PASE: Phoneme-Aware Speech Encoder to Improve Lip Sync Accuracy for Talking Head Synthesis
作者: Yihuan Huang, Jiajun Liu, Yanzhen Ren, Jun Xue, Wuyang Liu, Zongkun Sun
分类: cs.GR, cs.CV
发布日期: 2025-04-08 (更新: 2025-10-15)
💡 一句话要点
提出PASE:一种音素感知语音编码器,提升说话人头部合成的唇形同步精度
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 说话人头部合成 唇形同步 音素感知 语音编码器 对比学习
📋 核心要点
- 现有说话人头部合成方法在音素-口型对齐上存在模糊性,导致唇形同步不准确。
- PASE模型显式引入音素嵌入作为对齐锚点,并使用对比学习增强视听对区分性。
- 实验表明,PASE显著提升了唇形同步精度,优于传统方法,且易于集成。
📝 摘要(中文)
本文提出了一种名为PASE(音素感知语音编码器)的新型语音表示模型,旨在弥合音素和口型之间的差距,从而提高说话人头部合成的唇形同步精度。现有的头部合成方法通常采用大规模预训练声学模型提取的语音特征,但语音和唇部运动之间固有的多对多关系会导致音素-口型对齐模糊,进而导致不准确和不稳定的嘴唇运动。PASE显式地引入音素嵌入作为对齐锚点,并采用对比对齐模块来增强相应视听对之间的可区分性。此外,还设计了一个预测和重建任务,以提高在噪声和部分模态缺失下的鲁棒性。实验结果表明,PASE显著提高了唇形同步精度,并在基于NeRF和基于3DGS的渲染框架中均实现了最先进的性能,分别优于基于声学特征的传统方法13.7%和14.2%。重要的是,PASE可以无缝集成到各种说话人头部生成流程中,以提高唇形同步精度,而无需修改架构。
🔬 方法详解
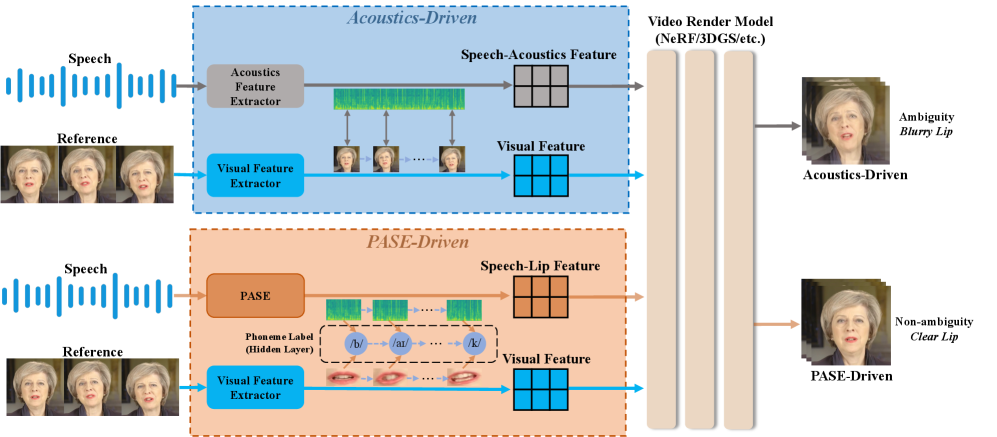
问题定义:说话人头部合成任务中,语音到唇部动作的映射存在多对多的关系,导致音素和口型之间的对应关系模糊不清,进而影响唇形同步的准确性和稳定性。现有方法依赖于大规模预训练声学模型提取的语音特征,但未能有效解决这种模糊性,导致合成的唇部动作不够自然和准确。
核心思路:PASE的核心思路是显式地利用音素信息作为对齐的锚点,从而缩小音素和口型之间的语义差距。通过引入音素嵌入,并设计对比学习目标,使得模型能够更好地学习到语音和唇部动作之间的对应关系,从而提高唇形同步的准确性。
技术框架:PASE模型主要包含以下几个模块:1) 音素嵌入模块:将音素序列转换为音素嵌入向量。2) 语音编码器:将输入的语音信号编码成语音特征表示。3) 对比对齐模块:利用音素嵌入作为锚点,通过对比学习的方式,增强语音特征和对应唇部动作之间的关联性。4) 预测和重建模块:通过预测音素和重建语音信号,提高模型在噪声和模态缺失情况下的鲁棒性。
关键创新:PASE的关键创新在于显式地将音素信息引入到语音编码过程中,并利用对比学习来增强音素和口型之间的对齐。与传统的声学特征相比,音素嵌入能够提供更明确的语义信息,从而更好地指导唇部动作的生成。此外,预测和重建任务的引入也提高了模型的鲁棒性。
关键设计:对比对齐模块使用InfoNCE损失函数,鼓励模型学习到正样本(对应的语音和唇部动作)之间更近的距离,以及负样本(不对应的语音和唇部动作)之间更远的距离。预测和重建任务通过最小化预测音素和真实音素之间的交叉熵损失,以及重建语音信号和原始语音信号之间的均方误差损失来实现。
🖼️ 关键图片

📊 实验亮点
实验结果表明,PASE在NeRF和3DGS两种渲染框架下,唇形同步精度分别优于传统基于声学特征的方法13.7%和14.2%,达到了最先进的水平。这些结果验证了PASE在提高唇形同步精度方面的有效性,并表明其可以无缝集成到不同的说话人头部生成流程中。
🎯 应用场景
PASE模型可广泛应用于虚拟形象生成、视频会议、游戏、电影制作等领域,能够显著提升数字人物的真实感和交互体验。通过提高唇形同步的准确性,PASE有助于创建更自然、更具表现力的虚拟角色,从而增强用户在各种应用场景中的沉浸感和参与度。
📄 摘要(原文)
Recent talking head synthesis works typically adopt speech features extracted from large-scale pre-trained acoustic models. However, the intrinsic many-to-many relationship between speech and lip motion causes phoneme-viseme alignment ambiguity, leading to inaccurate and unstable lips. To further improve lip sync accuracy, we propose PASE (Phoneme-Aware Speech Encoder), a novel speech representation model that bridges the gap between phonemes and visemes. PASE explicitly introduces phoneme embeddings as alignment anchors and employs a contrastive alignment module to enhance the discriminability between corresponding audio-visual pairs. In addition, a prediction and reconstruction task is designed to improve robustness under noise and partial modality absence. Experimental results show PASE significantly improves lip sync accuracy and achieves state-of-the-art performance across both NeRF- and 3DGS-based rendering frameworks, outperforming conventional methods based on acoustic features by 13.7 % and 14.2 %, respectively. Importantly, PASE can be seamlessly integrated into diverse talking head pipelines to improve the lip sync accuracy without architectural modifications.