Real-Time Per-Garment Virtual Try-On with Temporal Consistency for Loose-Fitting Garments
作者: Zaiqiang Wu, I-Chao Shen, Takeo Igarashi
分类: cs.GR, cs.CV
发布日期: 2025-06-14 (更新: 2025-09-04)
DOI: 10.1111/cgf.70272
💡 一句话要点
提出一种时序一致的宽松服装实时虚拟试穿方法
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 虚拟试穿 宽松服装 语义分割 时序一致性 循环神经网络
📋 核心要点
- 现有单件服装虚拟试穿方法在处理宽松服装时,由于人体语义图的不可靠性,对齐效果不佳。
- 论文提出一种两阶段方法,首先提取服装不变的表示,再利用辅助网络估计语义图,增强鲁棒性。
- 引入循环服装合成框架,利用时间依赖性提高帧间一致性,实验证明在图像质量和时间一致性上优于现有方法。
📝 摘要(中文)
单件服装虚拟试穿方法通常为每件服装收集特定数据集,并训练专门针对该服装的网络,以获得更好的效果。然而,这些方法在处理宽松服装时常常遇到困难,主要有两个限制:(1)它们依赖于人体语义图来对齐服装和身体,但当身体轮廓被宽松服装遮挡时,这些语义图变得不可靠,导致结果质量下降;(2)它们在逐帧的基础上训练服装合成网络,而不利用时间信息,从而导致明显的抖动伪影。为了解决第一个限制,我们提出了一种用于鲁棒语义图估计的两阶段方法。首先,我们从原始输入图像中提取服装不变的表示。然后,将此表示传递到辅助网络以估计语义图。这增强了在服装特定数据集生成期间,宽松服装下语义图估计的鲁棒性。为了解决第二个限制,我们引入了一个循环服装合成框架,该框架结合了时间依赖性,以提高帧间一致性,同时保持实时性能。我们进行了定性和定量评估,表明我们的方法在图像质量和时间一致性方面均优于现有方法。消融研究进一步验证了服装不变表示和循环合成框架的有效性。
🔬 方法详解
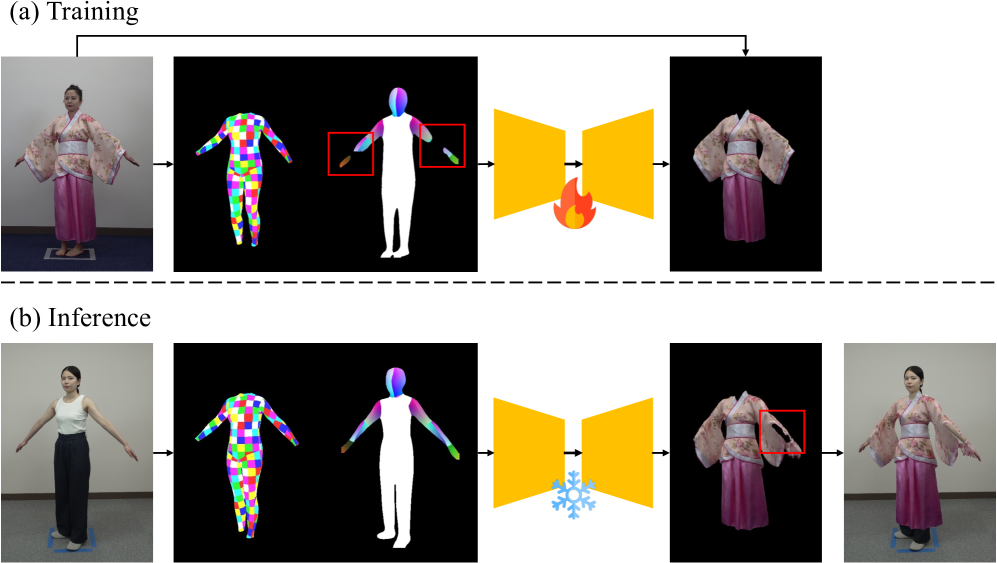
问题定义:现有单件服装虚拟试穿方法在处理宽松服装时,依赖人体语义图进行服装对齐,但宽松服装会遮挡身体轮廓,导致语义图估计不准确,进而影响试穿效果。此外,现有方法逐帧合成服装,忽略了视频序列的时间信息,导致合成结果出现抖动等时序不一致问题。
核心思路:论文的核心思路是分别解决语义图估计的鲁棒性和服装合成的时序一致性问题。针对语义图估计问题,提出提取服装不变的特征表示,以减少服装对语义分割的影响。针对时序一致性问题,引入循环神经网络,利用前后帧的信息来稳定合成结果。
技术框架:该方法主要包含两个阶段:1) 鲁棒的语义图估计:首先,使用一个编码器从输入图像中提取服装不变的特征表示。然后,使用一个辅助网络,基于该特征表示估计人体语义图。2) 时序一致的服装合成:使用一个循环神经网络(RNN),将当前帧的特征和上一帧的隐藏状态作为输入,生成当前帧的服装图像。
关键创新:该方法的主要创新点在于:1) 提出了服装不变的特征表示,提高了宽松服装下语义图估计的鲁棒性。2) 引入了循环神经网络,实现了时序一致的服装合成,减少了抖动伪影。
关键设计:在语义图估计阶段,编码器和辅助网络的具体结构未知,但目标是提取与服装无关的身体特征。在服装合成阶段,RNN的具体结构也未知,但需要能够有效地利用时间信息。损失函数的设计也至关重要,需要同时考虑图像质量和时序一致性。具体参数设置未知。
🖼️ 关键图片


📊 实验亮点
论文通过定性和定量实验验证了所提出方法的有效性。实验结果表明,该方法在图像质量和时间一致性方面均优于现有方法。消融研究进一步验证了服装不变表示和循环合成框架的有效性。具体的性能数据和对比基线未知。
🎯 应用场景
该研究成果可应用于在线服装购物平台,为用户提供更逼真、更稳定的虚拟试穿体验,尤其是在宽松服装的试穿方面。这可以提高用户的购买信心,减少退货率,并提升购物体验。未来,该技术还可以扩展到其他虚拟试穿场景,例如虚拟化妆、虚拟发型设计等。
📄 摘要(原文)
Per-garment virtual try-on methods collect garment-specific datasets and train networks tailored to each garment to achieve superior results. However, these approaches often struggle with loose-fitting garments due to two key limitations: (1) They rely on human body semantic maps to align garments with the body, but these maps become unreliable when body contours are obscured by loose-fitting garments, resulting in degraded outcomes; (2) They train garment synthesis networks on a per-frame basis without utilizing temporal information, leading to noticeable jittering artifacts. To address the first limitation, we propose a two-stage approach for robust semantic map estimation. First, we extract a garment-invariant representation from the raw input image. This representation is then passed through an auxiliary network to estimate the semantic map. This enhances the robustness of semantic map estimation under loose-fitting garments during garment-specific dataset generation. To address the second limitation, we introduce a recurrent garment synthesis framework that incorporates temporal dependencies to improve frame-to-frame coherence while maintaining real-time performance. We conducted qualitative and quantitative evaluations to demonstrate that our method outperforms existing approaches in both image quality and temporal coherence. Ablation studies further validate the effectiveness of the garment-invariant representation and the recurrent synthesis framework.