Prototype-Guided Diffusion for Digital Pathology: Achieving Foundation Model Performance with Minimal Clinical Data
作者: Ekaterina Redekop, Mara Pleasure, Vedrana Ivezic, Zichen Wang, Kimberly Flores, Anthony Sisk, William Speier, Corey Arnold
分类: cs.GR, cs.AI, eess.IV, q-bio.TO
发布日期: 2025-04-15
💡 一句话要点
提出原型引导的扩散模型,以少量病理数据实现媲美大型数据集的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数字病理学 扩散模型 生成式AI 自监督学习 原型学习
📋 核心要点
- 现有数字病理学基础模型依赖大规模数据集,但数据量与性能的关联机制不明确,增加数据量不一定有效。
- 提出原型引导的扩散模型,生成高质量合成病理数据,用于自监督学习,减少对真实患者数据的依赖。
- 实验表明,使用少量合成数据训练的模型性能可与大型真实数据集训练的模型媲美,甚至更好。
📝 摘要(中文)
数字病理学中的基础模型利用海量数据集学习复杂组织学图像的有效特征表示。然而,数据集大小与性能之间相关性的驱动因素尚不明确,引发了增加数据量是否总是提升性能的必要条件的疑问。本研究提出了一种原型引导的扩散模型,用于大规模生成高质量的合成病理数据,从而实现大规模自监督学习,减少对真实患者样本的依赖,同时保持下游性能。通过在采样过程中使用组织学原型进行引导,确保生成的数据具有生物学和诊断学意义上的变异。实验表明,使用合成数据集训练的自监督特征,在数据量减少约60-760倍的情况下,仍能达到与大型真实数据集训练的模型相媲美的性能。值得注意的是,使用合成数据训练的模型在多个评估指标和任务中表现出统计上相当甚至更好的性能,即使与在数量级更大的数据集上训练的模型相比也是如此。合成数据与真实数据相结合的混合方法进一步提高了性能,在多个评估中取得了最佳结果。这些发现强调了生成式AI在为数字病理学创建引人注目的训练数据方面的潜力,显著减少了对大量临床数据集的依赖,并突出了该方法的效率。
🔬 方法详解
问题定义:数字病理学中的深度学习模型依赖于大量的标注数据,但获取和标注病理图像数据成本高昂且耗时。现有方法依赖于大规模真实数据集,但数据集规模与模型性能之间的关系缺乏透明度,简单地增加数据量可能并非总是提升性能的最佳策略。因此,如何利用有限的真实数据,训练出高性能的病理图像分析模型是一个关键问题。
核心思路:本论文的核心思路是利用生成式模型,特别是扩散模型,生成高质量的合成病理图像数据,用于自监督学习。通过在扩散模型的采样过程中引入组织学原型作为引导,确保生成的数据具有生物学和诊断学意义上的变异,从而提高合成数据的质量和多样性。这种方法旨在减少对大规模真实数据集的依赖,同时保持甚至提升下游任务的性能。
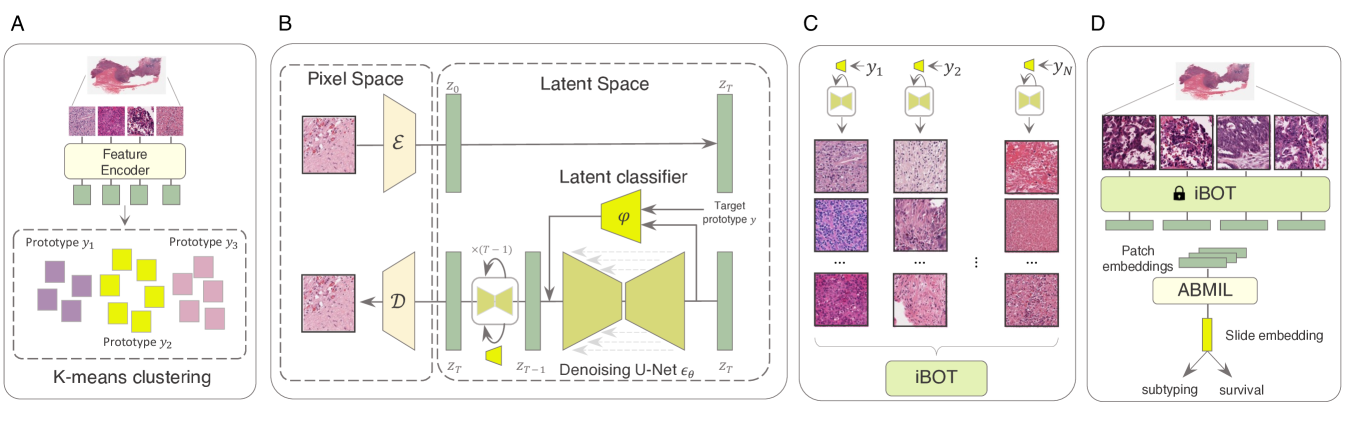
技术框架:该方法主要包含两个阶段:1) 原型学习阶段:利用少量真实病理图像数据学习组织学原型,这些原型代表了不同类型的组织结构或病理特征。2) 扩散模型生成阶段:使用原型引导的扩散模型,以学习到的原型为条件,生成大量的合成病理图像数据。然后,使用这些合成数据进行自监督学习,训练特征提取器。最后,将训练好的特征提取器应用于下游的病理图像分析任务。
关键创新:该方法最重要的技术创新点在于原型引导的扩散模型。传统的扩散模型通常生成随机噪声图像,而该方法通过引入组织学原型作为引导,控制生成图像的内容和结构,从而生成更具生物学意义和诊断价值的合成数据。这种方法能够有效地利用少量真实数据,生成大量高质量的合成数据,从而降低对大规模真实数据集的依赖。
关键设计:在原型学习阶段,可以使用聚类算法(如k-means)或自编码器等方法学习组织学原型。在扩散模型生成阶段,可以使用条件扩散模型,将组织学原型作为条件输入,控制生成过程。损失函数的设计需要考虑合成数据的质量和多样性,可以使用对抗损失、感知损失等方法进行优化。具体的网络结构可以采用U-Net等常用的图像生成模型。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用原型引导的扩散模型生成的合成数据训练的自监督特征,在数据量减少60-760倍的情况下,仍能达到与大型真实数据集训练的模型相媲美的性能。在多个评估指标和任务中,使用合成数据训练的模型表现出统计上相当甚至更好的性能,即使与在数量级更大的数据集上训练的模型相比也是如此。合成数据与真实数据相结合的混合方法进一步提高了性能,在多个评估中取得了最佳结果。
🎯 应用场景
该研究成果可广泛应用于数字病理学领域,例如辅助诊断、疾病预测、药物研发等。通过生成高质量的合成病理图像数据,可以有效解决病理数据获取困难的问题,降低模型训练成本,加速病理图像分析技术的应用。此外,该方法还可以应用于其他医学图像领域,例如放射影像学、眼科图像分析等,具有广阔的应用前景。
📄 摘要(原文)
Foundation models in digital pathology use massive datasets to learn useful compact feature representations of complex histology images. However, there is limited transparency into what drives the correlation between dataset size and performance, raising the question of whether simply adding more data to increase performance is always necessary. In this study, we propose a prototype-guided diffusion model to generate high-fidelity synthetic pathology data at scale, enabling large-scale self-supervised learning and reducing reliance on real patient samples while preserving downstream performance. Using guidance from histological prototypes during sampling, our approach ensures biologically and diagnostically meaningful variations in the generated data. We demonstrate that self-supervised features trained on our synthetic dataset achieve competitive performance despite using ~60x-760x less data than models trained on large real-world datasets. Notably, models trained using our synthetic data showed statistically comparable or better performance across multiple evaluation metrics and tasks, even when compared to models trained on orders of magnitude larger datasets. Our hybrid approach, combining synthetic and real data, further enhanced performance, achieving top results in several evaluations. These findings underscore the potential of generative AI to create compelling training data for digital pathology, significantly reducing the reliance on extensive clinical datasets and highlighting the efficiency of our approach.