Collaborative Texture Filtering
作者: Tomas Akenine-Möller, Pontus Ebelin, Matt Pharr, Bartlomiej Wronski
分类: cs.GR, cs.CV
发布日期: 2025-06-21
备注: Accepted to ACM/EG Symposium on High Performance Graphics (HPG), 2025
DOI: 10.2312/hpg.20251174
💡 一句话要点
提出协同纹理过滤算法,利用GPU波通信优化纹理放大时的滤波质量和效率
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 纹理滤波 GPU波通信 纹理压缩 随机纹理滤波 协同计算
📋 核心要点
- 传统纹理压缩虽然压缩率高,但无法直接利用GPU纹理单元进行解压和滤波,导致随机纹理滤波(STF)的需求。
- 论文提出协同纹理滤波算法,利用GPU波通信在线程间共享纹素数据,避免重复解压,提升滤波效率。
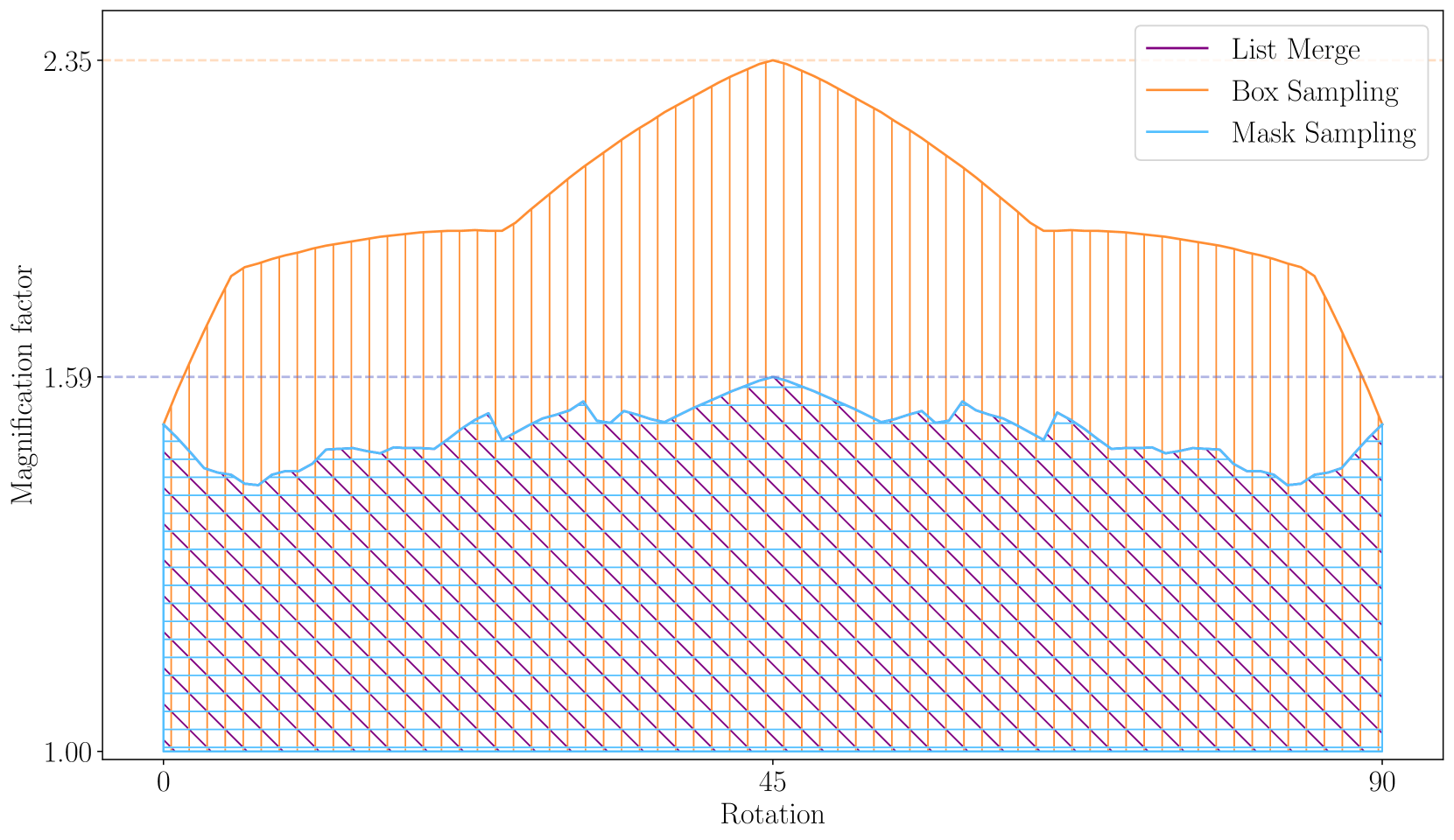
- 该方法在放大倍数足够大时,能实现每个像素小于等于1个纹素评估的零误差滤波,并提出了高质量的滤波回退方案。
📝 摘要(中文)
近年来,纹理压缩技术在压缩率上取得了显著进展,但无法利用GPU的纹理单元进行解压缩和滤波。这促使了随机纹理滤波(STF)技术的发展,以避免使用这些格式时多次纹素评估的高成本。然而,这些方法在放大时可能会产生不良的视觉外观变化,并且可能包含可见的噪声和闪烁,尽管使用了时空去噪器。最近的研究通过在附近像素之间共享解码后的纹素值(Wronski 2025),显著提高了STF的放大滤波质量。利用GPU波通信内在函数,这种共享可以在主动执行的着色器内部执行,而无需内存流量开销。我们进一步发展了这个想法,并提出了新的算法,该算法利用lane之间的波通信来避免在滤波之前重复进行纹素解压缩。通过在lane之间分配独特的工作,在足够大的放大倍数下,我们可以使用<=1个纹素评估/像素来实现零误差滤波。对于剩余的情况,我们提出了新的滤波回退方法,这些方法也比以前的方法实现了更高的质量。
🔬 方法详解
问题定义:论文旨在解决在高压缩率纹理格式下,传统纹理滤波方法效率低、质量差的问题。现有方法,如随机纹理滤波(STF),虽然避免了多次纹素评估,但在放大时容易产生视觉伪影,如噪声和闪烁,且需要额外的去噪处理。
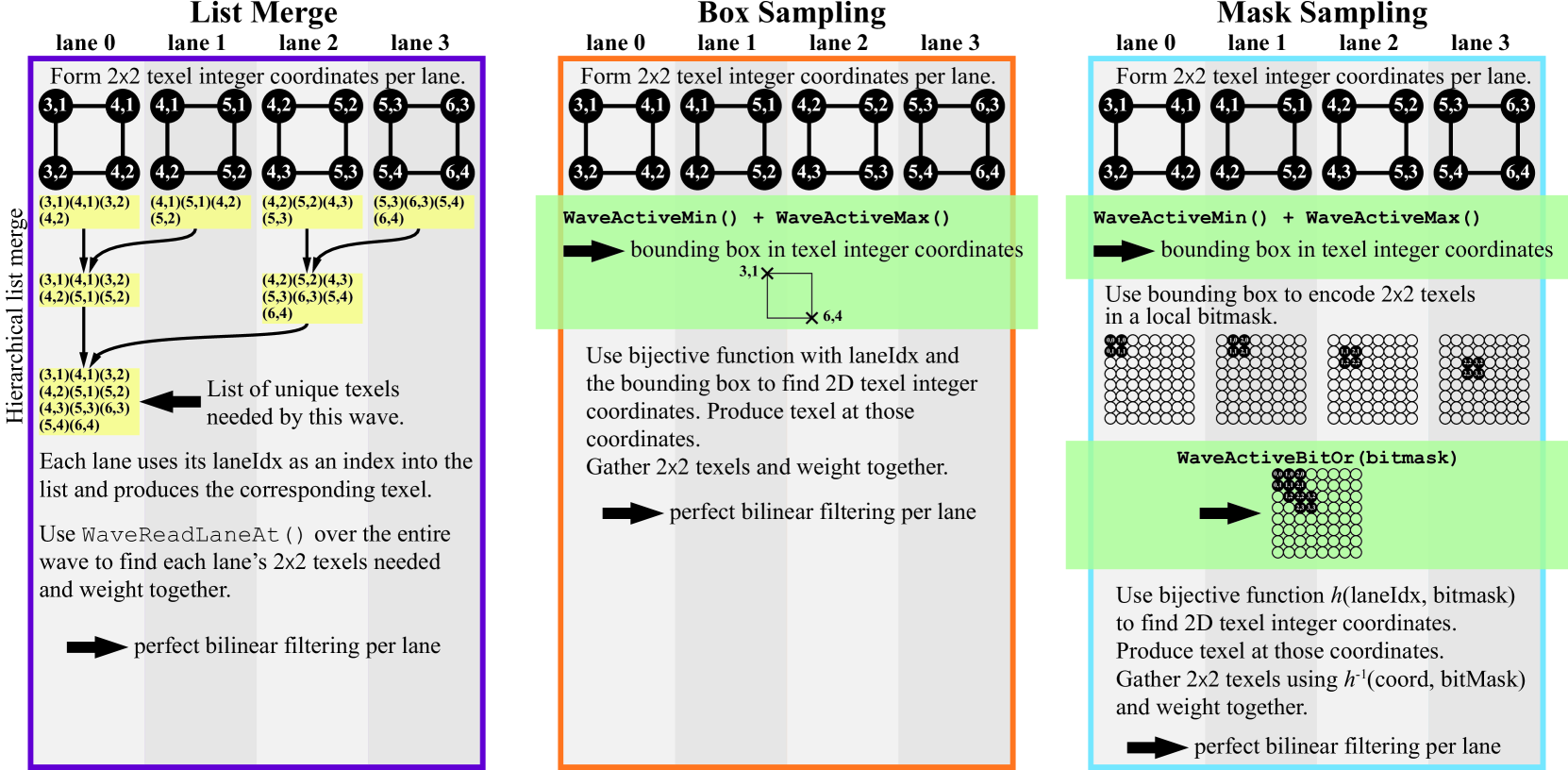
核心思路:论文的核心思路是利用GPU波通信(wave communication)在线程(lane)之间共享已解码的纹素值,从而避免重复的纹素解压缩操作。通过协同处理,每个线程负责一部分纹素的解压和滤波,最终合并结果,提高整体效率和滤波质量。
技术框架:整体框架主要包含两个阶段:一是利用GPU波通信进行纹素共享和初步滤波;二是针对放大倍数不足的情况,采用高质量的滤波回退方法。具体流程为:首先,确定每个线程需要处理的纹素范围;然后,利用波通信在线程间共享纹素数据;接着,每个线程独立进行滤波计算;最后,将结果合并,得到最终的滤波结果。对于放大倍数不足的情况,则切换到高质量的滤波回退方案。
关键创新:论文的关键创新在于将GPU波通信引入到纹理滤波过程中,实现了线程间的纹素数据共享,从而避免了重复的纹素解压缩操作。这种方法能够显著提高滤波效率,尤其是在放大倍数较高的情况下。此外,论文还提出了高质量的滤波回退方案,进一步提升了整体滤波质量。
关键设计:论文的关键设计包括:1) 如何有效地利用GPU波通信进行纹素数据共享;2) 如何根据放大倍数动态选择滤波策略(直接滤波或回退滤波);3) 如何设计高质量的滤波回退方案。具体的参数设置和网络结构(如果使用)在论文中未明确提及,属于未知信息。
🖼️ 关键图片
📊 实验亮点
论文提出的协同纹理滤波算法,在放大倍数足够大的情况下,实现了每个像素小于等于1个纹素评估的零误差滤波。此外,论文还提出了高质量的滤波回退方案,进一步提升了整体滤波质量。具体的性能数据和对比基线在摘要中未提及,属于未知信息。
🎯 应用场景
该研究成果可广泛应用于游戏、虚拟现实、增强现实等需要高质量纹理渲染的领域。通过提高纹理滤波的效率和质量,可以降低GPU的计算负担,提升渲染性能,并改善用户的视觉体验。未来,该技术有望应用于移动设备等资源受限的平台,实现更流畅、更逼真的图形渲染效果。
📄 摘要(原文)
Recent advances in texture compression provide major improvements in compression ratios, but cannot use the GPU's texture units for decompression and filtering. This has led to the development of stochastic texture filtering (STF) techniques to avoid the high cost of multiple texel evaluations with such formats. Unfortunately, those methods can give undesirable visual appearance changes under magnification and may contain visible noise and flicker despite the use of spatiotemporal denoisers. Recent work substantially improves the quality of magnification filtering with STF by sharing decoded texel values between nearby pixels (Wronski 2025). Using GPU wave communication intrinsics, this sharing can be performed inside actively executing shaders without memory traffic overhead. We take this idea further and present novel algorithms that use wave communication between lanes to avoid repeated texel decompression prior to filtering. By distributing unique work across lanes, we can achieve zero-error filtering using <=1 texel evaluations per pixel given a sufficiently large magnification factor. For the remaining cases, we propose novel filtering fallback methods that also achieve higher quality than prior approaches.