Controllable Video Generation: A Survey
作者: Yue Ma, Kunyu Feng, Zhongyuan Hu, Xinyu Wang, Yucheng Wang, Mingzhe Zheng, Xuanhua He, Chenyang Zhu, Hongyu Liu, Yingqing He, Zeyu Wang, Zhifeng Li, Xiu Li, Wei Liu, Dan Xu, Linfeng Zhang, Qifeng Chen
分类: cs.GR, cs.CV
发布日期: 2025-07-22 (更新: 2026-01-16)
备注: project page: https://github.com/mayuelala/Awesome-Controllable-Video-Generation
🔗 代码/项目: GITHUB
💡 一句话要点
综述可控视频生成技术,提升用户意图在AIGC视频生成中的表达精度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 可控视频生成 视频扩散模型 AIGC 条件生成 多模态控制
📋 核心要点
- 现有文本到视频生成模型难以满足用户对视频内容进行精细控制的需求,文本提示不足以表达复杂意图。
- 通过整合相机运动、深度图、人体姿势等非文本条件,扩展预训练视频生成模型,实现更精确的可控视频合成。
- 该综述系统回顾了可控视频生成领域的理论基础和最新进展,并对现有方法进行了分类和分析。
📝 摘要(中文)
随着AI生成内容(AIGC)的快速发展,视频生成已成为最具活力和影响力的子领域之一。特别是,视频生成基础模型的进步导致对可控视频生成方法的需求不断增长,这些方法能够更准确地反映用户意图。现有的大多数基础模型都是为文本到视频生成而设计的,但仅靠文本提示通常不足以表达复杂、多模态和细粒度的用户需求。这一限制使得用户难以使用当前模型生成具有精确控制的视频。为了解决这个问题,最近的研究探索了整合额外的非文本条件,如相机运动、深度图和人体姿势,以扩展预训练的视频生成模型,并实现更可控的视频合成。这些方法旨在提高AIGC驱动的视频生成系统的灵活性和实际应用性。在本综述中,我们系统地回顾了可控视频生成,涵盖了该领域的理论基础和最新进展。我们首先介绍关键概念和常用的开源视频生成模型。然后,我们重点关注视频扩散模型中的控制机制,分析如何将不同类型的条件纳入去噪过程以指导生成。最后,我们根据它们利用的控制信号类型对现有方法进行分类,包括单条件生成、多条件生成和通用可控生成。
🔬 方法详解
问题定义:当前文本到视频的生成模型,仅仅依赖文本提示,无法满足用户对于视频内容进行精细化控制的需求。用户难以通过简单的文本描述来表达复杂的、多模态的意图,例如精确控制人物的动作、场景的深度信息或者相机的运动轨迹。现有方法的痛点在于缺乏有效的控制机制,使得生成结果与用户期望之间存在差距。
核心思路:核心思路在于将非文本的控制信号(如相机运动、深度图、人体姿势等)融入到视频生成过程中,从而实现对生成视频内容更精确的控制。通过引入这些额外的条件,模型可以更好地理解用户的意图,并生成符合用户期望的视频内容。这种方法的核心在于如何有效地将这些控制信号整合到现有的视频生成模型中。
技术框架:该综述主要关注基于扩散模型的视频生成框架。整体流程通常包括:1)条件编码:将输入的控制信号(如文本、图像、姿势等)编码成模型可以理解的特征向量;2)扩散过程:对初始噪声图像逐步添加噪声,直到完全变成随机噪声;3)去噪过程:通过神经网络逐步去除噪声,并根据条件编码来引导生成过程,最终生成符合条件的视频。不同的控制信号可以通过不同的方式融入到去噪过程中,例如通过交叉注意力机制、条件归一化等。
关键创新:关键创新在于如何有效地将各种控制信号融入到视频扩散模型中,并实现对生成过程的精确控制。与传统的文本到视频生成方法相比,该方法能够利用更多的信息来指导生成过程,从而生成更符合用户意图的视频。此外,通用可控生成方法旨在设计一个统一的框架,能够处理多种类型的控制信号,从而提高模型的灵活性和泛化能力。
关键设计:关键设计包括:1)条件编码器的设计,如何有效地将不同类型的控制信号编码成模型可以理解的特征向量;2)去噪网络的设计,如何将条件编码融入到去噪过程中,并引导生成过程;3)损失函数的设计,如何衡量生成视频与控制信号之间的差异,并优化模型。
🖼️ 关键图片
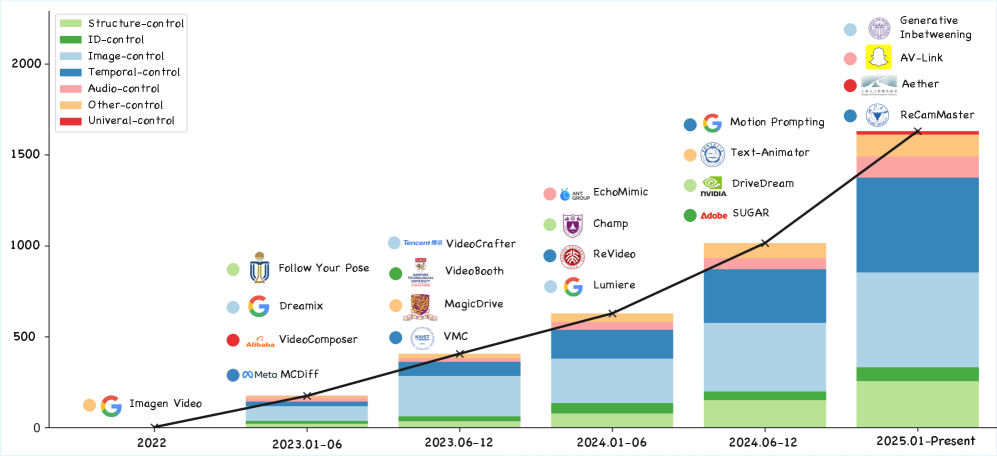
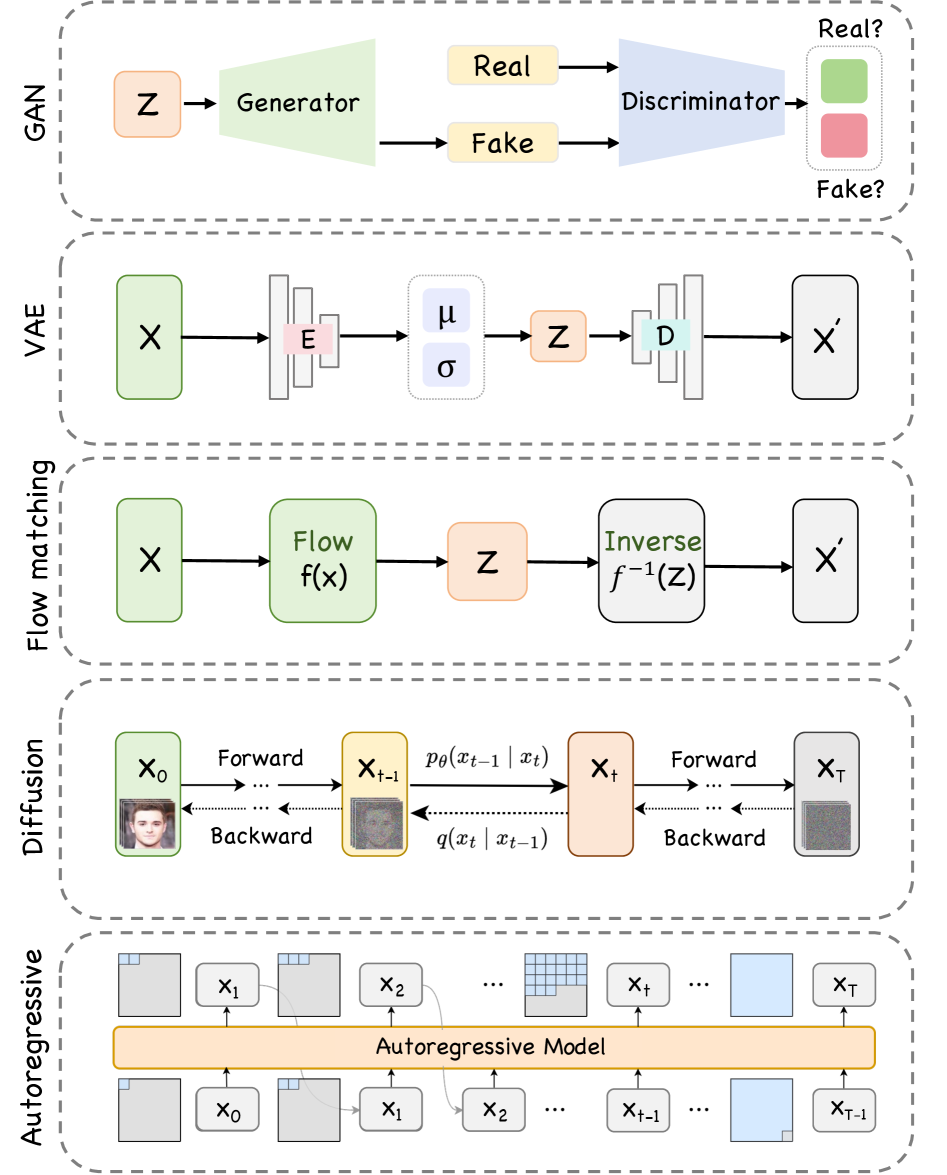
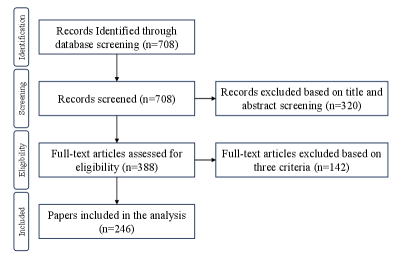
📊 实验亮点
该综述系统地回顾了可控视频生成领域的最新进展,并对现有方法进行了分类和分析。论文整理了大量相关文献,并提供了一个开源的代码仓库,方便研究人员快速了解和掌握该领域的技术。通过对不同控制信号的分析,论文为未来的研究方向提供了有益的启示,例如如何设计更有效的控制机制,如何处理多模态的控制信号,以及如何提高生成视频的质量和真实感。
🎯 应用场景
可控视频生成技术在游戏开发、电影制作、广告设计、教育培训等领域具有广泛的应用前景。例如,游戏开发者可以使用该技术快速生成各种游戏场景和角色动画;电影制作人员可以利用该技术制作特效镜头和虚拟场景;广告设计师可以根据客户的需求定制个性化的广告视频。该技术还可以用于创建虚拟现实和增强现实体验,以及开发智能化的视频编辑工具。
📄 摘要(原文)
With the rapid development of AI-generated content (AIGC), video generation has emerged as one of its most dynamic and impactful subfields. In particular, the advancement of video generation foundation models has led to growing demand for controllable video generation methods that can more accurately reflect user intent. Most existing foundation models are designed for text-to-video generation, where text prompts alone are often insufficient to express complex, multi-modal, and fine-grained user requirements. This limitation makes it challenging for users to generate videos with precise control using current models. To address this issue, recent research has explored the integration of additional non-textual conditions, such as camera motion, depth maps, and human pose, to extend pretrained video generation models and enable more controllable video synthesis. These approaches aim to enhance the flexibility and practical applicability of AIGC-driven video generation systems. In this survey, we provide a systematic review of controllable video generation, covering both theoretical foundations and recent advances in the field. We begin by introducing the key concepts and commonly used open-source video generation models. We then focus on control mechanisms in video diffusion models, analyzing how different types of conditions can be incorporated into the denoising process to guide generation. Finally, we categorize existing methods based on the types of control signals they leverage, including single-condition generation, multi-condition generation, and universal controllable generation. For a complete list of the literature on controllable video generation reviewed, please visit our curated repository at https://github.com/mayuelala/Awesome-Controllable-Video-Generation.