HairFormer: Transformer-Based Dynamic Neural Hair Simulation
作者: Joy Xiaoji Zhang, Jingsen Zhu, Hanyu Chen, Steve Marschner
分类: cs.GR, cs.CV
发布日期: 2025-07-16
💡 一句话要点
HairFormer:提出基于Transformer的动态神经头发模拟方法,实现广泛的风格泛化。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 头发模拟 动态模拟 Transformer 神经渲染 交叉注意力 物理信息损失 实时渲染
📋 核心要点
- 现有头发动态模拟方法难以在不同发型、体型和运动中泛化,导致通用性不足和穿透问题。
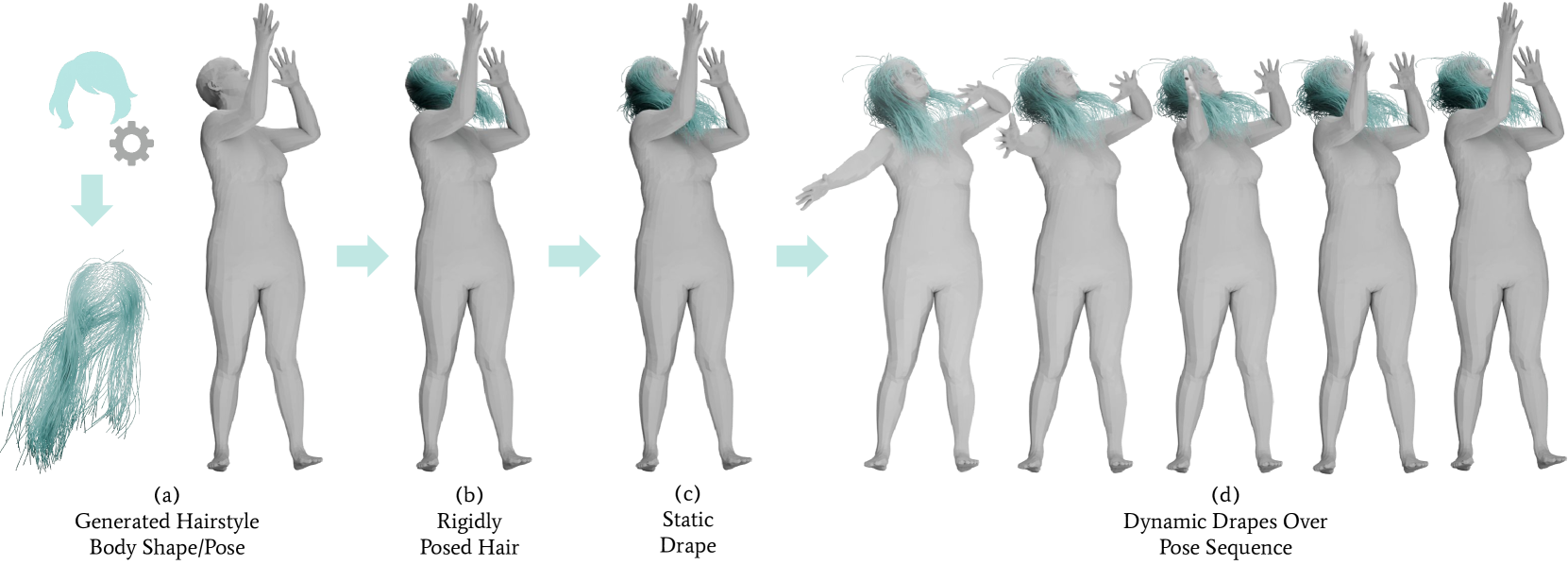
- HairFormer利用Transformer架构,首先预测静态悬垂形状,再结合动态网络生成逼真的头发动态效果和次级运动。
- 该方法实现了实时推理,并在各种发型上展示了高保真度和可泛化的动态头发效果,有效解决了穿透问题。
📝 摘要(中文)
本文提出了一种新颖的两阶段神经解决方案,首次利用基于Transformer的架构来实现对任意发型、体型和运动的广泛泛化,从而解决头发动态模拟这一关键挑战。首先,我们提出了一个基于Transformer的静态网络,用于预测任何发型的静态悬垂形状,有效地解决头发与身体的穿透问题并保持头发的逼真度。其次,一个具有新型交叉注意力机制的动态网络将静态头发特征与运动学输入融合,以生成富有表现力的动态效果和复杂的次级运动。该动态网络还允许对具有挑战性的运动序列(如突然的头部运动)进行高效的微调。我们的方法为静态单帧悬垂和姿势序列上的动态悬垂提供了实时推理。实验结果表明,我们的方法在各种风格中展示了高保真度和可泛化的动态头发效果,并通过物理信息损失进行指导,即使对于复杂、未见过的长发型也能解决穿透问题,突出了其广泛的泛化能力。
🔬 方法详解
问题定义:现有的头发动态模拟方法在处理不同发型、体型和运动时,泛化能力不足,难以保证模拟的真实性和避免头发与身体的穿透问题。尤其是在处理复杂发型和剧烈运动时,效果往往不尽如人意。
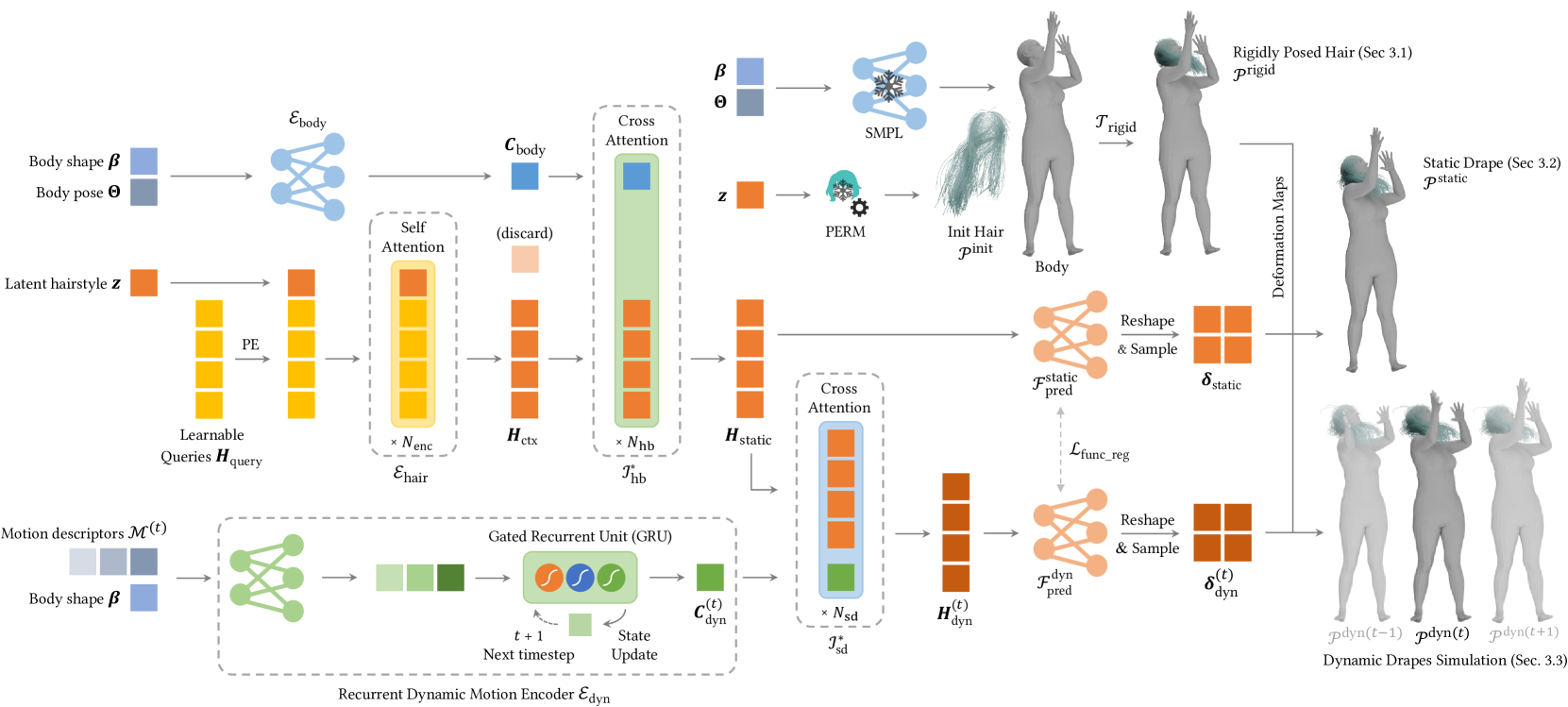
核心思路:HairFormer的核心思路是将头发动态模拟分解为两个阶段:静态悬垂预测和动态模拟。静态阶段使用Transformer网络预测头发的初始形状,解决穿透问题;动态阶段则利用交叉注意力机制融合静态特征和运动信息,生成逼真的动态效果。这种分阶段的方法能够有效解耦静态形状和动态变化,提高模拟的准确性和泛化能力。
技术框架:HairFormer包含两个主要模块:静态网络和动态网络。静态网络是一个基于Transformer的架构,输入是发型和身体形状,输出是静态的头发悬垂形状。动态网络则接收静态网络的输出以及运动学信息作为输入,通过交叉注意力机制融合这些信息,最终输出动态的头发形状序列。整个流程可以实现实时推理,并且支持对特定运动序列进行微调。
关键创新:HairFormer的关键创新在于将Transformer架构引入到头发动态模拟中,并设计了新型的交叉注意力机制。Transformer的自注意力机制能够捕捉头发不同部分之间的依赖关系,从而更好地预测静态形状。交叉注意力机制则能够有效地融合静态头发特征和运动学信息,生成逼真的动态效果。此外,两阶段的设计也使得模型能够更好地解耦静态形状和动态变化。
关键设计:静态网络使用标准的Transformer编码器结构,并采用物理信息损失函数来指导训练,确保预测的形状符合物理规律。动态网络则使用循环神经网络(RNN)作为主干,并引入交叉注意力机制来融合静态特征和运动信息。交叉注意力机制的关键在于学习静态特征和运动信息之间的相关性,从而生成更准确的动态效果。此外,该方法还允许对特定运动序列进行微调,以提高在复杂场景下的性能。
🖼️ 关键图片
📊 实验亮点
HairFormer在各种发型上展示了高保真度和可泛化的动态头发效果,尤其是在处理复杂、未见过的长发型时,能够有效解决穿透问题。该方法实现了实时推理,并且支持对特定运动序列进行微调,进一步提高了模拟的准确性和效率。实验结果表明,HairFormer在性能上优于现有的头发动态模拟方法。
🎯 应用场景
HairFormer具有广泛的应用前景,包括电影特效、游戏开发、虚拟现实和增强现实等领域。它可以用于创建逼真的虚拟角色,提升用户在虚拟环境中的沉浸感。此外,该方法还可以应用于服装设计和虚拟试穿等领域,帮助设计师更好地展示服装效果,并为用户提供更便捷的购物体验。未来,HairFormer有望成为数字内容创作的重要工具。
📄 摘要(原文)
Simulating hair dynamics that generalize across arbitrary hairstyles, body shapes, and motions is a critical challenge. Our novel two-stage neural solution is the first to leverage Transformer-based architectures for such a broad generalization. We propose a Transformer-powered static network that predicts static draped shapes for any hairstyle, effectively resolving hair-body penetrations and preserving hair fidelity. Subsequently, a dynamic network with a novel cross-attention mechanism fuses static hair features with kinematic input to generate expressive dynamics and complex secondary motions. This dynamic network also allows for efficient fine-tuning of challenging motion sequences, such as abrupt head movements. Our method offers real-time inference for both static single-frame drapes and dynamic drapes over pose sequences. Our method demonstrates high-fidelity and generalizable dynamic hair across various styles, guided by physics-informed losses, and can resolve penetrations even for complex, unseen long hairstyles, highlighting its broad generalization.