Imperative vs. Declarative Programming Paradigms for Open-Universe Scene Generation
作者: Maxim Gumin, Do Heon Han, Seung Jean Yoo, Aditya Ganeshan, R. Kenny Jones, Rio Aguina-Kang, Stewart Morris, Daniel Ritchie
分类: cs.GR, cs.PL
发布日期: 2025-04-07 (更新: 2025-10-17)
💡 一句话要点
提出基于命令式编程范式的开放域场景生成方法,显著提升场景布局质量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D场景生成 命令式编程 大型语言模型 错误纠正 场景布局
📋 核心要点
- 现有3D场景生成方法主要采用声明式编程,依赖LLM指定约束,再由求解器解决,难以生成复杂场景。
- 本文提出命令式编程方法,利用LLM生成逐步放置对象的程序,简化场景规范,实现复杂布局。
- 引入LLM-free的错误纠正机制,优化代码解决碰撞等问题。实验表明,该方法显著优于现有声明式方法。
📝 摘要(中文)
本文挑战了当前主流的声明式编程范式,提出了一种更直接的命令式方法用于生成3D场景布局。该方法利用大型语言模型(LLM)生成逐步程序,迭代地将每个对象相对于场景中已存在的对象进行放置。这种范式简化了底层的场景规范语言,从而能够创建更复杂、多样化和高度结构化的布局,这些布局难以用声明式方法表达。为了提高鲁棒性,本文还提出了一种新颖的、无需LLM的错误纠正机制,该机制直接作用于生成的代码,迭代地调整程序中的参数以解决碰撞和其他不一致性。在强制选择感知研究中,人类参与者绝大多数更喜欢本文提出的命令式布局,选择率分别比两个最先进的声明式系统高82%和94%,证明了这种替代范式的巨大潜力。最后,本文提出了一种简单的自动化评估指标,用于3D场景布局生成,该指标与人类判断高度相关。
🔬 方法详解
问题定义:现有3D场景生成方法主要采用声明式编程范式,即先由大型语言模型(LLM)定义场景的高级约束,然后由单独的求解器来解析这些约束并生成场景布局。这种方法在处理复杂、结构化的场景时存在局限性,因为声明式方法难以精确表达对象之间的复杂关系和依赖。
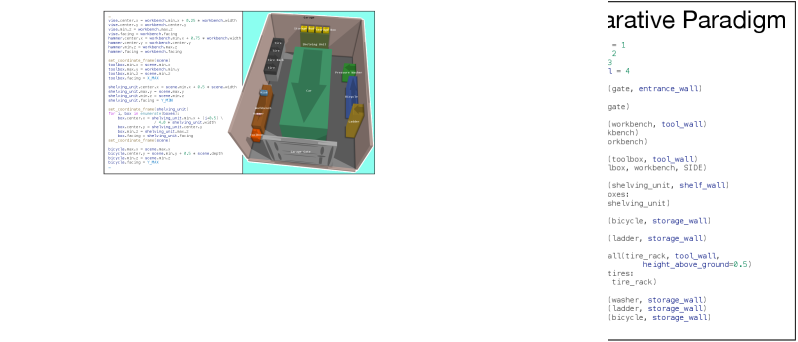
核心思路:本文的核心思路是采用命令式编程范式,将场景生成过程转化为一个逐步构建场景的程序。具体来说,利用LLM生成一段代码,该代码包含一系列指令,用于按顺序将对象放置到场景中,每个对象的放置都依赖于之前已放置的对象。这种方法允许更精细的控制和更灵活的场景构建。
技术框架:整体框架包括两个主要阶段:1) LLM代码生成阶段:使用LLM生成一段Python代码,该代码包含一系列放置对象的指令。每个指令指定了要放置的对象类型、位置、旋转等参数,以及相对于其他已存在对象的关系。2) 代码执行与错误纠正阶段:执行生成的代码,并在执行过程中检测和纠正错误,例如对象碰撞。错误纠正机制是一个无需LLM的模块,它通过迭代地调整代码中的参数来解决这些问题。
关键创新:最重要的技术创新点在于采用命令式编程范式进行场景生成。与声明式方法相比,命令式方法允许更直接、更精细地控制场景的构建过程,从而能够生成更复杂、结构化的场景。此外,LLM-free的错误纠正机制也是一个重要的创新,它提高了生成场景的鲁棒性和质量。
关键设计:在LLM代码生成阶段,使用了经过微调的LLM,使其能够生成符合特定规范的Python代码。代码中的每个对象放置指令都包含对象类型、位置、旋转等参数,这些参数可以通过LLM直接生成,也可以通过错误纠正机制进行调整。错误纠正机制使用基于梯度的优化方法,迭代地调整参数以最小化碰撞等错误。
🖼️ 关键图片


📊 实验亮点
实验结果表明,本文提出的命令式方法在生成3D场景布局方面显著优于现有的声明式方法。在人类感知研究中,参与者选择本文方法生成的布局的比例分别比两个最先进的声明式系统高82%和94%。此外,本文还提出了一种与人类判断高度相关的自动化评估指标,为3D场景布局生成的研究提供了新的评估工具。
🎯 应用场景
该研究成果可应用于虚拟现实、游戏开发、机器人仿真等领域。通过自动生成逼真、复杂的3D场景,可以降低内容创作成本,提高用户体验。此外,该方法还可以用于训练机器人,使其能够在各种虚拟环境中进行学习和测试。
📄 摘要(原文)
Current methods for generating 3D scene layouts from text predominantly follow a declarative paradigm, where a Large Language Model (LLM) specifies high-level constraints that are then resolved by a separate solver. This paper challenges that consensus by introducing a more direct, imperative approach. We task an LLM with generating a step-by-step program that iteratively places each object relative to those already in the scene. This paradigm simplifies the underlying scene specification language, enabling the creation of more complex, varied, and highly structured layouts that are difficult to express declaratively. To improve the robustness, we complement our method with a novel, LLM-free error correction mechanism that operates directly on the generated code, iteratively adjusting parameters within the program to resolve collisions and other inconsistencies. In forced-choice perceptual studies, human participants overwhelmingly preferred our imperative layouts, choosing them over those from two state-of-the-art declarative systems 82% and 94% of the time, demonstrating the significant potential of this alternative paradigm. Finally, we present a simple automated evaluation metric for 3D scene layout generation that correlates strongly with human judgment.