AdaToken-3D: Dynamic Spatial Gating for Efficient 3D Large Multimodal-Models Reasoning
作者: Kai Zhang, Xingyu Chen, Xiaofeng Zhang
分类: cs.GR, cs.CV, cs.IR, cs.IT
发布日期: 2025-05-19
💡 一句话要点
提出AdaToken-3D以解决3D多模态模型的效率问题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态模型 3D场景理解 空间token优化 动态修剪 计算效率 注意力机制 深度学习
📋 核心要点
- 现有的3D LMMs在多模态推理中面临计算效率低下和信息冗余的问题,影响了模型的实际应用。
- 提出的AdaToken-3D框架通过动态修剪冗余空间token,利用空间贡献分析优化多模态推理过程。
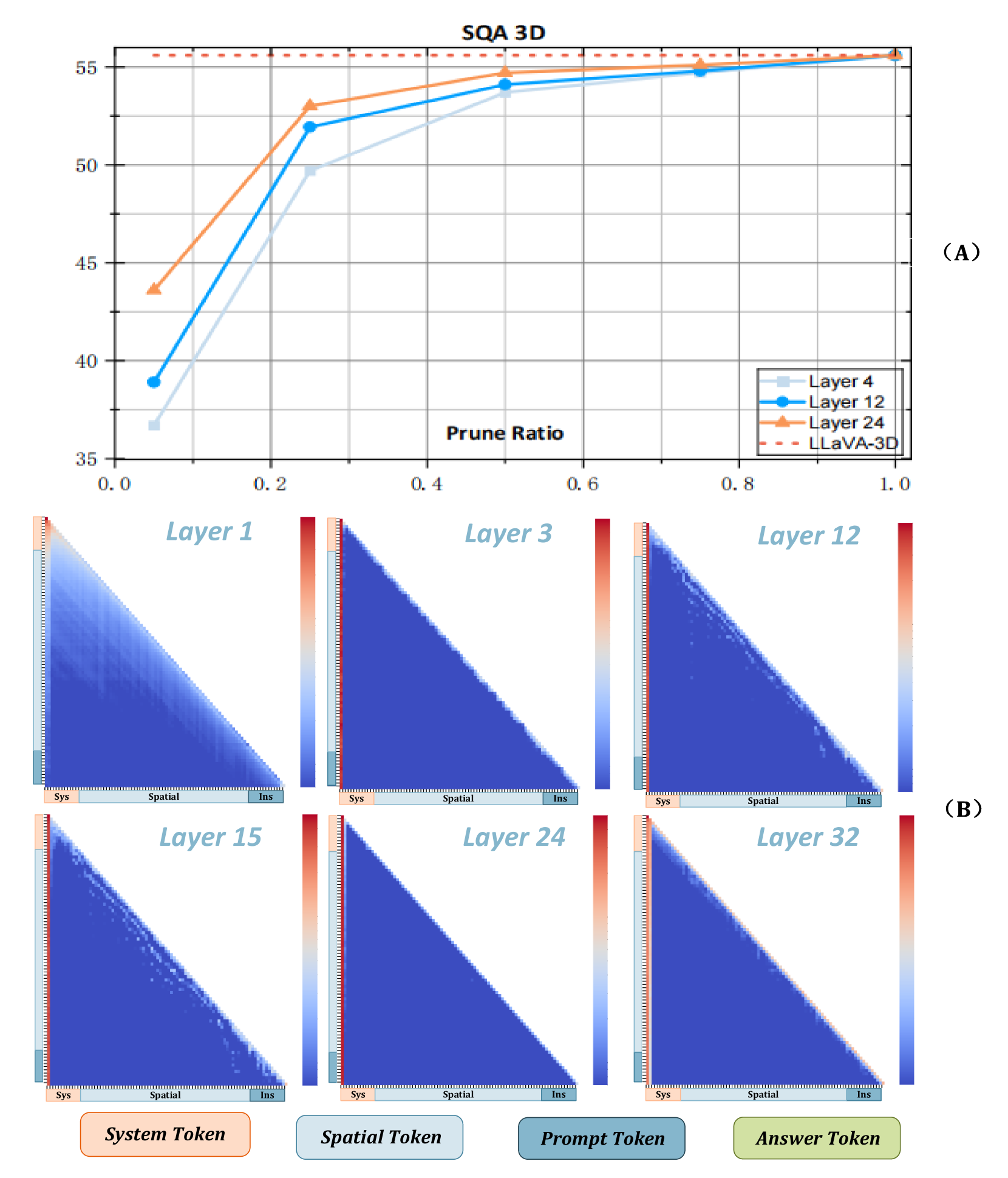
- 在LLaVA-3D实验中,AdaToken-3D实现了21%的推理速度提升和63%的FLOPs减少,同时保持了任务的准确性。
📝 摘要(中文)
大型多模态模型(LMMs)在深度学习中成为重要研究方向,尤其在3D场景理解方面表现出色。然而,现有的3D LMMs因使用大量空间token进行多模态推理而面临计算开销过大和信息冗余的问题。为了解决这一挑战,本文提出了AdaToken-3D,一个自适应空间token优化框架,通过空间贡献分析动态修剪冗余token。该方法通过注意力模式挖掘量化token级信息流,自动调整不同3D LMM架构的修剪策略。实验结果表明,AdaToken-3D在保持原有任务准确率的同时,实现了21%的推理速度提升和63%的FLOPs减少。
🔬 方法详解
问题定义:本文针对现有3D LMMs在多模态推理中存在的计算效率低下和信息冗余问题进行研究。现有方法使用大量空间token,导致计算开销过大和冗余信息流的产生。
核心思路:提出AdaToken-3D框架,通过动态修剪冗余token来提高推理效率。该方法通过分析空间token的贡献,自动调整修剪策略,以适应不同的3D LMM架构。
技术框架:AdaToken-3D的整体架构包括空间贡献分析模块和动态修剪模块。首先,通过注意力模式挖掘量化token级信息流,然后根据分析结果动态修剪冗余token,最终优化多模态推理过程。
关键创新:最重要的技术创新在于提出了一种自适应的空间token优化方法,能够根据不同架构的需求动态调整修剪策略。这一方法显著减少了冗余token的使用,提升了推理效率。
关键设计:在设计中,采用了注意力模式挖掘技术来量化token的贡献,并通过设置合理的阈值来决定token的保留与修剪。此外,框架的参数设置和损失函数设计也经过精心调整,以确保模型的准确性和效率。
🖼️ 关键图片


📊 实验亮点
实验结果显示,AdaToken-3D在LLaVA-3D模型上实现了21%的推理速度提升和63%的FLOPs减少,且在保持原有任务准确率的同时,显著提高了模型的计算效率。这些结果表明该方法在多模态推理中的有效性和实用性。
🎯 应用场景
该研究具有广泛的应用潜力,尤其在自动驾驶、虚拟现实和机器人等领域。通过提高3D多模态模型的推理效率,AdaToken-3D能够加速相关技术的实际部署,推动智能系统的进一步发展。
📄 摘要(原文)
Large Multimodal Models (LMMs) have become a pivotal research focus in deep learning, demonstrating remarkable capabilities in 3D scene understanding. However, current 3D LMMs employing thousands of spatial tokens for multimodal reasoning suffer from critical inefficiencies: excessive computational overhead and redundant information flows. Unlike 2D VLMs processing single images, 3D LMMs exhibit inherent architectural redundancy due to the heterogeneous mechanisms between spatial tokens and visual tokens. To address this challenge, we propose AdaToken-3D, an adaptive spatial token optimization framework that dynamically prunes redundant tokens through spatial contribution analysis. Our method automatically tailors pruning strategies to different 3D LMM architectures by quantifying token-level information flows via attention pattern mining. Extensive experiments on LLaVA-3D (a 7B parameter 3D-LMM) demonstrate that AdaToken-3D achieves 21\% faster inference speed and 63\% FLOPs reduction while maintaining original task accuracy. Beyond efficiency gains, this work systematically investigates redundancy patterns in multimodal spatial information flows through quantitative token interaction analysis. Our findings reveal that over 60\% of spatial tokens contribute minimally ($<$5\%) to the final predictions, establishing theoretical foundations for efficient 3D multimodal learning.