Gen-C: Populating Virtual Worlds with Generative Crowds
作者: Andreas Panayiotou, Panayiotis Charalambous, Ioannis Karamouzas
分类: cs.GR, cs.LG
发布日期: 2025-04-02 (更新: 2025-10-14)
备注: 11 pages
💡 一句话要点
Gen-C:提出生成式人群框架,用于填充具有交互行为的虚拟世界。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 生成式模型 人群模拟 大型语言模型 图神经网络 虚拟世界
📋 核心要点
- 现有群体模拟方法侧重于低级任务,难以模拟智能体间和环境交互产生的高级行为。
- Gen-C利用大型语言模型生成合成数据,并提出时间扩展图表示,学习人群交互模式。
- 实验表明,Gen-C能生成异构人群和连贯交互,模拟真实世界群体的高级决策。
📝 摘要(中文)
过去二十年,基于智能体的群体模拟取得了显著进展,但大多集中在避碰、路径跟随和集群等底层任务。然而,逼真的模拟需要对智能体之间以及智能体与环境之间随时间推移的交互所产生的高级行为进行建模。我们提出了生成式人群(Gen-C),这是一个生成式框架,用于生成捕捉智能体-智能体和智能体-环境交互的群体场景,从而形成连贯的高级群体计划。为了避免收集和标注真实群体视频数据的人工密集型过程,我们利用大型语言模型(LLM)来引导合成群体场景数据集。我们提出了一种时间扩展图表示,编码了动作、交互和空间上下文。Gen-C采用双变分图自动编码器(VGAE)架构,该架构联合学习连接模式和节点特征,并以文本和结构信号为条件,克服了直接LLM生成的局限性,从而实现可扩展的、环境感知的多智能体群体模拟。我们在具有多样化行为的场景(如大学校园和火车站)中展示了Gen-C的有效性,表明它可以生成异构人群、连贯的交互以及与真实世界群体动态一致的高级决策模式。
🔬 方法详解
问题定义:现有群体模拟方法主要关注低层次的运动规划,例如避障和路径跟随,缺乏对人群高级行为的建模能力,难以模拟真实世界中个体之间的复杂交互以及个体与环境的互动。人工标注真实人群数据成本高昂,限制了模型训练的规模和泛化能力。
核心思路:Gen-C的核心思路是利用大型语言模型(LLM)生成合成的群体场景数据,并在此基础上训练一个生成模型,用于生成具有真实感和连贯性的虚拟人群。通过LLM生成数据,避免了人工标注的成本,并可以方便地生成各种场景和行为。模型学习人群中个体之间的关系以及个体与环境的交互,从而生成更逼真的群体行为。
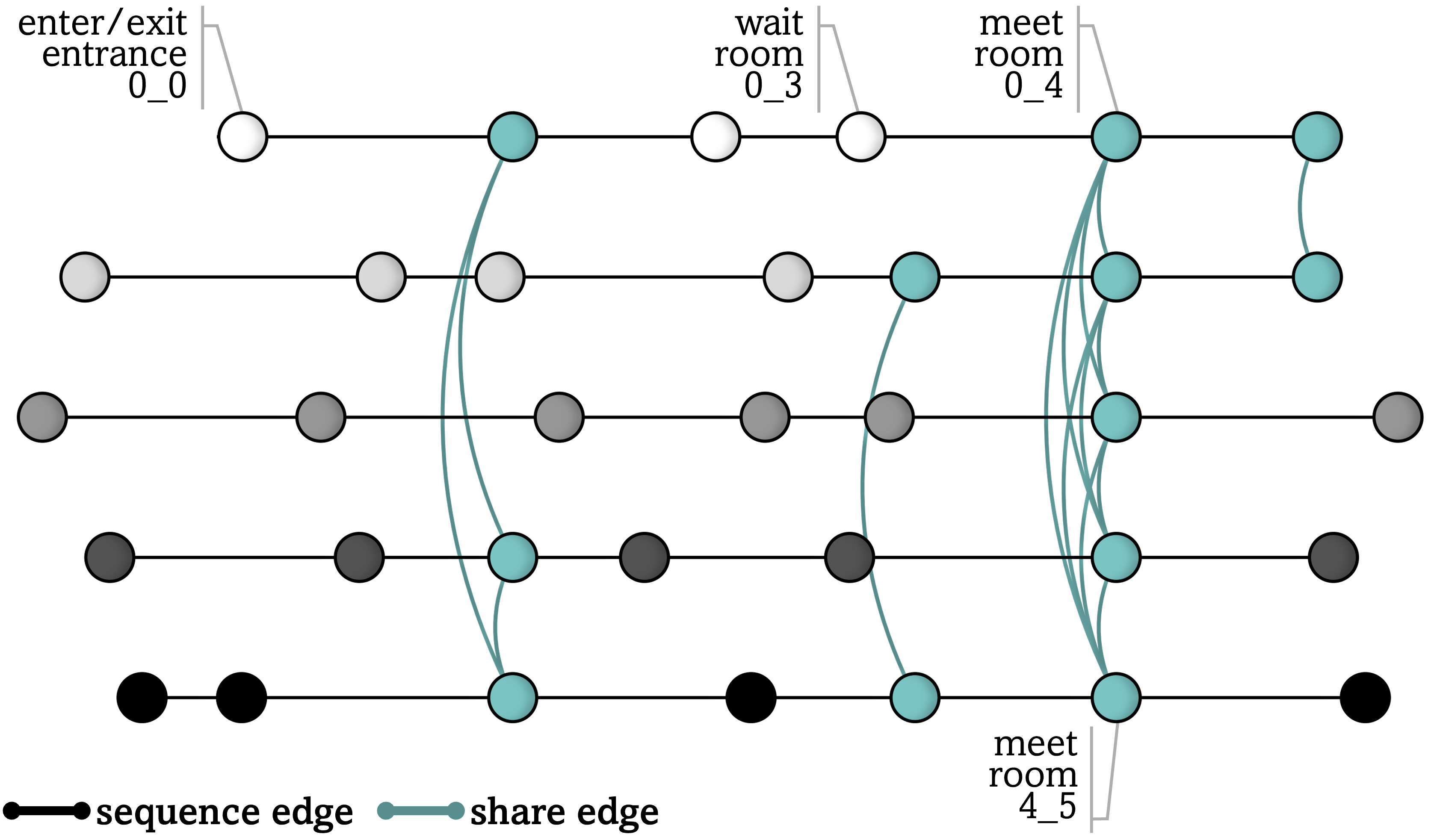
技术框架:Gen-C的整体框架包括以下几个主要阶段:1) 使用LLM生成群体场景的文本描述;2) 将文本描述转换为时间扩展图表示,其中节点表示个体在不同时刻的状态,边表示个体之间的交互和个体与环境的交互;3) 使用双变分图自动编码器(VGAE)学习图的结构和节点特征,从而生成新的群体场景;4) 将生成的图转换为虚拟人群的运动轨迹。
关键创新:Gen-C的关键创新在于:1) 利用LLM生成合成数据,降低了数据获取成本;2) 提出时间扩展图表示,有效地编码了人群的动态交互;3) 采用双VGAE架构,联合学习图的结构和节点特征,提高了生成模型的性能。与直接使用LLM生成轨迹相比,Gen-C能够更好地保证生成人群行为的连贯性和环境感知能力。
关键设计:时间扩展图中的节点特征包括个体的位置、速度、目标等信息。边分为两种类型:个体之间的交互边和个体与环境的交互边。双VGAE架构包括两个编码器和一个解码器,分别用于学习图的结构和节点特征。损失函数包括重构损失和KL散度损失,用于保证生成数据的质量和多样性。具体参数设置未知。
🖼️ 关键图片


📊 实验亮点
论文在大学校园和火车站等场景下进行了实验,结果表明Gen-C能够生成具有异构行为的人群,并模拟出与真实世界人群动态一致的高级决策模式。具体性能数据未知,但视觉效果上,生成的人群行为更加自然和合理,优于直接使用LLM生成的结果。与现有方法相比,Gen-C能够更好地模拟人群的交互行为和环境感知能力。
🎯 应用场景
Gen-C可应用于虚拟现实、游戏开发、电影制作等领域,用于生成逼真的人群场景。例如,在城市规划模拟中,可以使用Gen-C生成不同人群在城市中的行为模式,从而评估城市设计的合理性。在游戏开发中,可以使用Gen-C生成具有真实感和多样性的人群角色,提高游戏的沉浸感。该技术还有潜力用于训练自动驾驶系统,模拟复杂交通场景。
📄 摘要(原文)
Over the past two decades, researchers have made significant steps in simulating agent-based human crowds, yet most efforts remain focused on low-level tasks such as collision avoidance, path following, and flocking. Realistic simulations, however, require modeling high-level behaviors that emerge from agents interacting with each other and with their environment over time. We introduce Generative Crowds (Gen-C), a generative framework that produces crowd scenarios capturing agent-agent and agent-environment interactions, shaping coherent high-level crowd plans. To avoid the labor-intensive process of collecting and annotating real crowd video data, we leverage large language models (LLMs) to bootstrap synthetic datasets of crowd scenarios. We propose a time-expanded graph representation, encoding actions, interactions, and spatial context. Gen-C employs a dual Variational Graph Autoencoder (VGAE) architecture that jointly learns connectivity patterns and node features conditioned on textual and structural signals, overcoming the limitations of direct LLM generation to enable scalable, environment-aware multi-agent crowd simulations. We demonstrate the effectiveness of Gen-C on scenarios with diverse behaviors such as a University Campus and a Train Station, showing that it generates heterogeneous crowds, coherent interactions, and high-level decision-making patterns consistent with real-world crowd dynamics.