SMPL-GPTexture: Dual-View 3D Human Texture Estimation using Text-to-Image Generation Models
作者: Mingxiao Tu, Shuchang Ye, Hoijoon Jung, Jinman Kim
分类: cs.GR, cs.CV
发布日期: 2025-04-17
💡 一句话要点
SMPL-GPTexture:利用文本到图像生成模型实现双视角3D人体纹理估计
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 3D人体纹理 文本到图像生成 SMPL模型 反向光栅化 扩散模型 图像修复 双视角图像 虚拟化身
📋 核心要点
- 现有方法难以获取真实配对的前后人体图像,且依赖图像先验的生成模型易产生伪影和细节丢失。
- SMPL-GPTexture利用文本到图像生成模型生成配对的前后视图图像,作为纹理估计的初始输入。
- 该方法结合SMPL对齐、反向光栅化和扩散修复,生成高质量、完整的3D人体纹理。
📝 摘要(中文)
为3D人体化身生成高质量、照片般逼真的纹理是计算机视觉和多媒体领域一项基础但具有挑战性的任务。然而,现实中人体对象配对的前后图像由于隐私、伦理和采集成本等原因难以获得,限制了数据的可扩展性。此外,使用深度生成模型(如GAN或扩散模型)从图像输入中学习先验知识来推断未见区域(如人体背部)通常会导致伪影、结构不一致或丢失精细细节。为了解决这些问题,我们提出了一种新颖的流程SMPL-GPTexture,它以自然语言提示作为输入,并利用最先进的文本到图像生成模型来生成人体对象配对的高分辨率前后图像,作为纹理估计的起点。使用生成的配对双视角图像,我们首先采用人体网格恢复模型来获得图像像素和3D模型UV坐标之间鲁棒的2D到3D SMPL对齐。其次,我们使用一种反向光栅化技术,将观察到的颜色从输入图像显式地投影到UV空间中,从而生成准确、完整的纹理贴图。最后,我们应用基于扩散的修复模块来填充缺失区域,然后融合机制将这些结果组合成统一的完整纹理贴图。大量实验表明,我们的SMPL-GPTexture可以生成与用户提示对齐的高分辨率纹理。
🔬 方法详解
问题定义:论文旨在解决3D人体化身纹理生成中,真实配对前后视图图像难以获取,以及现有基于图像先验的生成模型容易产生伪影和细节丢失的问题。现有方法依赖大量真实数据,成本高昂且存在隐私问题,而直接从单视角图像推断背面纹理往往质量不高。
核心思路:论文的核心思路是利用文本到图像生成模型,以自然语言描述作为输入,生成高质量、配对的前后视图图像,从而绕过对真实配对图像的依赖。这种方法利用了文本到图像模型的强大生成能力,为后续的纹理估计提供了可靠的初始数据。
技术框架:SMPL-GPTexture的整体流程包括以下几个阶段:1) 文本到图像生成:使用文本提示生成配对的前后视图图像。2) SMPL对齐:使用人体网格恢复模型,将生成的图像与SMPL模型进行2D-3D对齐。3) 反向光栅化:将图像颜色投影到SMPL模型的UV空间,生成初始纹理贴图。4) 扩散修复:使用扩散模型填充纹理贴图中的缺失区域。5) 纹理融合:将修复后的纹理贴图进行融合,生成最终的完整纹理。
关键创新:该方法最重要的创新点在于利用文本到图像生成模型来生成纹理估计所需的配对前后视图图像。与直接从图像推断纹理的方法相比,该方法避免了对大量真实数据的依赖,并且能够生成更具一致性和细节的纹理。此外,结合反向光栅化和扩散修复,进一步提高了纹理的质量和完整性。
关键设计:在SMPL对齐阶段,使用了现有的人体网格恢复模型,确保图像像素与3D模型UV坐标的准确对应。反向光栅化过程显式地将图像颜色投影到UV空间,避免了传统纹理映射中的插值误差。扩散修复模块采用了预训练的扩散模型,并针对纹理修复进行了微调。纹理融合机制则根据不同区域的置信度,对多个纹理贴图进行加权平均。
🖼️ 关键图片

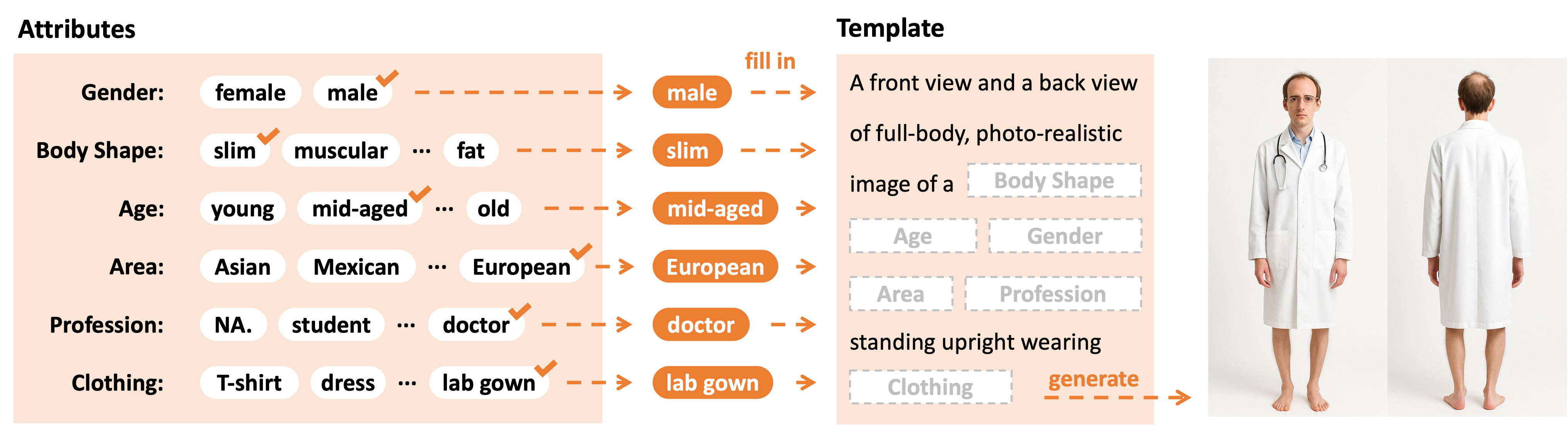

📊 实验亮点
实验结果表明,SMPL-GPTexture能够生成与用户提示对齐的高分辨率纹理。与直接从单视角图像推断纹理的方法相比,该方法生成的纹理在细节、一致性和完整性方面均有显著提升。虽然论文中没有给出具体的量化指标,但视觉效果表明该方法具有很强的实用价值。
🎯 应用场景
该研究成果可广泛应用于虚拟现实、增强现实、游戏开发、电影制作等领域,为创建逼真、个性化的3D人体化身提供了一种高效、低成本的解决方案。通过自然语言描述即可生成高质量的人体纹理,降低了3D内容创作的门槛,并有望推动相关产业的发展。
📄 摘要(原文)
Generating high-quality, photorealistic textures for 3D human avatars remains a fundamental yet challenging task in computer vision and multimedia field. However, real paired front and back images of human subjects are rarely available with privacy, ethical and cost of acquisition, which restricts scalability of the data. Additionally, learning priors from image inputs using deep generative models, such as GANs or diffusion models, to infer unseen regions such as the human back often leads to artifacts, structural inconsistencies, or loss of fine-grained detail. To address these issues, we present SMPL-GPTexture (skinned multi-person linear model - general purpose Texture), a novel pipeline that takes natural language prompts as input and leverages a state-of-the-art text-to-image generation model to produce paired high-resolution front and back images of a human subject as the starting point for texture estimation. Using the generated paired dual-view images, we first employ a human mesh recovery model to obtain a robust 2D-to-3D SMPL alignment between image pixels and the 3D model's UV coordinates for each views. Second, we use an inverted rasterization technique that explicitly projects the observed colour from the input images into the UV space, thereby producing accurate, complete texture maps. Finally, we apply a diffusion-based inpainting module to fill in the missing regions, and the fusion mechanism then combines these results into a unified full texture map. Extensive experiments shows that our SMPL-GPTexture can generate high resolution texture aligned with user's prompts.