How to Train Your Dragon: Automatic Diffusion-Based Rigging for Characters with Diverse Topologies
作者: Zeqi Gu, Difan Liu, Timothy Langlois, Matthew Fisher, Abe Davis
分类: cs.GR, cs.CV
发布日期: 2025-03-19
备注: Accepted to Eurographics 2025
💡 一句话要点
提出基于扩散模型的自动绑定方法,用于生成具有多样拓扑结构角色的动画
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 扩散模型 动画生成 角色绑定 拓扑多样性 程序化数据生成
📋 核心要点
- 现有动画生成方法依赖于特定人体姿态表示和大量标注视频训练,难以推广到具有多样拓扑结构的角色。
- 提出一种基于扩散模型的自动绑定方法,仅需少量示例帧即可为新角色生成动画,无需大量人工标注。
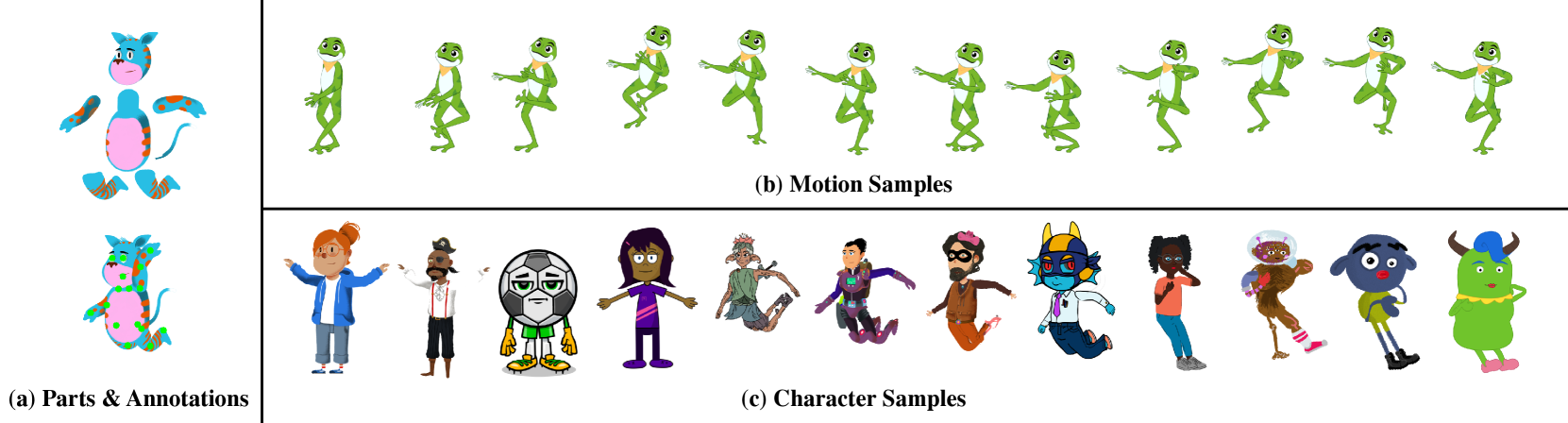
- 通过程序化数据生成和新颖骨骼表示,模型在多样拓扑结构数据上训练,并在新数据集上验证了其优越性。
📝 摘要(中文)
本文提出了一种基于扩散模型的方法,用于生成具有多样骨骼拓扑结构角色的动画。该模型仅需少量(3-5)示例帧,包含角色在不同姿势下的图像以及对应的骨骼信息,即可快速推断出该角色的绑定,并生成与新的骨骼姿势相对应的图像。论文提出了一种程序化的数据生成流程,能够高效地动态采样具有多样拓扑结构的训练数据。利用该流程以及一种新颖的骨骼表示,模型可以在包含大量纹理和拓扑结构的可动形状上进行训练。在微调阶段,模型能够快速适应未见过的目标角色,并很好地泛化到渲染新的姿势,适用于写实和卡通风格。为了更好地评估该任务的性能,作者创建了首个包含类人及非类人对象,并带有逐帧关键点标注的2D视频数据集。实验结果表明,该方法能够生成高质量的结果。
🔬 方法详解
问题定义:现有基于扩散模型的动画生成方法主要针对人体,依赖于特定的人体姿态表示和大量标注的真实视频数据。这限制了它们在具有更广泛骨骼拓扑结构的角色上的应用。因此,如何使扩散模型能够处理具有多样拓扑结构的角色动画生成是一个关键问题。现有方法难以泛化到非人角色,且需要大量标注数据,成本高昂。
核心思路:本文的核心思路是利用扩散模型强大的生成能力,结合程序化数据生成和新颖的骨骼表示,使模型能够学习到各种拓扑结构和外观的角色动画生成。通过少量示例帧进行微调,模型可以快速适应新的角色,并生成高质量的动画。这种方法避免了对大量标注数据的依赖,并提高了模型的泛化能力。
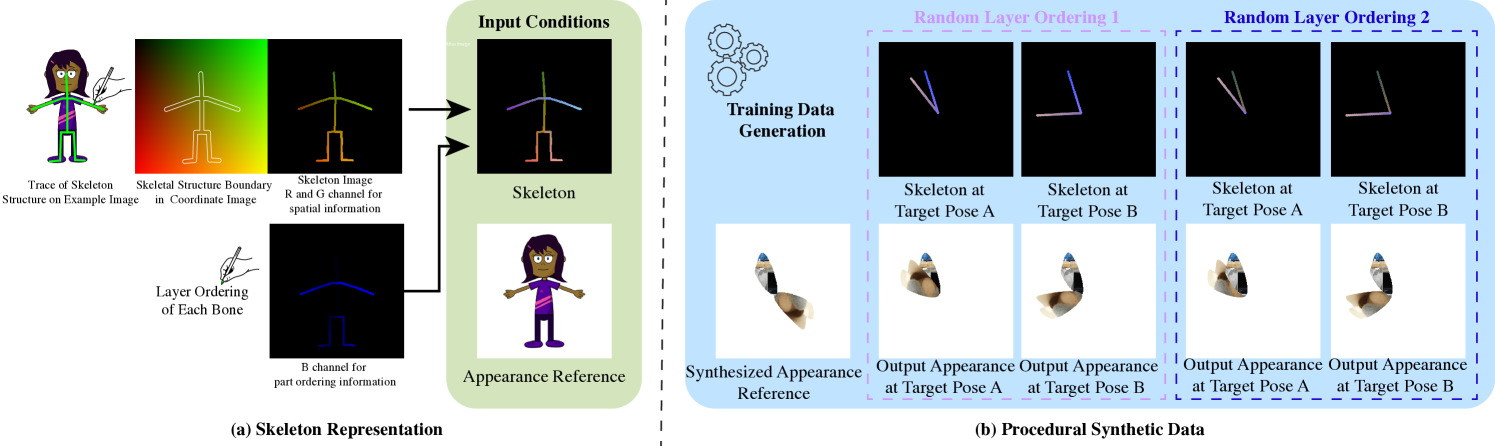
技术框架:该方法主要包含以下几个阶段:1) 程序化数据生成:设计一个程序化的流程,能够自动生成具有多样拓扑结构和外观的训练数据。2) 骨骼表示:提出一种新颖的骨骼表示方法,能够有效地编码不同角色的骨骼信息。3) 扩散模型训练:利用生成的数据和骨骼表示,训练一个扩散模型,使其能够生成与给定骨骼姿势相对应的角色图像。4) 微调:使用少量目标角色的示例帧对模型进行微调,使其能够适应新的角色。
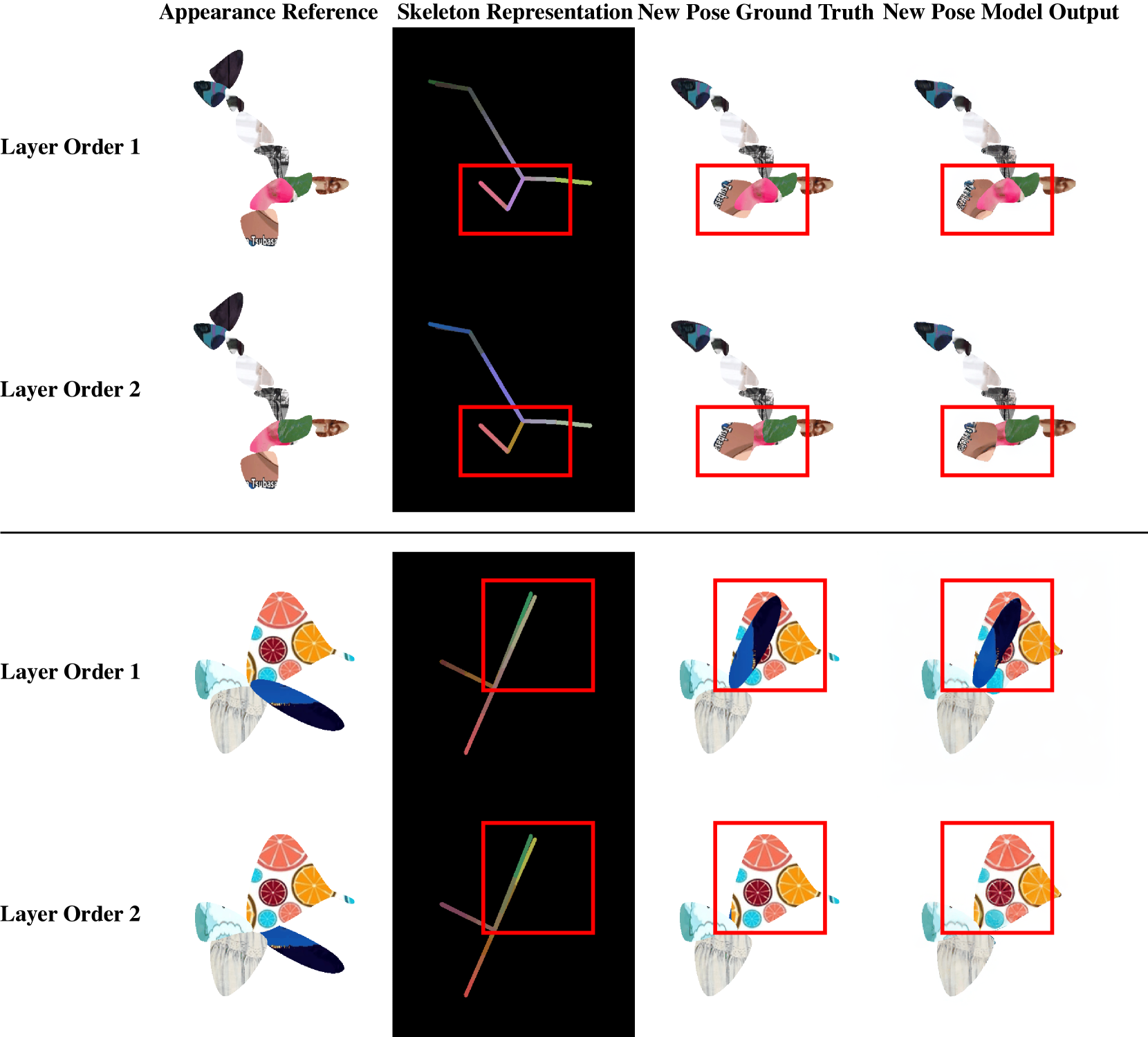
关键创新:该方法最重要的技术创新点在于:1) 程序化数据生成流程,能够高效地生成具有多样拓扑结构的训练数据,解决了训练数据不足的问题。2) 新颖的骨骼表示方法,能够有效地编码不同角色的骨骼信息,提高了模型的泛化能力。3) 基于扩散模型的动画生成方法,能够生成高质量的动画,并且可以通过少量示例帧进行微调,快速适应新的角色。
关键设计:在程序化数据生成方面,作者设计了一系列参数来控制角色的拓扑结构和外观,例如骨骼数量、骨骼长度、纹理等。在骨骼表示方面,作者使用了一种基于相对坐标的表示方法,能够有效地编码骨骼之间的关系。在扩散模型方面,作者使用了U-Net结构,并添加了骨骼信息作为条件输入。在损失函数方面,作者使用了L1损失和感知损失,以提高生成图像的质量。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在生成具有多样拓扑结构的角色动画方面取得了显著的成果。与现有方法相比,该方法能够生成更高质量的动画,并且能够更好地泛化到未见过的角色。作者还创建了一个新的2D视频数据集,包含类人及非人类角色,并带有逐帧关键点标注,为该领域的研究提供了新的benchmark。
🎯 应用场景
该研究成果可应用于游戏开发、动画制作、虚拟现实等领域。它可以帮助开发者快速生成具有各种拓扑结构和外观的角色动画,降低动画制作的成本和时间。此外,该方法还可以用于生成虚拟角色的个性化动画,提高用户体验。未来,该技术有望应用于更广泛的领域,例如机器人控制、生物模拟等。
📄 摘要(原文)
Recent diffusion-based methods have achieved impressive results on animating images of human subjects. However, most of that success has built on human-specific body pose representations and extensive training with labeled real videos. In this work, we extend the ability of such models to animate images of characters with more diverse skeletal topologies. Given a small number (3-5) of example frames showing the character in different poses with corresponding skeletal information, our model quickly infers a rig for that character that can generate images corresponding to new skeleton poses. We propose a procedural data generation pipeline that efficiently samples training data with diverse topologies on the fly. We use it, along with a novel skeleton representation, to train our model on articulated shapes spanning a large space of textures and topologies. Then during fine-tuning, our model rapidly adapts to unseen target characters and generalizes well to rendering new poses, both for realistic and more stylized cartoon appearances. To better evaluate performance on this novel and challenging task, we create the first 2D video dataset that contains both humanoid and non-humanoid subjects with per-frame keypoint annotations. With extensive experiments, we demonstrate the superior quality of our results. Project page: https://traindragondiffusion.github.io/