In-2-4D: Inbetweening from Two Single-View Images to 4D Generation
作者: Sauradip Nag, Daniel Cohen-Or, Hao Zhang, Ali Mahdavi-Amiri
分类: cs.GR, cs.CV
发布日期: 2025-04-11 (更新: 2025-09-27)
备注: SIGGRAPH ASIA 2025; Project page at https://in-2-4d.github.io/
💡 一句话要点
提出In-2-4D框架,从两张单视角图像生成4D动态场景,实现运动插值。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 4D生成 运动插值 单视角图像 动态3D高斯 视频插值
📋 核心要点
- 现有方法难以仅从两张图像生成复杂、多样的4D动态场景,缺乏对运动过程的精确控制。
- 利用视频插值模型预测运动,通过分层关键帧提取和片段生成,逐步构建动态3D高斯表示。
- 通过时间一致性优化、刚性变换正则化和边界融合,显著提升了生成4D场景的真实性和流畅度。
📝 摘要(中文)
本文提出了一个新问题,In-2-4D,即生成式4D(3D+运动)插值,用于插值两张单视角图像。与仅从文本或单张图像生成视频/4D不同,我们的插值任务可以利用更精确的运动控制来更好地约束生成。给定代表运动对象起始和结束状态的两张单目RGB图像,我们的目标是生成和重建4D运动,而不对对象类别、运动类型、长度或复杂性做任何假设。为了处理这种任意和多样的运动,我们利用基础视频插值模型进行运动预测。然而,大的帧间运动差距可能导致模糊的解释。为此,我们采用分层方法来识别在视觉上接近输入状态同时表现出显著运动的关键帧,然后生成它们之间的平滑片段。对于每个片段,我们使用高斯溅射(3DGS)构建关键帧的3D表示。片段中的时间帧引导运动,使其能够通过变形场转换为动态3DGS。为了提高时间一致性并细化3D运动,我们扩展了多视角扩散的自注意力跨时间步长,并应用刚性变换正则化。最后,我们通过插值边界变形场并优化它们以与引导视频对齐来合并独立生成的3D运动片段,确保平滑且无闪烁的过渡。通过广泛的定性和定量实验以及用户研究,我们证明了我们方法的有效性和设计选择。
🔬 方法详解
问题定义:论文旨在解决从两张单视角RGB图像生成高质量、时间连续的4D动态场景的问题。现有方法通常依赖于文本或单张图像生成视频,缺乏对运动过程的精确控制,难以处理复杂和多样的运动模式,容易产生模糊和不连贯的结果。
核心思路:论文的核心思路是利用视频插值技术,将两张输入图像视为运动的起始和结束状态,通过生成中间帧来重建运动过程。为了应对大运动差距带来的模糊性,采用分层方法,首先识别关键帧,然后生成关键帧之间的平滑运动片段。每个片段使用动态3D高斯表示,并通过时间一致性优化和刚性变换正则化来提高生成质量。
技术框架:整体框架包括以下几个主要阶段:1) 关键帧提取:采用分层方法,从视频插值模型中提取视觉上接近输入图像且具有显著运动的关键帧。2) 片段生成:在关键帧之间生成平滑的运动片段,每个片段对应一段连续的运动。3) 3D表示构建:使用3D高斯溅射(3DGS)构建关键帧的3D表示,并将时间帧引导的运动转换为动态3DGS。4) 时间一致性优化:扩展多视角扩散的自注意力跨时间步长,并应用刚性变换正则化,以提高时间一致性和细化3D运动。5) 片段融合:通过插值边界变形场并优化对齐,将独立生成的3D运动片段合并,确保平滑过渡。
关键创新:该方法的核心创新在于:1) 提出了In-2-4D问题,即从两张单视角图像生成4D动态场景。2) 采用分层关键帧提取和片段生成策略,有效应对了大运动差距带来的模糊性。3) 利用动态3D高斯表示和时间一致性优化,提高了生成4D场景的真实性和流畅度。与现有方法相比,该方法能够更精确地控制运动过程,生成更复杂和多样的动态场景。
关键设计:关键设计包括:1) 使用基础视频插值模型进行运动预测。2) 采用3D高斯溅射(3DGS)进行3D表示。3) 扩展多视角扩散的自注意力跨时间步长。4) 应用刚性变换正则化。5) 通过插值边界变形场并优化对齐来合并片段。具体的参数设置、损失函数和网络结构等细节在论文中有详细描述,此处未知。
🖼️ 关键图片

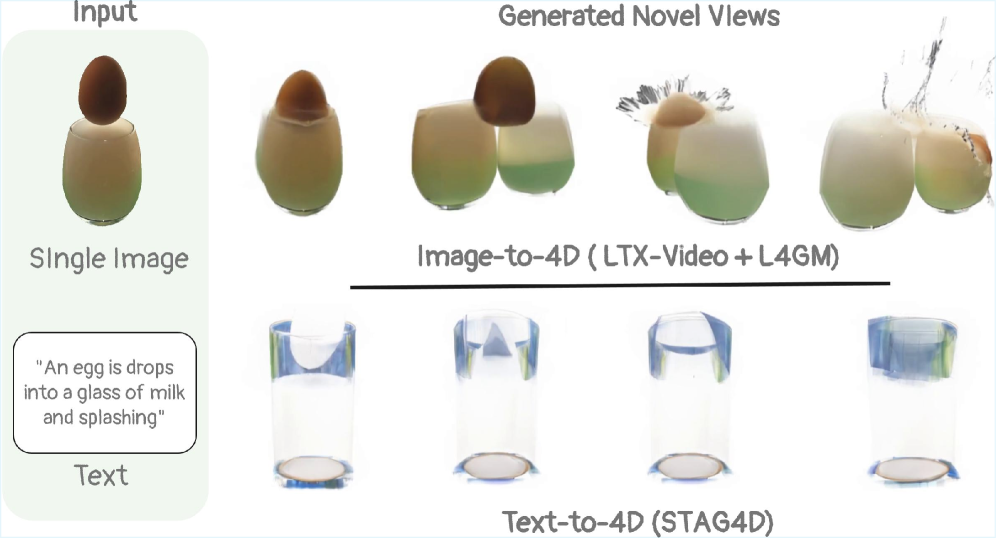
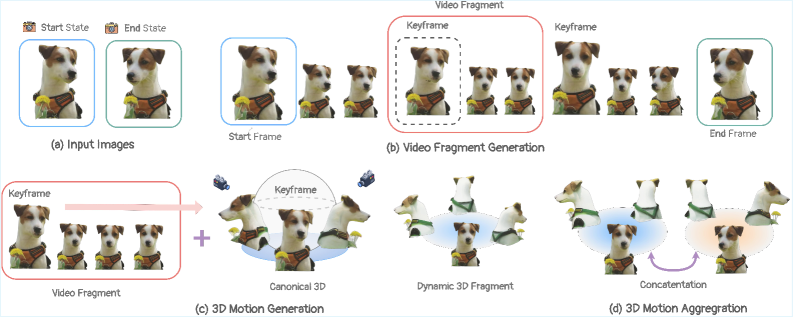
📊 实验亮点
论文通过定性和定量实验以及用户研究,验证了所提出方法的有效性。实验结果表明,该方法能够生成高质量、时间连续的4D动态场景,在视觉效果和运动流畅性方面均优于现有方法。具体的性能数据和对比基线在论文中有详细描述,此处未知。
🎯 应用场景
该研究成果可应用于动画制作、游戏开发、虚拟现实、增强现实等领域。例如,可以根据两张照片自动生成人物或物体的运动动画,或者为游戏中的角色创建更逼真的动态效果。此外,该技术还可以用于视频编辑和修复,例如修复缺失帧或生成慢动作效果。
📄 摘要(原文)
We pose a new problem, In-2-4D, for generative 4D (i.e., 3D + motion) inbetweening to interpolate two single-view images. In contrast to video/4D generation from only text or a single image, our interpolative task can leverage more precise motion control to better constrain the generation. Given two monocular RGB images representing the start and end states of an object in motion, our goal is to generate and reconstruct the motion in 4D, without making assumptions on the object category, motion type, length, or complexity. To handle such arbitrary and diverse motions, we utilize a foundational video interpolation model for motion prediction. However, large frame-to-frame motion gaps can lead to ambiguous interpretations. To this end, we employ a hierarchical approach to identify keyframes that are visually close to the input states while exhibiting significant motions, then generate smooth fragments between them. For each fragment, we construct a 3D representation of the keyframe using Gaussian Splatting (3DGS). The temporal frames within the fragment guide the motion, enabling their transformation into dynamic 3DGS through a deformation field. To improve temporal consistency and refine the 3D motion, we expand the self-attention of multi-view diffusion across timesteps and apply rigid transformation regularization. Finally, we merge the independently generated 3D motion segments by interpolating boundary deformation fields and optimizing them to align with the guiding video, ensuring smooth and flicker-free transitions. Through extensive qualitative and quantitive experiments as well as a user study, we demonstrate the effectiveness of our method and design choices.