GRMM: Real-Time High-Fidelity Gaussian Morphable Head Model with Learned Residuals
作者: Mohit Mendiratta, Mayur Deshmukh, Kartik Teotia, Vladislav Golyanik, Adam Kortylewski, Christian Theobalt
分类: cs.GR, cs.CV
发布日期: 2025-09-02
备注: Project page: https://mohitm1994.github.io/GRMM/
💡 一句话要点
提出GRMM以解决传统3DMM在细节与实时性上的不足
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 高斯可变形模型 面部表情识别 实时渲染 细节捕捉 虚拟现实 增强现实 深度学习
📋 核心要点
- 传统的3D可变形模型在细节和真实感方面存在显著不足,限制了其在实际应用中的效果。
- GRMM通过引入残差几何和外观组件,增强基础3DMM的能力,能够捕捉更细致的面部特征和表情变化。
- 实验结果表明,GRMM在单目3D人脸重建和表情转移任务中超越了现有方法,达到了75 FPS的实时渲染性能。
📝 摘要(中文)
3D可变形模型(3DMM)使得面部几何和表情编辑可控,广泛应用于重建、动画和增强现实/虚拟现实。然而,传统的基于主成分分析(PCA)的网格模型在分辨率、细节和真实感方面存在局限。虽然神经体积方法提高了真实感,但仍然过于缓慢,无法实现交互式使用。近期的高斯点云(3DGS)面部模型实现了快速高质量渲染,但仍然依赖于网格基础的3DMM先验进行表情控制,限制了其捕捉细微几何、表情和全头覆盖的能力。我们提出了GRMM,这是第一个完整的高斯3D可变形模型,通过残差几何和外观组件增强基础3DMM,恢复高频细节,如皱纹、细腻的皮肤纹理和发际线变化。GRMM通过低维可解释参数提供解耦控制,同时单独建模捕捉超出基础模型能力的细节的残差。粗解码器产生顶点级网格变形,细解码器表示每个高斯的外观,轻量级CNN优化光栅化图像以增强真实感,同时保持75 FPS的实时渲染。为了学习一致的高保真残差,我们提出了EXPRESS-50,这是第一个包含50个身份的60个对齐表情的数据集,能够在基于高斯的3DMM中实现身份和表情的稳健解耦。在单目3D人脸重建、新视角合成和表情转移中,GRMM在真实感和表情准确性上超越了现有最先进的方法,同时提供交互式实时性能。
🔬 方法详解
问题定义:本论文旨在解决传统3D可变形模型在细节、真实感和实时性方面的不足。现有方法如PCA基模型和神经体积方法在交互式应用中表现不佳,无法有效捕捉细微的面部特征和表情变化。
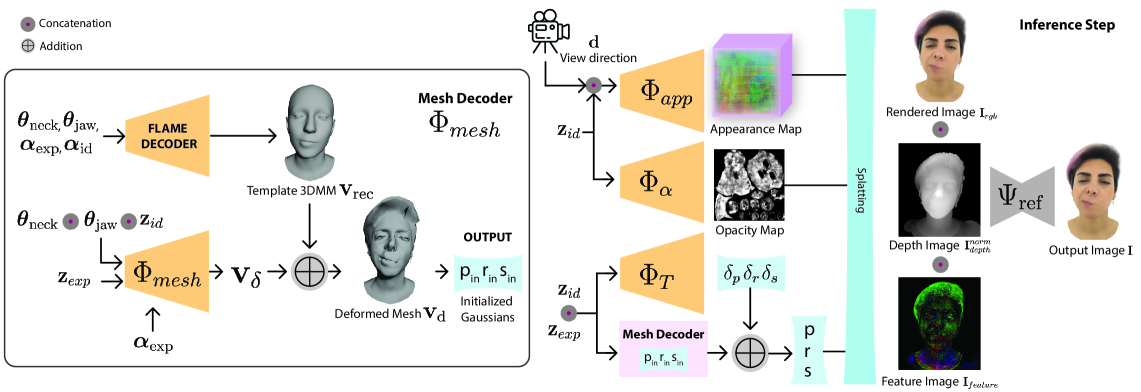
核心思路:GRMM的核心思路是通过引入残差几何和外观组件来增强基础3DMM的能力。这种设计使得模型能够在保持低维可解释参数的同时,捕捉超出基础模型能力的细节。
技术框架:GRMM的整体架构包括粗解码器、细解码器和轻量级CNN。粗解码器负责生成顶点级网格变形,细解码器则表示每个高斯的外观,最后通过CNN优化光栅化图像以提升真实感。
关键创新:GRMM的主要创新在于首次实现了完整的高斯3D可变形模型,能够通过残差建模捕捉细节,显著提升了面部表情的表现力和真实感。与传统方法相比,GRMM在细节捕捉和实时渲染能力上有本质区别。
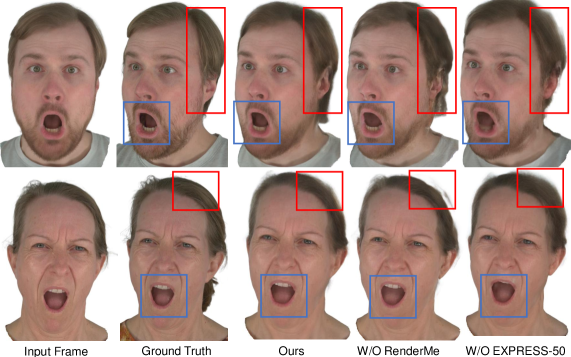
关键设计:在模型设计中,使用了EXPRESS-50数据集,该数据集包含60个对齐表情和50个身份,支持高保真残差的学习。此外,模型采用了轻量级CNN结构,以确保在保持高质量渲染的同时实现75 FPS的实时性能。
🖼️ 关键图片

📊 实验亮点
实验结果显示,GRMM在单目3D人脸重建、新视角合成和表情转移任务中均超越了现有最先进的方法,特别是在真实感和表情准确性方面,表现出显著的提升。具体而言,GRMM在这些任务中实现了75 FPS的实时渲染,确保了交互体验的流畅性。
🎯 应用场景
GRMM在虚拟现实、增强现实和动画制作等领域具有广泛的应用潜力。其高保真度和实时渲染能力使得面部表情的交互式编辑成为可能,能够为用户提供更加沉浸和真实的体验。未来,GRMM还可以扩展到游戏开发、电影特效以及社交媒体中的虚拟角色创建等多个场景。
📄 摘要(原文)
3D Morphable Models (3DMMs) enable controllable facial geometry and expression editing for reconstruction, animation, and AR/VR, but traditional PCA-based mesh models are limited in resolution, detail, and photorealism. Neural volumetric methods improve realism but remain too slow for interactive use. Recent Gaussian Splatting (3DGS) based facial models achieve fast, high-quality rendering but still depend solely on a mesh-based 3DMM prior for expression control, limiting their ability to capture fine-grained geometry, expressions, and full-head coverage. We introduce GRMM, the first full-head Gaussian 3D morphable model that augments a base 3DMM with residual geometry and appearance components, additive refinements that recover high-frequency details such as wrinkles, fine skin texture, and hairline variations. GRMM provides disentangled control through low-dimensional, interpretable parameters (e.g., identity shape, facial expressions) while separately modelling residuals that capture subject- and expression-specific detail beyond the base model's capacity. Coarse decoders produce vertex-level mesh deformations, fine decoders represent per-Gaussian appearance, and a lightweight CNN refines rasterised images for enhanced realism, all while maintaining 75 FPS real-time rendering. To learn consistent, high-fidelity residuals, we present EXPRESS-50, the first dataset with 60 aligned expressions across 50 identities, enabling robust disentanglement of identity and expression in Gaussian-based 3DMMs. Across monocular 3D face reconstruction, novel-view synthesis, and expression transfer, GRMM surpasses state-of-the-art methods in fidelity and expression accuracy while delivering interactive real-time performance.