Progressive Rendering Distillation: Adapting Stable Diffusion for Instant Text-to-Mesh Generation without 3D Data
作者: Zhiyuan Ma, Xinyue Liang, Rongyuan Wu, Xiangyu Zhu, Zhen Lei, Lei Zhang
分类: cs.GR, cs.AI, cs.CV
发布日期: 2025-03-27
备注: Accepted to CVPR 2025. Code:https://github.com/theEricMa/TriplaneTurbo. Demo:https://huggingface.co/spaces/ZhiyuanthePony/TriplaneTurbo
🔗 代码/项目: GITHUB
💡 一句话要点
提出渐进渲染蒸馏(PRD),实现无需3D数据的快速文本到网格生成。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 文本到3D生成 扩散模型 渐进渲染蒸馏 Triplane Stable Diffusion 多视角学习 无监督学习
📋 核心要点
- 现有文本到3D方法依赖大量3D数据,且生成质量不高,难以处理复杂文本提示。
- PRD通过多视角扩散模型蒸馏,将预训练的Stable Diffusion适配为3D生成器,无需3D ground-truth。
- TriplaneTurbo基于PRD训练,仅需少量参数即可实现快速高质量的3D网格生成,耗时仅1.2秒。
📝 摘要(中文)
本文提出了一种名为渐进渲染蒸馏(PRD)的全新训练方案,旨在克服高质量3D训练数据匮乏的问题,将预训练的文本到图像扩散模型(如Stable Diffusion,SD)适配为3D表示(如Triplane)的生成器,而无需3D ground-truth。PRD通过蒸馏多视角扩散模型,将SD适配为原生3D生成器。在每次训练迭代中,PRD使用U-Net逐步对来自随机噪声的潜在变量进行去噪,并在每一步将去噪后的潜在变量解码为3D输出。结合SD,利用MVDream和RichDreamer等多视角扩散模型,通过score distillation将文本一致的纹理和几何体蒸馏到3D输出中。由于PRD支持在没有3D ground-truth的情况下进行训练,因此可以轻松扩展训练数据,并提高对具有创造性概念的挑战性文本提示的生成质量。同时,PRD可以加速生成模型的推理速度。利用PRD,我们训练了一个Triplane生成器,即TriplaneTurbo,它仅添加2.5%的可训练参数即可将SD适配于Triplane生成。TriplaneTurbo在效率和质量上均优于以往的文本到3D生成器。具体而言,它可以在1.2秒内生成高质量的3D网格,并且可以很好地泛化到具有挑战性的文本输入。
🔬 方法详解
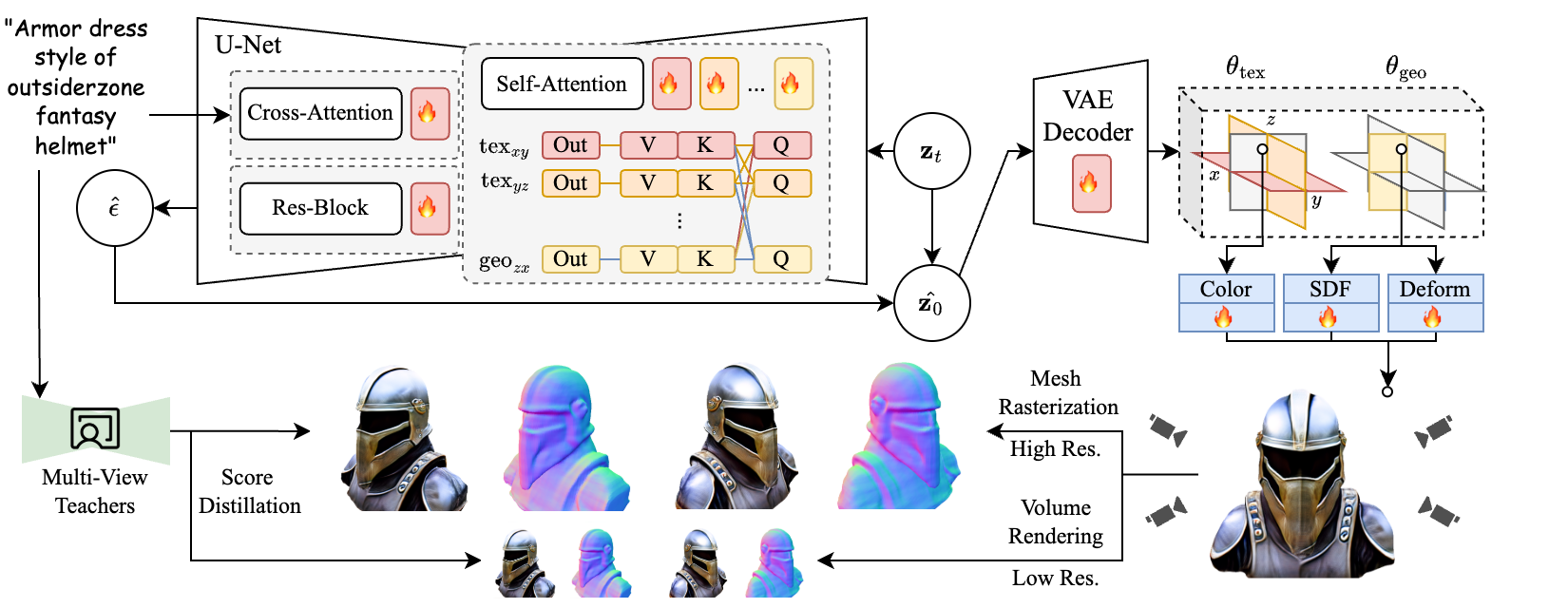
问题定义:现有文本到3D生成方法受限于高质量3D训练数据的匮乏,导致生成质量差,难以处理具有创造性概念的复杂文本提示。此外,现有方法通常需要较长的推理时间,难以满足快速生成的需求。
核心思路:本文的核心思路是通过渐进渲染蒸馏(PRD),利用预训练的文本到图像扩散模型(如Stable Diffusion)和多视角扩散模型(如MVDream和RichDreamer)的知识,在没有3D ground-truth的情况下,训练一个高质量的3D生成器。通过score distillation,将文本一致的纹理和几何体从多视角扩散模型蒸馏到3D输出中。
技术框架:PRD的整体框架包括以下几个主要阶段:1) 初始化:从随机噪声开始,生成初始的潜在变量。2) 渐进去噪:使用U-Net逐步对潜在变量进行去噪,每次去噪一小步。3) 3D解码:将去噪后的潜在变量解码为3D输出(如Triplane)。4) Score Distillation:利用多视角扩散模型和Stable Diffusion,通过score distillation将文本一致的纹理和几何体蒸馏到3D输出中。5) 迭代优化:重复上述步骤,不断优化3D生成器。
关键创新:PRD的关键创新在于:1) 无需3D ground-truth:通过蒸馏多视角扩散模型,避免了对大量高质量3D数据的依赖。2) 渐进渲染:通过逐步去噪和解码,提高了生成质量和稳定性。3) 高效推理:通过少量步骤即可生成高质量的3D网格,显著提高了推理速度。
关键设计:TriplaneTurbo在Stable Diffusion的基础上,仅添加了2.5%的可训练参数,即可实现Triplane的生成。损失函数主要包括score distillation loss,用于将多视角扩散模型的知识蒸馏到3D输出中。U-Net的网络结构采用标准的U-Net架构,用于潜在变量的去噪。
🖼️ 关键图片


📊 实验亮点
TriplaneTurbo在1.2秒内即可生成高质量的3D网格,显著优于以往的文本到3D生成器。实验结果表明,TriplaneTurbo不仅在效率上有所提升,而且在生成质量和对复杂文本提示的泛化能力方面也表现出色。与现有方法相比,TriplaneTurbo能够生成更逼真、更符合文本描述的3D模型。
🎯 应用场景
该研究成果可广泛应用于游戏开发、虚拟现实、增强现实、数字内容创作等领域。用户可以通过简单的文本提示,快速生成高质量的3D模型,极大地降低了3D内容创作的门槛,并加速了相关应用的发展。
📄 摘要(原文)
It is highly desirable to obtain a model that can generate high-quality 3D meshes from text prompts in just seconds. While recent attempts have adapted pre-trained text-to-image diffusion models, such as Stable Diffusion (SD), into generators of 3D representations (e.g., Triplane), they often suffer from poor quality due to the lack of sufficient high-quality 3D training data. Aiming at overcoming the data shortage, we propose a novel training scheme, termed as Progressive Rendering Distillation (PRD), eliminating the need for 3D ground-truths by distilling multi-view diffusion models and adapting SD into a native 3D generator. In each iteration of training, PRD uses the U-Net to progressively denoise the latent from random noise for a few steps, and in each step it decodes the denoised latent into 3D output. Multi-view diffusion models, including MVDream and RichDreamer, are used in joint with SD to distill text-consistent textures and geometries into the 3D outputs through score distillation. Since PRD supports training without 3D ground-truths, we can easily scale up the training data and improve generation quality for challenging text prompts with creative concepts. Meanwhile, PRD can accelerate the inference speed of the generation model in just a few steps. With PRD, we train a Triplane generator, namely TriplaneTurbo, which adds only $2.5\%$ trainable parameters to adapt SD for Triplane generation. TriplaneTurbo outperforms previous text-to-3D generators in both efficiency and quality. Specifically, it can produce high-quality 3D meshes in 1.2 seconds and generalize well for challenging text input. The code is available at https://github.com/theEricMa/TriplaneTurbo.