Neural Face Skinning for Mesh-agnostic Facial Expression Cloning
作者: Sihun Cha, Serin Yoon, Kwanggyoon Seo, Junyong Noh
分类: cs.GR, cs.CV
发布日期: 2025-05-28
💡 一句话要点
提出神经面部蒙皮方法,实现网格无关的面部表情克隆与操控
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 面部表情重定向 神经蒙皮 面部动画 深度学习 网格变形
📋 核心要点
- 现有方法难以在面部表情重定向中兼顾全局控制和局部细节,尤其是在网格结构不同的情况下。
- 该方法通过学习蒙皮权重来局部化全局潜在编码的影响,从而实现精确和特定区域的变形控制。
- 实验表明,该方法在表情保真度、变形传递精度和跨网格适应性方面优于现有技术。
📝 摘要(中文)
本文提出了一种用于面部动画重定向的神经面部蒙皮方法,旨在解决面部表情精确重定向和可控性之间的难题。现有深度学习方法通常将面部表情编码为全局潜在编码,但难以捕捉局部区域的精细细节。虽然一些方法通过局部变形传递来提高局部精度,但这往往会使面部表情的整体控制变得复杂。为了解决这个问题,本文结合了全局和局部变形模型的优点。该方法能够跨不同的面部网格实现直观的控制和细致的表情克隆,而无需考虑其底层结构。核心思想是将全局潜在编码的影响局部化到目标网格上。该模型通过来自预定义分割标签的间接监督,学习预测目标面部网格每个顶点的蒙皮权重。这些预测的权重将全局潜在编码局部化,即使对于具有未见形状的网格也能实现精确和特定区域的变形。使用基于面部动作编码系统(FACS)的blendshape来监督潜在编码,以确保可解释性并允许直接编辑生成的动画。通过大量的实验,证明了该方法在表情保真度、变形传递精度以及跨不同网格结构的适应性方面优于现有方法。
🔬 方法详解
问题定义:现有面部表情重定向方法,特别是基于深度学习的方法,通常难以在全局控制和局部细节之间取得平衡。基于全局潜在编码的方法虽然易于控制,但难以捕捉细微的局部表情变化。而基于局部变形传递的方法虽然能提高局部精度,但会牺牲整体控制的直观性。此外,这些方法通常对输入网格的拓扑结构敏感,难以泛化到具有不同网格结构的面部模型上。
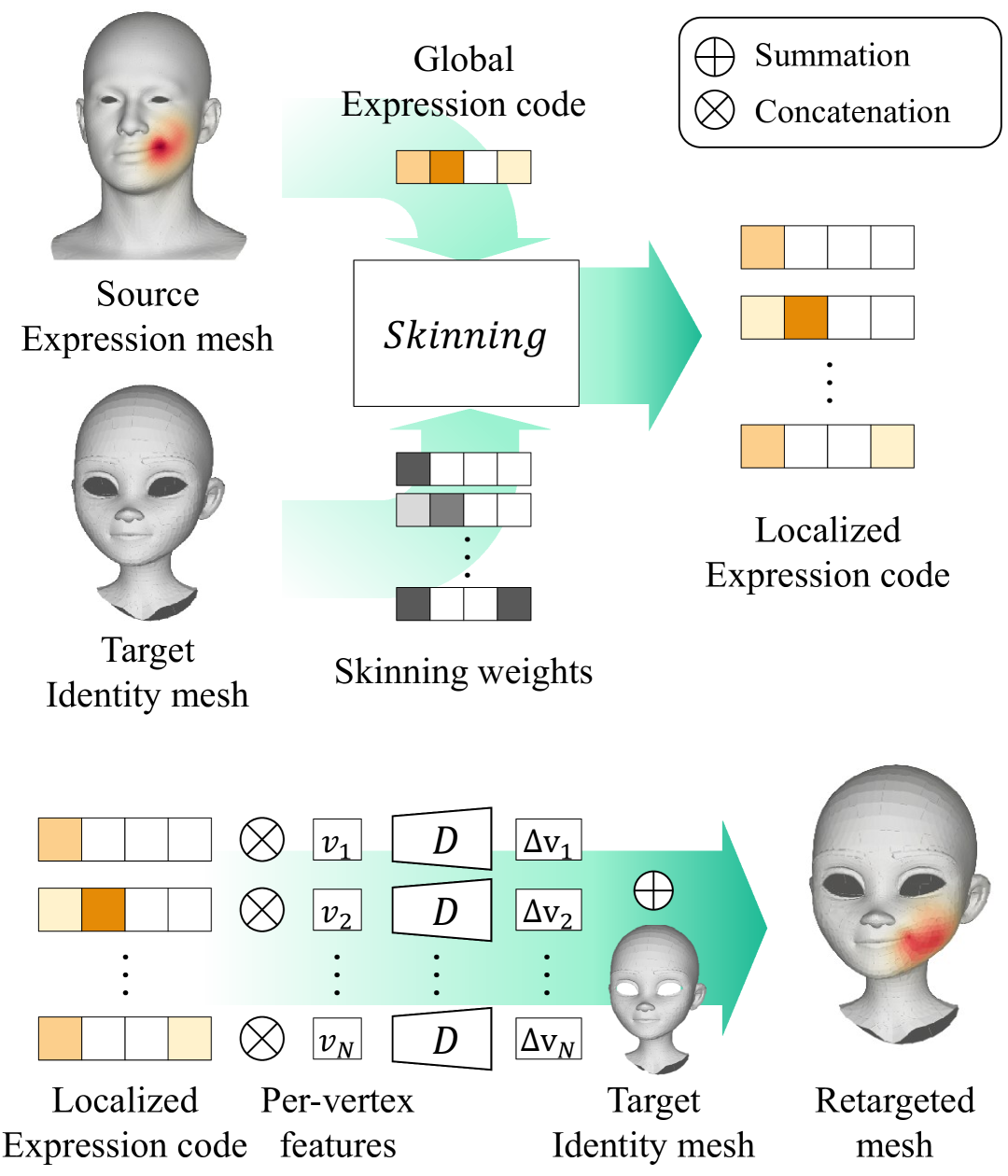
核心思路:本文的核心思路是将全局潜在编码的影响局部化到目标网格上。通过学习每个顶点的蒙皮权重,使得全局潜在编码能够更精细地控制局部区域的变形。这种方法结合了全局控制的优点和局部细节的精度,同时降低了对输入网格结构的依赖性。
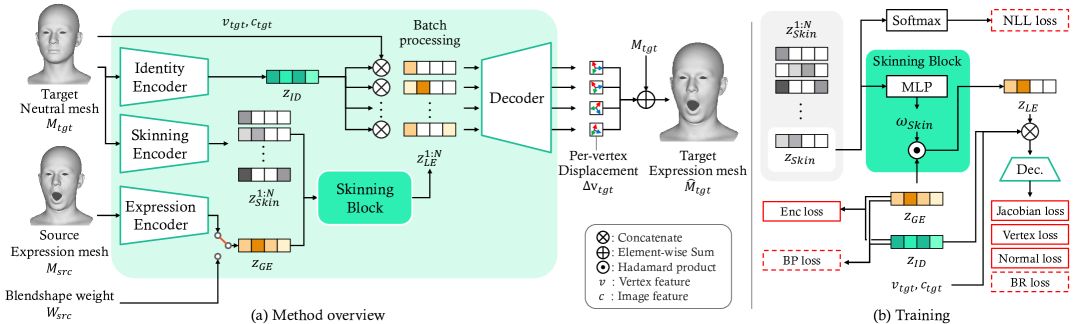
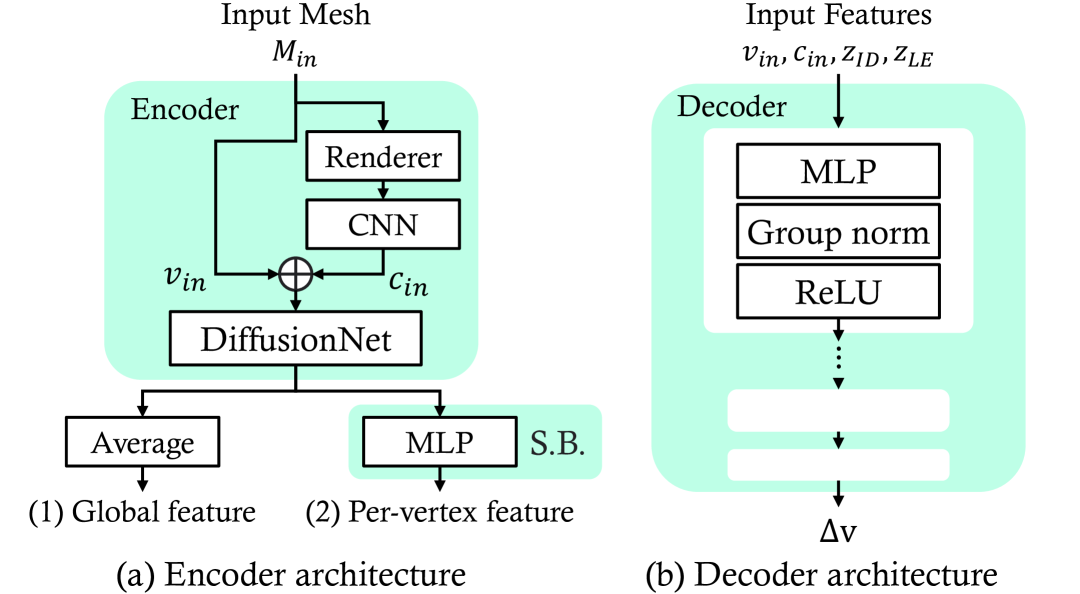
技术框架:该方法包含以下主要模块:1) 一个全局潜在编码器,用于将面部表情编码为潜在向量。2) 一个蒙皮权重预测网络,用于预测目标网格每个顶点的蒙皮权重。该网络以目标网格的几何信息和预定义的分割标签作为输入。3) 一个变形模块,利用预测的蒙皮权重和全局潜在编码来驱动目标网格的变形。整个框架通过端到端的方式进行训练。
关键创新:该方法最重要的创新点在于使用神经蒙皮来局部化全局潜在编码的影响。与传统的线性蒙皮不同,该方法学习的蒙皮权重是动态的,并且能够根据输入网格的几何信息和表情变化进行调整。这种动态蒙皮的方式使得模型能够更好地适应不同的网格结构和表情变化,从而提高表情重定向的精度和泛化能力。
关键设计:该方法使用基于FACS的blendshape作为监督信号来训练全局潜在编码器,以确保潜在编码的可解释性和可编辑性。蒙皮权重预测网络使用卷积神经网络,以提取目标网格的局部几何特征。损失函数包括表情重建损失、蒙皮权重正则化损失和分割一致性损失。分割一致性损失用于鼓励预测的蒙皮权重与预定义的分割标签保持一致。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在表情保真度、变形传递精度和跨网格适应性方面均优于现有方法。与state-of-the-art方法相比,该方法能够生成更逼真和自然的表情动画,并且能够更好地适应具有不同网格结构的面部模型。定量评估和定性比较都验证了该方法的有效性。
🎯 应用场景
该研究成果可广泛应用于虚拟现实、增强现实、游戏开发、电影制作等领域。例如,可以用于创建更逼真和可控的虚拟角色,实现实时的面部表情捕捉和重定向,以及为不同角色定制面部动画。该技术还可以用于面部表情分析和识别,以及人机交互等应用。
📄 摘要(原文)
Accurately retargeting facial expressions to a face mesh while enabling manipulation is a key challenge in facial animation retargeting. Recent deep-learning methods address this by encoding facial expressions into a global latent code, but they often fail to capture fine-grained details in local regions. While some methods improve local accuracy by transferring deformations locally, this often complicates overall control of the facial expression. To address this, we propose a method that combines the strengths of both global and local deformation models. Our approach enables intuitive control and detailed expression cloning across diverse face meshes, regardless of their underlying structures. The core idea is to localize the influence of the global latent code on the target mesh. Our model learns to predict skinning weights for each vertex of the target face mesh through indirect supervision from predefined segmentation labels. These predicted weights localize the global latent code, enabling precise and region-specific deformations even for meshes with unseen shapes. We supervise the latent code using Facial Action Coding System (FACS)-based blendshapes to ensure interpretability and allow straightforward editing of the generated animation. Through extensive experiments, we demonstrate improved performance over state-of-the-art methods in terms of expression fidelity, deformation transfer accuracy, and adaptability across diverse mesh structures.