Dream, Lift, Animate: From Single Images to Animatable Gaussian Avatars
作者: Marcel C. Bühler, Ye Yuan, Xueting Li, Yangyi Huang, Koki Nagano, Umar Iqbal
分类: cs.GR, cs.AI
发布日期: 2025-07-21 (更新: 2025-11-17)
备注: Accepted to 3DV 2026
💡 一句话要点
DLA:从单张图像生成可动画的高斯人像,实现高质量的3D重建与动画
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting)
关键词: 3D人体重建 可动画人像 高斯体 视频扩散模型 UV空间映射
📋 核心要点
- 现有方法难以仅从单张图像重建高质量、可动画的3D人体化身,尤其是在几何细节和动画一致性方面。
- DLA利用视频扩散模型生成多视角图像,并将其提升为3D高斯体,再通过UV空间映射实现姿态感知动画。
- 实验表明,DLA在ActorsHQ和4D-Dress数据集上,在感知质量和光度精度方面均超越了现有技术水平。
📝 摘要(中文)
本文提出了一种名为Dream, Lift, Animate (DLA) 的新框架,该框架仅从单张图像重建可动画的3D人体化身。DLA通过利用多视角生成、3D高斯提升以及3D高斯体的姿态感知UV空间映射来实现这一目标。给定一张图像,我们首先使用视频扩散模型生成合理的多视角图像,捕捉丰富的几何和外观细节。然后,这些视角被提升为非结构化的3D高斯体。为了实现动画,我们提出了一个基于Transformer的编码器,该编码器对全局空间关系进行建模,并将这些高斯体投影到与参数化人体模型的UV空间对齐的结构化潜在表示中。该潜在代码被解码为UV空间高斯体,这些高斯体可以通过身体驱动的变形进行动画,并根据姿势和视点进行渲染。通过将高斯体锚定到UV流形,我们的方法确保了动画期间的一致性,同时保留了精细的视觉细节。DLA支持实时渲染和直观编辑,无需后处理。在ActorsHQ和4D-Dress数据集上,我们的方法在感知质量和光度精度方面均优于最先进的方法。通过结合视频扩散模型的生成优势和姿态感知的UV空间高斯映射,DLA弥合了非结构化3D表示和高保真、可动画化身之间的差距。
🔬 方法详解
问题定义:现有方法在单视图3D人体重建中,难以生成高质量、可动画的模型。尤其是在纹理细节的保持和动画过程中的一致性方面存在挑战。此外,从非结构化的3D表示到可动画模型的转换过程也较为复杂。
核心思路:DLA的核心思路是结合视频扩散模型的生成能力和3D高斯体的表达能力,通过UV空间映射建立3D高斯体与人体姿态之间的联系,从而实现高质量、可动画的3D人体重建。通过多视角生成增强几何信息,UV空间映射保证动画一致性。
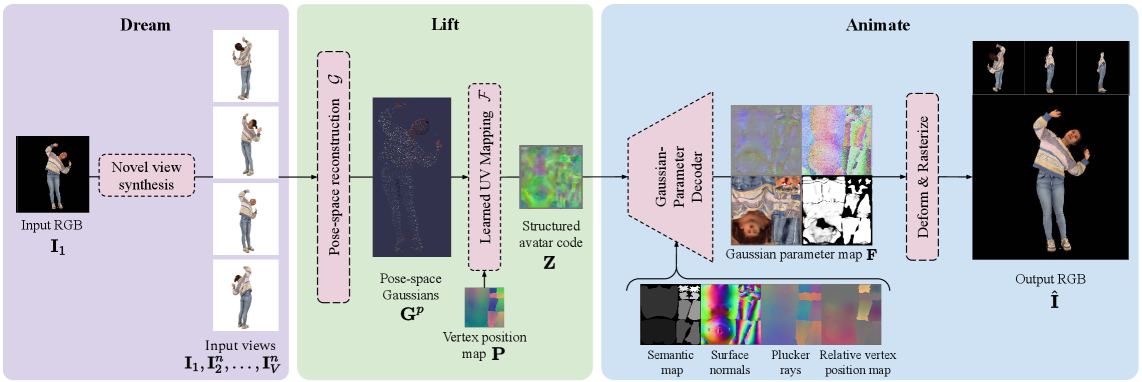
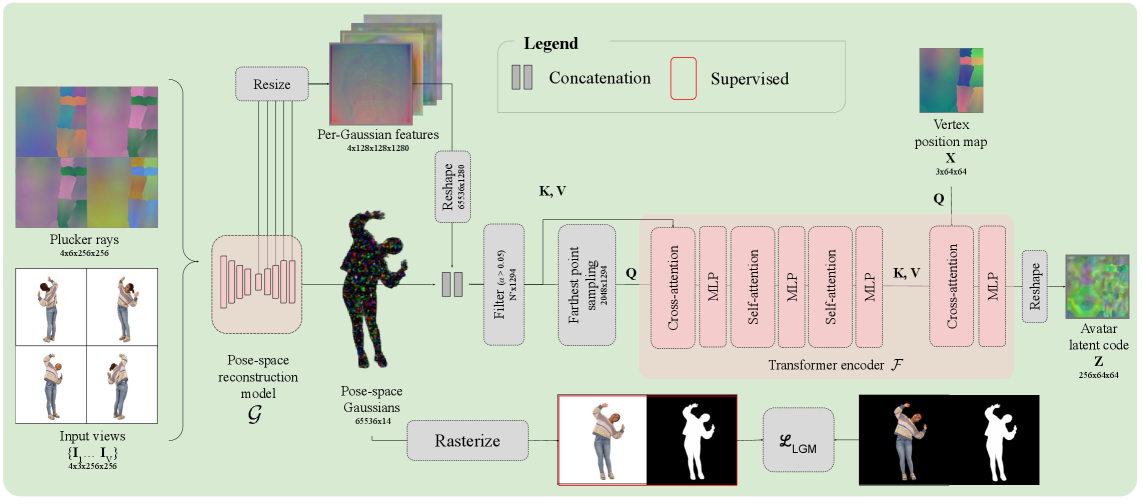
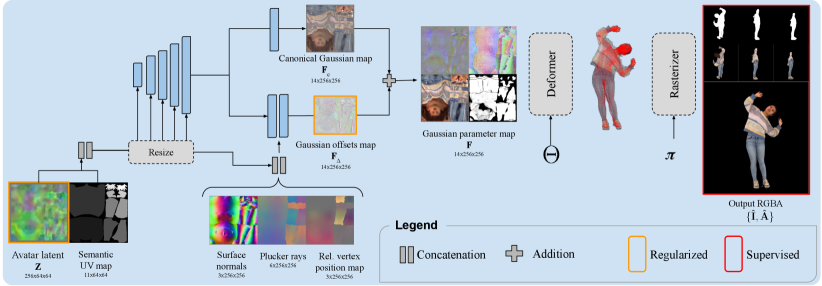
技术框架:DLA框架主要包含三个阶段:1) 多视角生成:使用视频扩散模型从单张图像生成多视角图像,以补充几何信息。2) 3D高斯提升:将生成的多视角图像提升为非结构化的3D高斯体。3) 姿态感知UV空间映射:使用Transformer编码器将3D高斯体投影到与参数化人体模型的UV空间对齐的潜在表示中,并解码为可动画的UV空间高斯体。
关键创新:DLA的关键创新在于姿态感知的UV空间高斯映射。通过将3D高斯体锚定到UV流形,DLA能够确保动画过程中的一致性,并保留精细的视觉细节。此外,使用Transformer编码器建模全局空间关系,提高了重建质量。
关键设计:DLA使用预训练的视频扩散模型进行多视角生成。Transformer编码器的具体结构未知,但其目标是学习3D高斯体与UV空间之间的映射关系。损失函数可能包含光度损失、几何损失以及正则化项,以保证重建质量和动画的平滑性。UV空间的参数化人体模型可能是SMPL或类似的模型。
🖼️ 关键图片
📊 实验亮点
DLA在ActorsHQ和4D-Dress数据集上取得了显著的性能提升。在感知质量和光度精度方面,DLA均优于现有技术水平。具体的数据指标和提升幅度未知,但摘要中明确指出DLA超越了state-of-the-art方法。
🎯 应用场景
DLA具有广泛的应用前景,包括虚拟现实、增强现实、游戏开发、电影制作等领域。它可以用于创建逼真的虚拟化身,用于社交互动、远程协作和个性化内容生成。此外,DLA还可以用于服装设计、虚拟试穿等应用,为用户提供更加个性化的体验。
📄 摘要(原文)
We introduce Dream, Lift, Animate (DLA), a novel framework that reconstructs animatable 3D human avatars from a single image. This is achieved by leveraging multi-view generation, 3D Gaussian lifting, and pose-aware UV-space mapping of 3D Gaussians. Given an image, we first dream plausible multi-views using a video diffusion model, capturing rich geometric and appearance details. These views are then lifted into unstructured 3D Gaussians. To enable animation, we propose a transformer-based encoder that models global spatial relationships and projects these Gaussians into a structured latent representation aligned with the UV space of a parametric body model. This latent code is decoded into UV-space Gaussians that can be animated via body-driven deformation and rendered conditioned on pose and viewpoint. By anchoring Gaussians to the UV manifold, our method ensures consistency during animation while preserving fine visual details. DLA enables real-time rendering and intuitive editing without requiring post-processing. Our method outperforms state-of-the-art approaches on the ActorsHQ and 4D-Dress datasets in both perceptual quality and photometric accuracy. By combining the generative strengths of video diffusion models with a pose-aware UV-space Gaussian mapping, DLA bridges the gap between unstructured 3D representations and high-fidelity, animation-ready avatars.