Multimodal Benchmarking and Recommendation of Text-to-Image Generation Models
作者: Kapil Wanaskar, Gaytri Jena, Magdalini Eirinaki
分类: cs.GR, cs.AI, cs.IR, cs.LG
发布日期: 2025-05-06
💡 一句话要点
提出一个统一的文本到图像生成模型评测框架,着重研究元数据增强提示的影响。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本到图像生成 模型评测 元数据增强 DeepFashion-MultiModal CLIP相似度
📋 核心要点
- 现有文本到图像生成模型缺乏统一的评估标准,难以客观比较不同模型性能。
- 该框架通过元数据增强提示,提升生成图像的视觉真实感和语义保真度。
- 实验结果表明,结构化元数据增强能显著提高模型在不同架构下的鲁棒性。
📝 摘要(中文)
本文提出了一个开源的、统一的文本到图像生成模型评测框架,特别关注元数据增强提示的影响。利用DeepFashion-MultiModal数据集,我们通过一套全面的定量指标(包括加权得分、基于CLIP的相似度、LPIPS、FID和基于检索的度量)以及定性分析来评估生成的输出。结果表明,结构化的元数据增强显著提高了各种文本到图像架构的视觉真实感、语义保真度和模型鲁棒性。虽然不是传统的推荐系统,但我们的框架能够根据评估指标为模型选择和提示设计提供特定于任务的建议。
🔬 方法详解
问题定义:现有文本到图像生成模型缺乏统一的、开源的评估框架,难以公平地比较不同模型在各种任务上的性能。此外,如何有效地利用元数据信息来提升生成图像的质量,特别是视觉真实感和语义保真度,也是一个重要的挑战。
核心思路:该论文的核心思路是构建一个统一的评测框架,并重点研究如何通过结构化的元数据增强提示来提升文本到图像生成模型的性能。通过定量和定性分析,评估元数据增强对生成图像质量的影响,并为模型选择和提示设计提供指导。
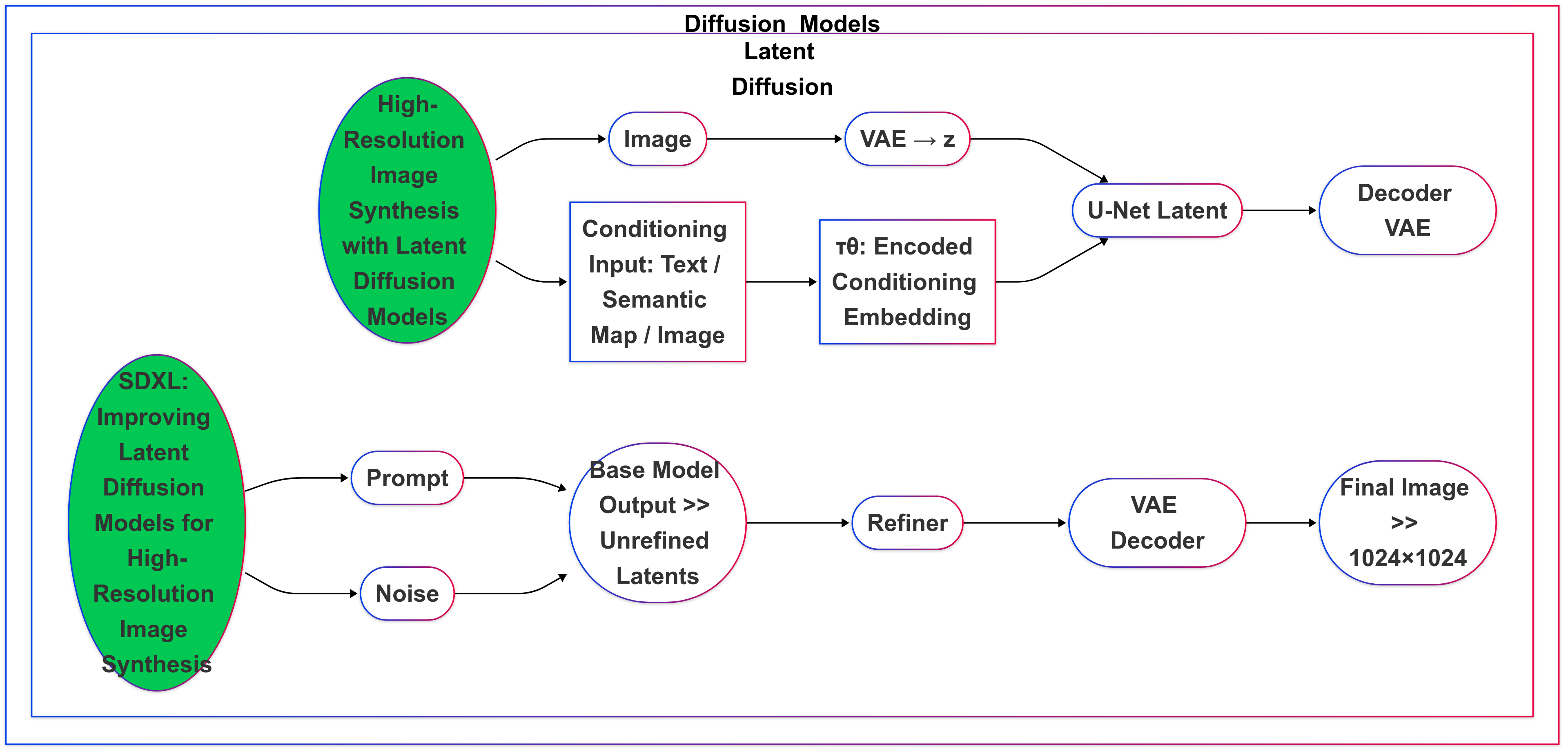
技术框架:该框架主要包含以下几个阶段:1) 数据集准备:使用DeepFashion-MultiModal数据集,该数据集包含丰富的图像和元数据信息。2) 提示工程:设计不同的提示策略,包括原始文本提示和元数据增强提示。3) 模型生成:使用不同的文本到图像生成模型生成图像。4) 评估指标计算:使用一系列定量指标(如Weighted Score, CLIP similarity, LPIPS, FID, retrieval-based measures)和定性分析来评估生成图像的质量。5) 结果分析与推荐:根据评估结果,分析元数据增强对模型性能的影响,并为模型选择和提示设计提供建议。
关键创新:该论文的关键创新在于:1) 提出了一个开源的、统一的文本到图像生成模型评测框架,方便研究人员进行模型比较和性能评估。2) 重点研究了元数据增强提示对生成图像质量的影响,并证明了结构化元数据可以显著提升视觉真实感和语义保真度。
关键设计:论文中关键的设计包括:1) 使用DeepFashion-MultiModal数据集,该数据集提供了丰富的图像和元数据信息,方便进行元数据增强提示的研究。2) 采用了一系列全面的定量指标,包括Weighted Score, CLIP similarity, LPIPS, FID, retrieval-based measures,从不同角度评估生成图像的质量。3) 进行了定性分析,人工评估生成图像的视觉真实感和语义保真度。
🖼️ 关键图片


📊 实验亮点
实验结果表明,结构化的元数据增强提示能够显著提高文本到图像生成模型的性能。例如,使用元数据增强提示后,生成图像的视觉真实感和语义保真度得到了明显提升,FID指标也得到了改善。该框架为模型选择和提示设计提供了有价值的参考。
🎯 应用场景
该研究成果可应用于电商、时尚、室内设计等领域,帮助用户根据文本描述生成高质量的图像。通过元数据增强提示,可以提升生成图像的真实感和语义准确性,从而改善用户体验。此外,该评测框架可以帮助研究人员更好地比较和评估不同的文本到图像生成模型。
📄 摘要(原文)
This work presents an open-source unified benchmarking and evaluation framework for text-to-image generation models, with a particular focus on the impact of metadata augmented prompts. Leveraging the DeepFashion-MultiModal dataset, we assess generated outputs through a comprehensive set of quantitative metrics, including Weighted Score, CLIP (Contrastive Language Image Pre-training)-based similarity, LPIPS (Learned Perceptual Image Patch Similarity), FID (Frechet Inception Distance), and retrieval-based measures, as well as qualitative analysis. Our results demonstrate that structured metadata enrichments greatly enhance visual realism, semantic fidelity, and model robustness across diverse text-to-image architectures. While not a traditional recommender system, our framework enables task-specific recommendations for model selection and prompt design based on evaluation metrics.