TC-GS: A Faster Gaussian Splatting Module Utilizing Tensor Cores
作者: Zimu Liao, Jifeng Ding, Siwei Cui, Ruixuan Gong, Boni Hu, Yi Wang, Hengjie Li, XIngcheng Zhang, Hui Wang, Rong Fu
分类: cs.GR, cs.CV, cs.DC
发布日期: 2025-05-30 (更新: 2025-10-11)
备注: 15 pages, 6 figures
💡 一句话要点
TC-GS:利用张量核心加速3D高斯溅射渲染模块
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D高斯溅射 张量核心 渲染加速 矩阵乘法 alpha混合
📋 核心要点
- 3DGS渲染中条件alpha混合计算成本高昂,现有方法未能充分利用硬件加速能力。
- TC-GS将alpha计算转化为矩阵乘法,有效利用张量核心,实现通用且即插即用的加速模块。
- 实验表明,TC-GS在保持渲染质量的同时,实现了显著的加速效果,最高可达5.6倍。
📝 摘要(中文)
本文提出TC-GS,一个算法无关的通用模块,旨在扩展张量核心(TCU)在3D高斯溅射(3DGS)中的应用,从而显著提高渲染速度并无缝集成到现有的3DGS优化框架中。其核心创新在于将alpha计算映射到矩阵乘法,充分利用现有3DGS实现中原本空闲的TCU。TC-GS为现有的顶级加速算法提供即插即用的加速,并与渲染管线设计(如高斯压缩和冗余消除算法)无缝集成。此外,我们引入了一种全局到局部的坐标变换,以减轻张量核心半精度计算引起的像素坐标二次项的舍入误差。大量实验表明,我们的方法在保持渲染质量的同时,比现有的高斯加速算法提供了额外的2.18倍加速,从而实现了高达5.6倍的总加速。
🔬 方法详解
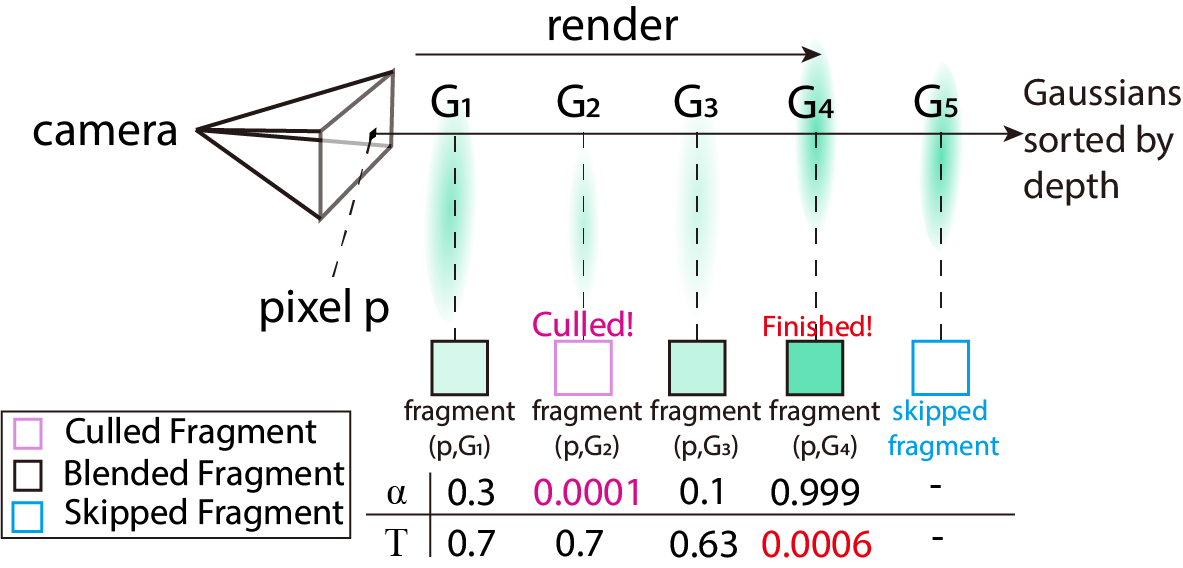
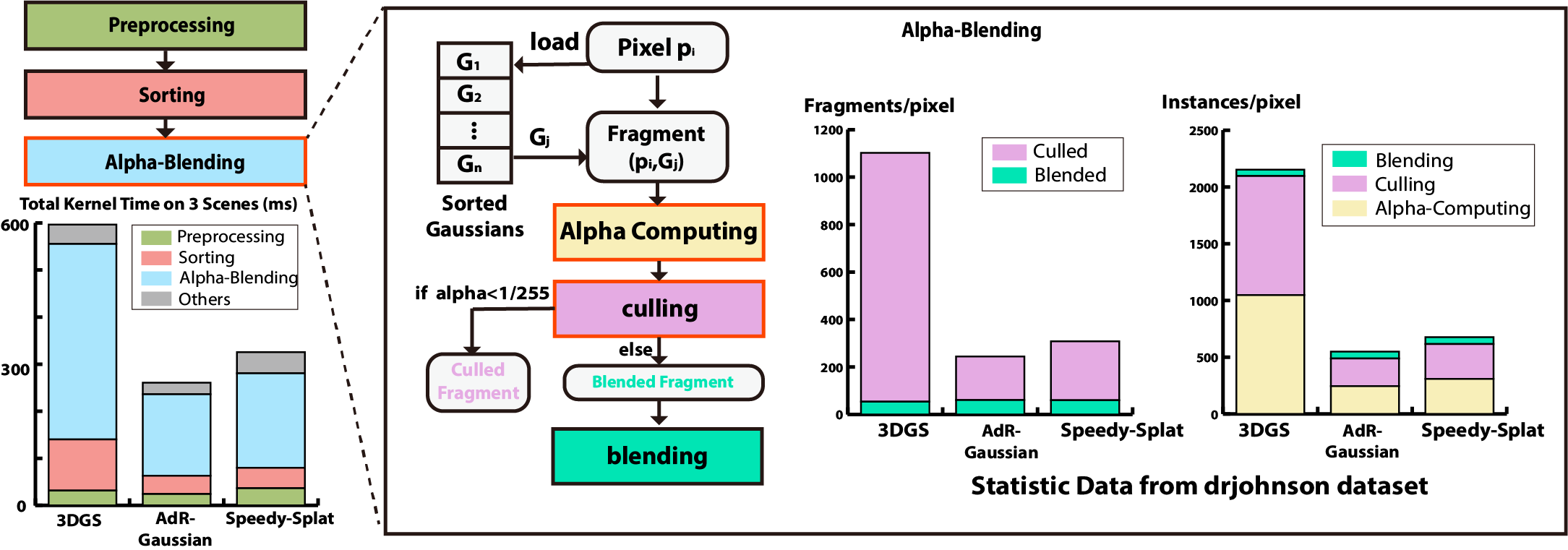
问题定义:3D高斯溅射(3DGS)渲染过程中,条件alpha混合是计算瓶颈。现有方法在利用硬件加速器(如NVIDIA的Tensor Core)方面存在不足,导致渲染效率受限。尤其是在alpha混合计算中,Tensor Core的利用率不高,造成了计算资源的浪费。
核心思路:TC-GS的核心思路是将alpha混合计算过程重新建模为矩阵乘法运算。通过这种转换,可以将原本串行的alpha混合操作并行化,并充分利用Tensor Core进行加速。这种方法不依赖于特定的3DGS算法,具有通用性和可扩展性。
技术框架:TC-GS作为一个独立的模块,可以无缝集成到现有的3DGS渲染管线中。其主要流程包括:1) 将高斯参数传递给TC-GS模块;2) 在TC-GS模块中,将alpha混合计算转化为矩阵乘法;3) 利用Tensor Core进行矩阵乘法加速;4) 将计算结果返回给渲染管线。此外,为了解决半精度计算带来的精度问题,还引入了全局到局部的坐标变换。
关键创新:TC-GS最重要的创新在于将alpha混合计算映射到矩阵乘法,从而能够充分利用Tensor Core进行加速。这种方法避免了对现有3DGS算法进行大规模修改,实现了即插即用的加速效果。此外,全局到局部坐标变换有效缓解了半精度计算带来的精度损失。
关键设计:为了保证精度,TC-GS采用全局到局部坐标变换,将像素坐标转换到局部坐标系下,从而减小了二次项的数值范围,降低了舍入误差。具体而言,首先计算所有高斯中心的平均值作为全局坐标系的原点,然后将像素坐标转换到以该原点为中心的局部坐标系下。在损失函数方面,TC-GS没有引入新的损失函数,而是直接利用现有3DGS算法的损失函数进行优化。
🖼️ 关键图片

📊 实验亮点
实验结果表明,TC-GS在现有高斯加速算法的基础上,实现了额外的2.18倍加速,总加速可达5.6倍。在保持渲染质量的同时,显著提高了渲染效率。TC-GS的加速效果在不同的数据集和场景下均表现稳定,证明了其通用性和有效性。这些结果表明,TC-GS是一种极具潜力的3DGS加速方法。
🎯 应用场景
TC-GS可广泛应用于需要实时渲染3D场景的领域,如虚拟现实(VR)、增强现实(AR)、游戏开发、自动驾驶模拟等。通过提高渲染效率,TC-GS能够降低硬件需求,提升用户体验,并为更复杂的3D场景渲染提供可能性。未来,该技术有望推动3D内容创作和交互方式的革新。
📄 摘要(原文)
3D Gaussian Splatting (3DGS) renders pixels by rasterizing Gaussian primitives, where conditional alpha-blending dominates the computational cost in the rendering pipeline. This paper proposes TC-GS, an algorithm-independent universal module that expands the applicability of Tensor Core (TCU) for 3DGS, leading to substantial speedups and seamless integration into existing 3DGS optimization frameworks. The key innovation lies in mapping alpha computation to matrix multiplication, fully utilizing otherwise idle TCUs in existing 3DGS implementations. TC-GS provides plug-and-play acceleration for existing top-tier acceleration algorithms and integrates seamlessly with rendering pipeline designs, such as Gaussian compression and redundancy elimination algorithms. Additionally, we introduce a global-to-local coordinate transformation to mitigate rounding errors from quadratic terms of pixel coordinates caused by Tensor Core half-precision computation. Extensive experiments demonstrate that our method maintains rendering quality while providing an additional 2.18x speedup over existing Gaussian acceleration algorithms, thereby achieving a total acceleration of up to 5.6x.