ChildlikeSHAPES: Semantic Hierarchical Region Parsing for Animating Figure Drawings
作者: Astitva Srivastava, Harrison Jesse Smith, Thu Nguyen-Phuoc, Yuting Ye
分类: cs.GR
发布日期: 2025-04-10
💡 一句话要点
ChildlikeSHAPES:提出一种语义分层区域解析方法,用于儿童绘画人物的动画制作。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 儿童绘画 语义分割 分层分割 动画制作 SAM 人物动画 数据集 深度学习
📋 核心要点
- 现有语义分割模型难以处理儿童绘画的抽象性和代表性,无法准确分析其内容。
- 提出一种基于SAM的分层分割模型,能够快速准确地获得儿童绘画的语义标签。
- 实验表明,该模型在儿童绘画语义分割任务上优于现有模型,并成功应用于动画制作等领域。
📝 摘要(中文)
儿童人物绘画是人类最具表现力的形式之一,但自动分析其内容仍然是一个巨大的挑战。虽然现实人物的语义分割最近取得了显著进展,但现有模型在面对儿童绘画的抽象性和代表性时常常失效。语义理解是动画工具修改人物并保持其独特风格的关键前提。为此,我们提出了一种新的分层分割模型,该模型基于架构和预训练的SAM,以快速准确地获得这些语义标签。我们的模型比专注于现实人物和卡通人物的最先进的分割模型具有更高的准确性,即使经过微调也是如此。我们通过多个应用证明了我们的模型在语义分割方面的价值:全自动面部动画流程、人物重新照明流程、对现有儿童人物绘画动画方法的改进以及对领域外人物的泛化。最后,为了支持该领域的未来工作,我们引入了一个包含16,000个儿童绘画的数据集,其中包含25个语义类别的像素级注释。我们的工作可以为手绘角色动画提供全新的、易于访问的工具,我们的数据集可以为各种图形和以人为中心的研究领域开辟新的研究方向。
🔬 方法详解
问题定义:论文旨在解决儿童绘画人物的自动语义分割问题。现有方法,特别是那些为真实人物或卡通人物设计的分割模型,在处理儿童绘画时表现不佳,因为儿童绘画具有高度抽象和风格化的特点,缺乏真实感和细节。这阻碍了自动动画工具对儿童绘画的理解和操作。
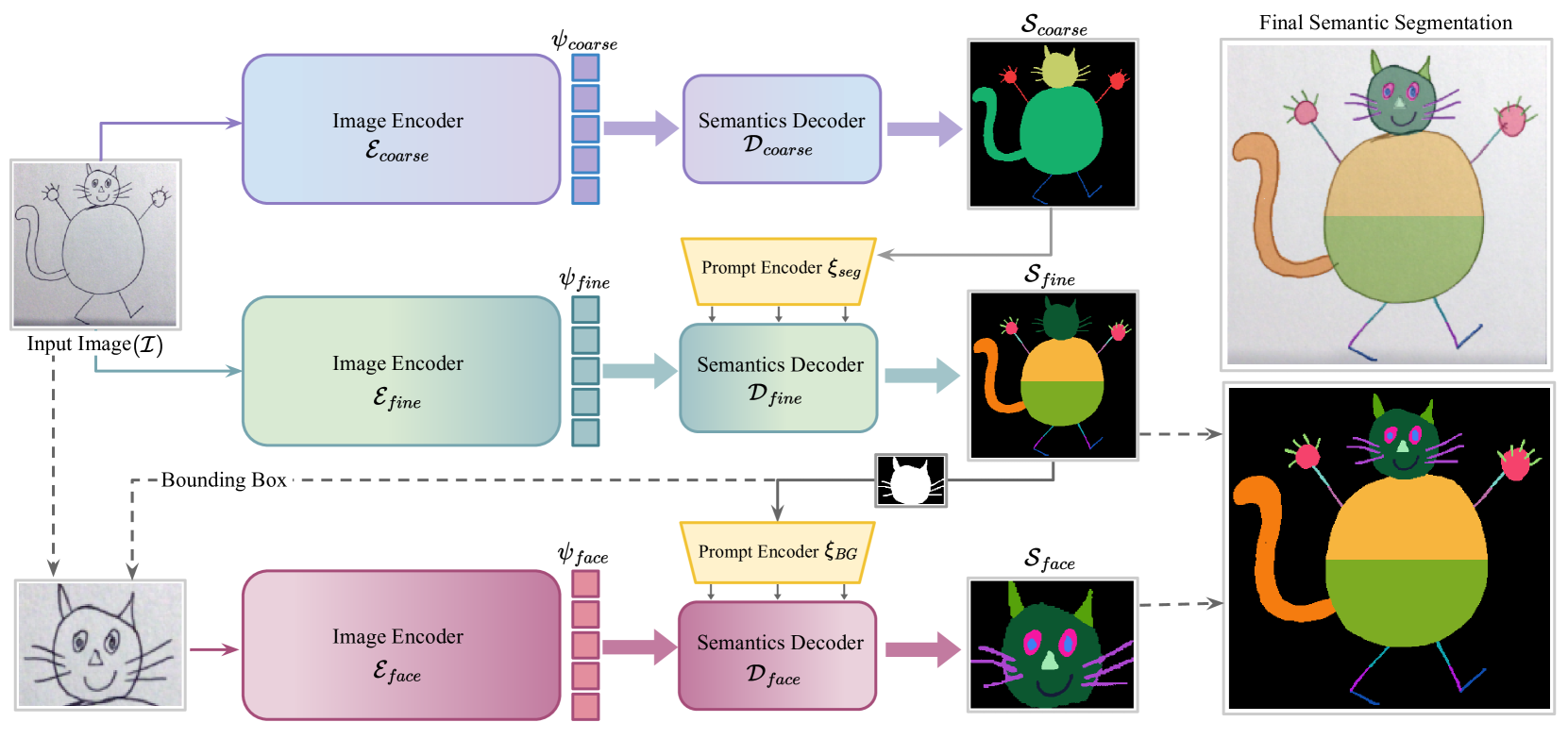
核心思路:论文的核心思路是利用预训练的Segment Anything Model (SAM) 的强大泛化能力,并在此基础上构建一个分层分割模型,以适应儿童绘画的特点。通过分层结构,模型能够逐步细化分割结果,从而更准确地识别不同的语义区域。
技术框架:该模型基于SAM的架构,并进行修改以适应分层分割的需求。整体流程包括:1) 使用SAM生成初始分割掩码;2) 利用分层结构对初始掩码进行细化,逐步将图像分割成更小的语义区域;3) 使用像素级注释的数据集对模型进行微调,以提高其在儿童绘画上的性能。
关键创新:该论文的关键创新在于将SAM应用于儿童绘画的语义分割,并设计了一个分层分割框架来提高分割精度。与直接使用现有分割模型相比,该方法能够更好地处理儿童绘画的抽象性和风格化特点。
关键设计:论文的关键设计包括:1) 使用预训练的SAM作为基础模型,以利用其强大的泛化能力;2) 设计分层分割结构,逐步细化分割结果;3) 构建包含16,000个儿童绘画的数据集,并进行像素级注释,用于模型的微调和评估;4) 损失函数的设计可能包括交叉熵损失或Dice损失,以优化分割结果。
🖼️ 关键图片


📊 实验亮点
该模型在儿童绘画语义分割任务上取得了显著的性能提升,优于现有的最先进的分割模型,即使在这些模型经过微调后也是如此。论文构建了一个包含16,000个儿童绘画的数据集,并进行了像素级注释,为该领域的研究提供了宝贵的数据资源。此外,该模型成功应用于多个实际应用场景,包括全自动面部动画、人物重新照明和现有动画方法的改进,验证了其有效性和实用性。
🎯 应用场景
该研究成果可应用于手绘角色动画制作、儿童绘画辅助创作、以及其他需要理解和操作儿童绘画的领域。例如,可以开发自动面部动画工具,根据儿童绘画自动生成动画表情;可以用于人物重新照明,改变绘画的光照效果;还可以改进现有的儿童绘画动画方法,提高动画的质量和效率。该研究为开发易于访问的手绘角色动画工具奠定了基础,并为图形学和以人为中心的研究开辟了新的方向。
📄 摘要(原文)
Childlike human figure drawings represent one of humanity's most accessible forms of character expression, yet automatically analyzing their contents remains a significant challenge. While semantic segmentation of realistic humans has recently advanced considerably, existing models often fail when confronted with the abstract, representational nature of childlike drawings. This semantic understanding is a crucial prerequisite for animation tools that seek to modify figures while preserving their unique style. To help achieve this, we propose a novel hierarchical segmentation model, built upon the architecture and pre-trained SAM, to quickly and accurately obtain these semantic labels. Our model achieves higher accuracy than state-of-the-art segmentation models focused on realistic humans and cartoon figures, even after fine-tuning. We demonstrate the value of our model for semantic segmentation through multiple applications: a fully automatic facial animation pipeline, a figure relighting pipeline, improvements to an existing childlike human figure drawing animation method, and generalization to out-of-domain figures. Finally, to support future work in this area, we introduce a dataset of 16,000 childlike drawings with pixel-level annotations across 25 semantic categories. Our work can enable entirely new, easily accessible tools for hand-drawn character animation, and our dataset can enable new lines of inquiry in a variety of graphics and human-centric research fields.