。具体来说,ContraGS平均降低了3.49倍的峰值内存,并加速了1.36倍的训练速度和1.88倍的渲染速度。
🎯 应用场景
ContraGS具有广泛的应用前景,例如在移动设备上进行高质量的3D重建和渲染,或者在资源受限的环境中进行大规模的场景建模。该技术可以应用于自动驾驶、增强现实、虚拟现实、游戏开发等领域,具有重要的实际价值和未来影响。
📄 摘要(原文)
3D Gaussian Splatting (3DGS) is a state-of-art technique to model real-world scenes with high quality and real-time rendering. Typically, a higher quality representation can be achieved by using a large number of 3D Gaussians. However, using large 3D Gaussian counts significantly increases the GPU device memory for storing model parameters. A large model thus requires powerful GPUs with high memory capacities for training and has slower training/rendering latencies due to the inefficiencies of memory access and data movement. In this work, we introduce ContraGS, a method to enable training directly on compressed 3DGS representations without reducing the Gaussian Counts, and thus with a little loss in model quality. ContraGS leverages codebooks to compactly store a set of Gaussian parameter vectors throughout the training process, thereby significantly reducing memory consumption. While codebooks have been demonstrated to be highly effective at compressing fully trained 3DGS models, directly training using codebook representations is an unsolved challenge. ContraGS solves the problem of learning non-differentiable parameters in codebook-compressed representations by posing parameter estimation as a Bayesian inference problem. To this end, ContraGS provides a framework that effectively uses MCMC sampling to sample over a posterior distribution of these compressed representations. With ContraGS, we demonstrate that ContraGS significantly reduces the peak memory during training (on average 3.49X) and accelerated training and rendering (1.36X and 1.88X on average, respectively), while retraining close to state-of-art quality.