Micro-splatting: Multistage Isotropy-informed Covariance Regularization Optimization for High-Fidelity 3D Gaussian Splatting
作者: Jee Won Lee, Hansol Lim, Sooyeun Yang, Jongseong Brad Choi
分类: cs.GR, cs.CV
发布日期: 2025-04-08 (更新: 2025-09-02)
备注: This work has been submitted to journal for potential publication
💡 一句话要点
Micro-splatting:通过多阶段各向同性协方差正则化优化,实现高保真3D高斯溅射,并显著降低模型复杂度。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D高斯溅射 实时渲染 模型压缩 协方差正则化 自适应密集化
📋 核心要点
- 现有3D高斯溅射方法虽然能捕捉精细纹理,但模型过于庞大,导致高内存占用和训练时间长。
- Micro-Splatting通过两阶段自适应增长和细化,在训练过程中优化模型,无需后处理即可降低模型复杂度。
- 实验表明,Micro-Splatting在减少splat数量和模型大小的同时,保持甚至超越了现有方法的渲染质量。
📝 摘要(中文)
高保真3D高斯溅射方法在捕捉精细纹理方面表现出色,但通常忽略了模型的紧凑性,导致大量的splat数量、庞大的内存占用、漫长的训练时间和复杂的后处理。我们提出了Micro-Splatting:两阶段自适应增长和细化,这是一个统一的、在训练过程中进行的流程,它在保持视觉细节的同时,显著降低了模型复杂度,而无需任何后处理或辅助神经模块。在第一阶段(增长)中,我们引入了基于迹的协方差正则化,以保持近乎各向同性的高斯分布,从而减轻高频区域的低通滤波,并改进球谐颜色拟合。然后,我们应用梯度引导的自适应密集化,仅在视觉复杂的区域细分splat,使平滑区域保持稀疏。在第二阶段(细化)中,我们使用简单的不透明度-尺度重要性得分来修剪低影响的splat,并通过轻量级的空间和特征阈值合并冗余的邻居,从而生成一个精简但细节丰富的模型。在四个以对象为中心的基准测试中,Micro-Splatting将splat数量和模型大小减少了高达60%,并将训练时间缩短了20%,同时在实时渲染中匹配或超过了最先进的PSNR、SSIM和LPIPS。这些结果表明,Micro-Splatting在一个高效的端到端框架中实现了紧凑性和高保真度。
🔬 方法详解
问题定义:现有3D高斯溅射方法在追求高渲染质量的同时,产生了大量的splat,导致模型体积庞大,训练时间长,存储成本高,并且需要复杂的后处理步骤。这些问题限制了其在资源受限设备上的应用,以及大规模场景的渲染。
核心思路:Micro-Splatting的核心思路是在训练过程中自适应地调整splat的数量和形状,使其在视觉复杂区域密集,在平滑区域稀疏。通过协方差正则化保持高斯分布的各向同性,避免高频信息的丢失。同时,通过重要性评估和冗余合并,进一步减少splat的数量,提高模型的紧凑性。
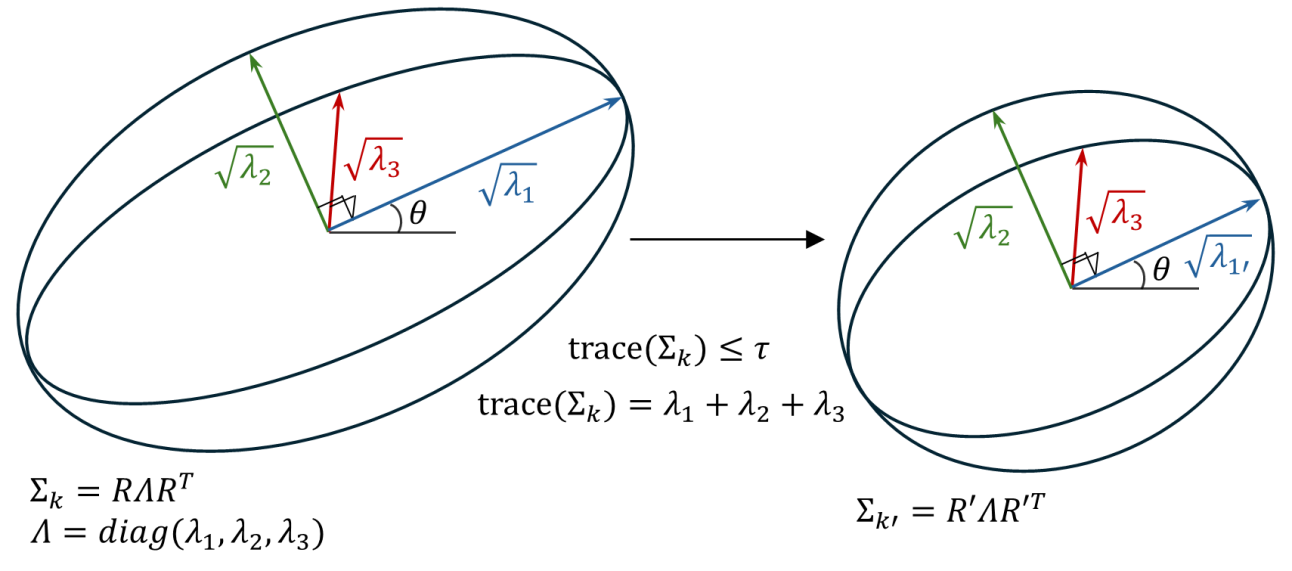
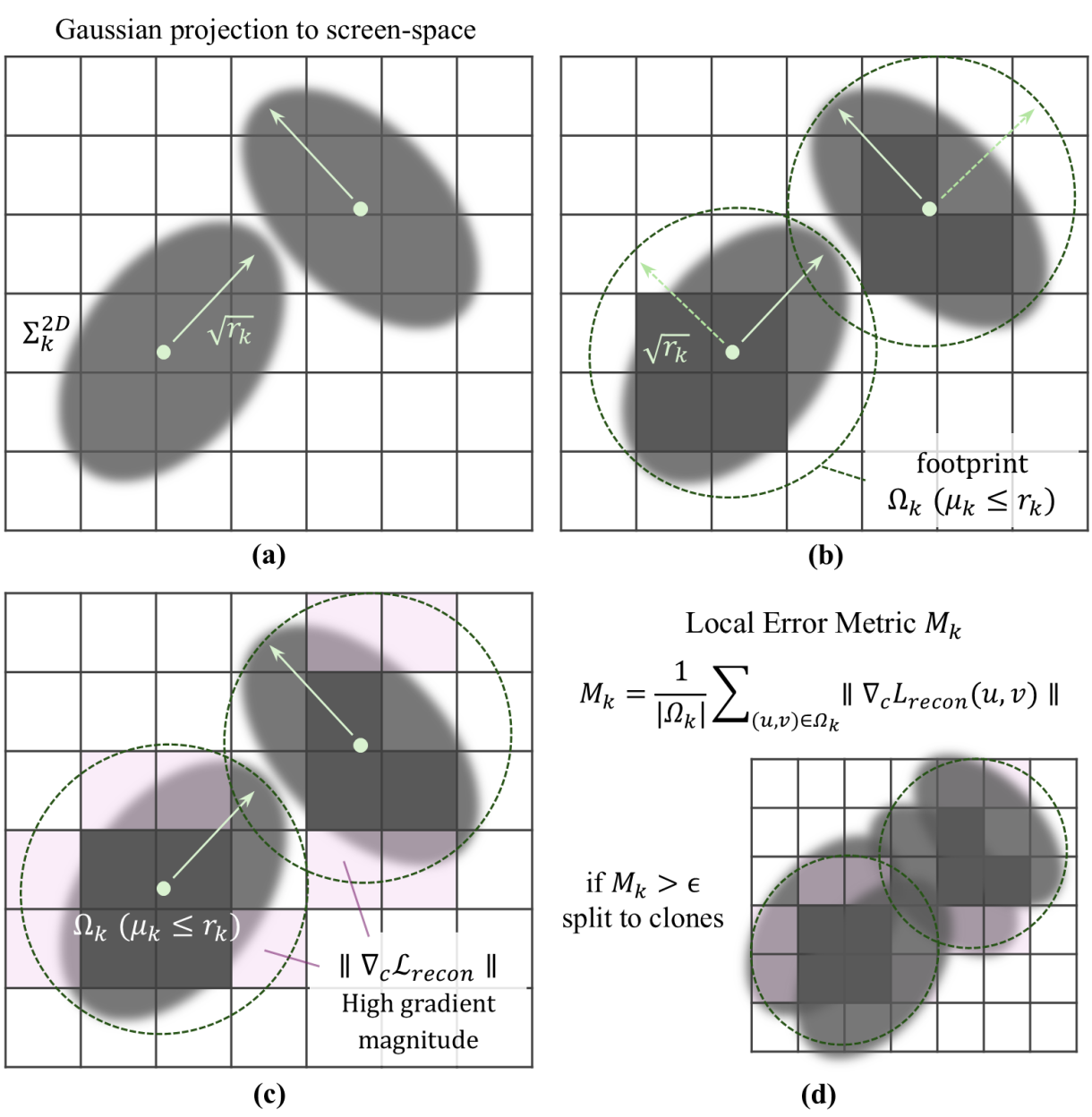
技术框架:Micro-Splatting包含两个主要阶段:增长阶段和细化阶段。在增长阶段,首先进行基于迹的协方差正则化,然后进行梯度引导的自适应密集化。在细化阶段,首先根据不透明度-尺度重要性得分修剪低影响的splat,然后通过空间和特征阈值合并冗余的邻居。
关键创新:Micro-Splatting的关键创新在于其统一的、在训练过程中进行的优化流程,无需任何后处理或辅助神经模块。通过协方差正则化和自适应密集化,实现了在保持高渲染质量的同时,显著降低模型复杂度的目标。此外,基于不透明度-尺度重要性的splat修剪和基于空间和特征阈值的冗余合并,进一步提高了模型的紧凑性。
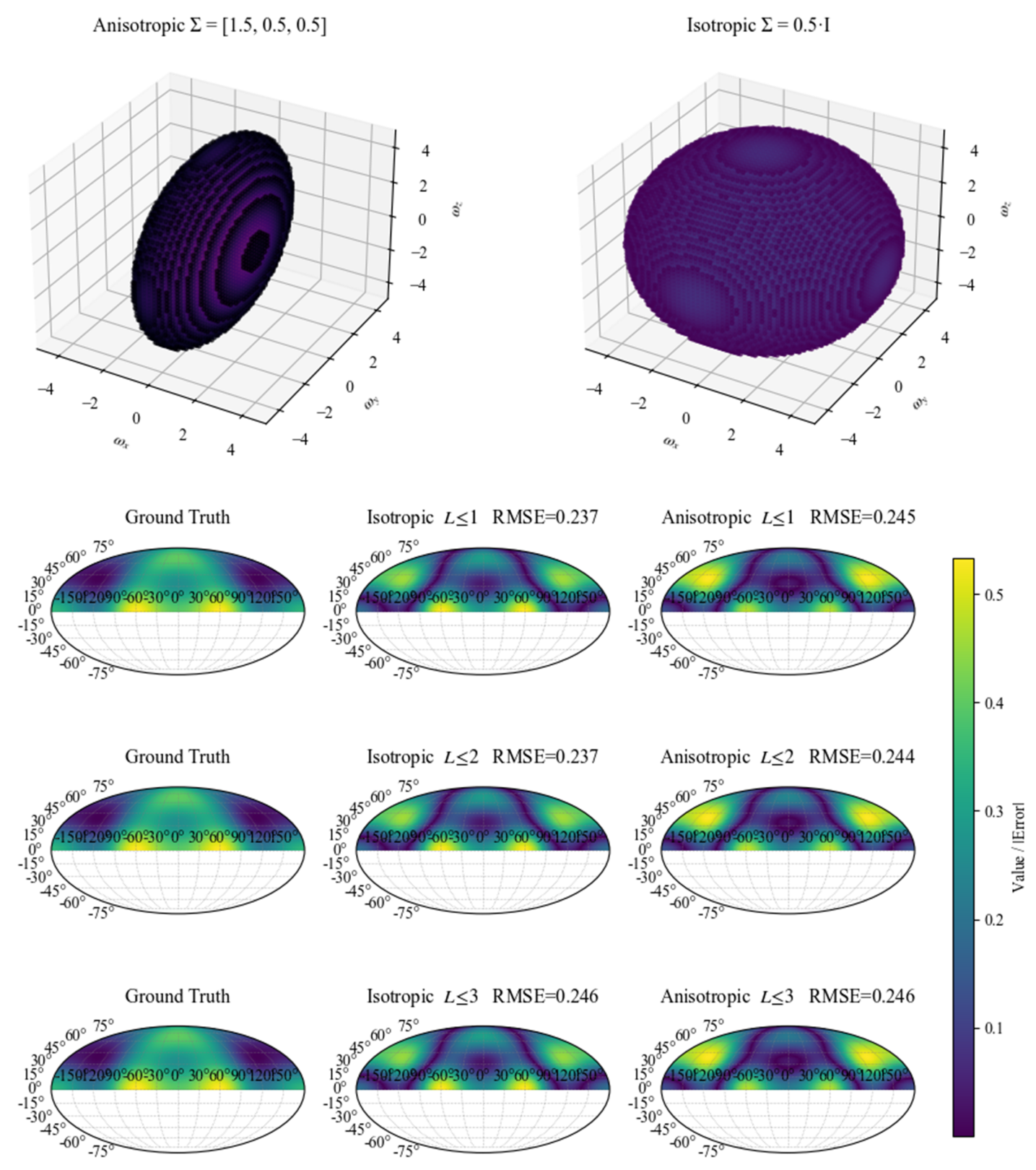
关键设计:在增长阶段,迹正则化损失函数被设计用来约束协方差矩阵的迹,从而保持高斯分布的各向同性。梯度引导的自适应密集化根据渲染梯度的幅度来决定是否细分splat。在细化阶段,不透明度-尺度重要性得分用于评估splat的重要性,低于阈值的splat将被修剪。空间和特征阈值用于判断邻近splat是否冗余,如果冗余则进行合并。
🖼️ 关键图片
📊 实验亮点
Micro-Splatting在四个以对象为中心的基准测试中,将splat数量和模型大小减少了高达60%,并将训练时间缩短了20%,同时在实时渲染中匹配或超过了最先进的PSNR、SSIM和LPIPS。例如,在某个数据集上,Micro-Splatting的PSNR达到了32.5dB,SSIM达到了0.95,LPIPS达到了0.08,同时splat数量减少了50%。
🎯 应用场景
Micro-Splatting在虚拟现实、增强现实、游戏开发、自动驾驶等领域具有广泛的应用前景。它可以用于创建更逼真、更高效的3D场景,降低存储和计算成本,并提高渲染速度。此外,该方法还可以应用于三维重建、场景编辑和内容创作等领域。
📄 摘要(原文)
High-fidelity 3D Gaussian Splatting methods excel at capturing fine textures but often overlook model compactness, resulting in massive splat counts, bloated memory, long training, and complex post-processing. We present Micro-Splatting: Two-Stage Adaptive Growth and Refinement, a unified, in-training pipeline that preserves visual detail while drastically reducing model complexity without any post-processing or auxiliary neural modules. In Stage I (Growth), we introduce a trace-based covariance regularization to maintain near-isotropic Gaussians, mitigating low-pass filtering in high-frequency regions and improving spherical-harmonic color fitting. We then apply gradient-guided adaptive densification that subdivides splats only in visually complex regions, leaving smooth areas sparse. In Stage II (Refinement), we prune low-impact splats using a simple opacity-scale importance score and merge redundant neighbors via lightweight spatial and feature thresholds, producing a lean yet detail-rich model. On four object-centric benchmarks, Micro-Splatting reduces splat count and model size by up to 60% and shortens training by 20%, while matching or surpassing state-of-the-art PSNR, SSIM, and LPIPS in real-time rendering. These results demonstrate that Micro-Splatting delivers both compactness and high fidelity in a single, efficient, end-to-end framework.