AnyMoLe: Any Character Motion In-betweening Leveraging Video Diffusion Models
作者: Kwan Yun, Seokhyeon Hong, Chaelin Kim, Junyong Noh
分类: cs.GR, cs.AI, cs.CV, cs.LG, cs.MM
发布日期: 2025-03-11
备注: 11 pages, 10 figures, CVPR 2025
💡 一句话要点
AnyMoLe:利用视频扩散模型为任意角色生成运动插帧,无需特定数据集。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱八:物理动画 (Physics-based Animation)
关键词: 运动插帧 视频扩散模型 领域自适应 角色动画 无数据依赖
📋 核心要点
- 现有运动插帧方法依赖于特定角色的数据集,限制了其泛用性。
- AnyMoLe利用视频扩散模型,通过两阶段生成和领域自适应,实现任意角色的运动插帧。
- 提出的方法降低了数据依赖,生成平滑逼真的过渡,适用于多种运动插帧任务。
📝 摘要(中文)
本文提出AnyMoLe,一种新颖的方法,利用视频扩散模型为任意角色生成运动插帧,无需特定数据集,从而解决了现有基于学习的运动插帧方法对角色特定数据集的依赖问题。该方法采用两阶段帧生成过程,以增强上下文理解。此外,为了弥合真实世界和渲染角色动画之间的领域差距,引入了ICAdapt,一种用于视频扩散模型的微调技术。同时,提出了一种“运动-视频模仿”优化技术,利用2D和3D感知特征,为具有任意关节结构的角色实现无缝运动生成。AnyMoLe显著降低了数据依赖性,同时生成平滑逼真的过渡,使其适用于广泛的运动插帧任务。
🔬 方法详解
问题定义:现有基于学习的运动插帧方法通常需要针对特定角色的大量数据集进行训练,这限制了它们在实际应用中的泛化能力。当需要处理新的角色或动画风格时,必须重新收集和训练数据,成本高昂且效率低下。因此,如何摆脱对特定角色数据的依赖,实现对任意角色的运动插帧是本文要解决的关键问题。
核心思路:AnyMoLe的核心思路是利用预训练的视频扩散模型,学习通用的运动模式和风格,然后通过微调和优化,将这些知识迁移到新的角色上。通过这种方式,模型可以理解不同角色之间的运动关系,并生成平滑逼真的过渡动画,而无需针对每个角色进行单独训练。
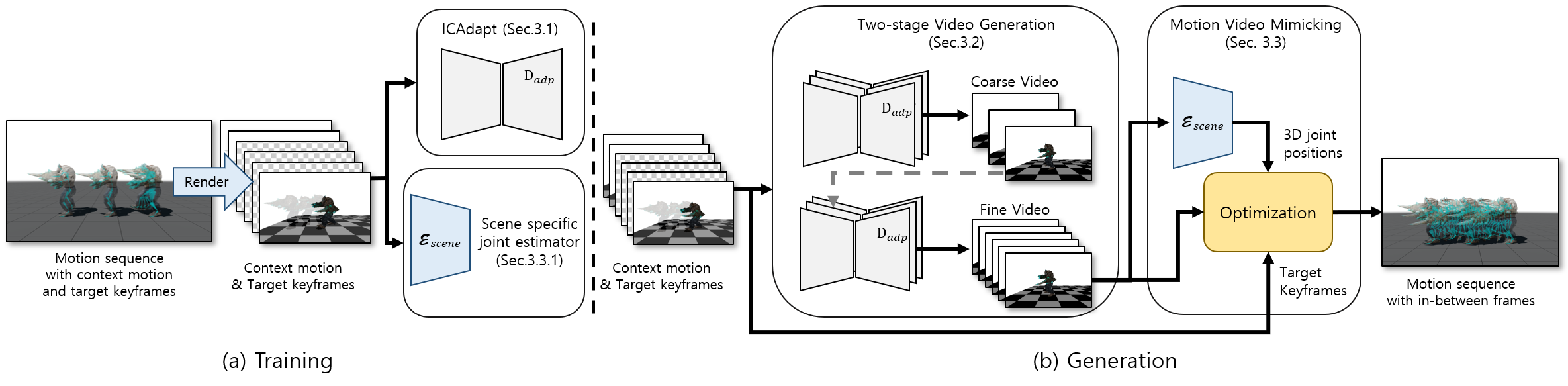
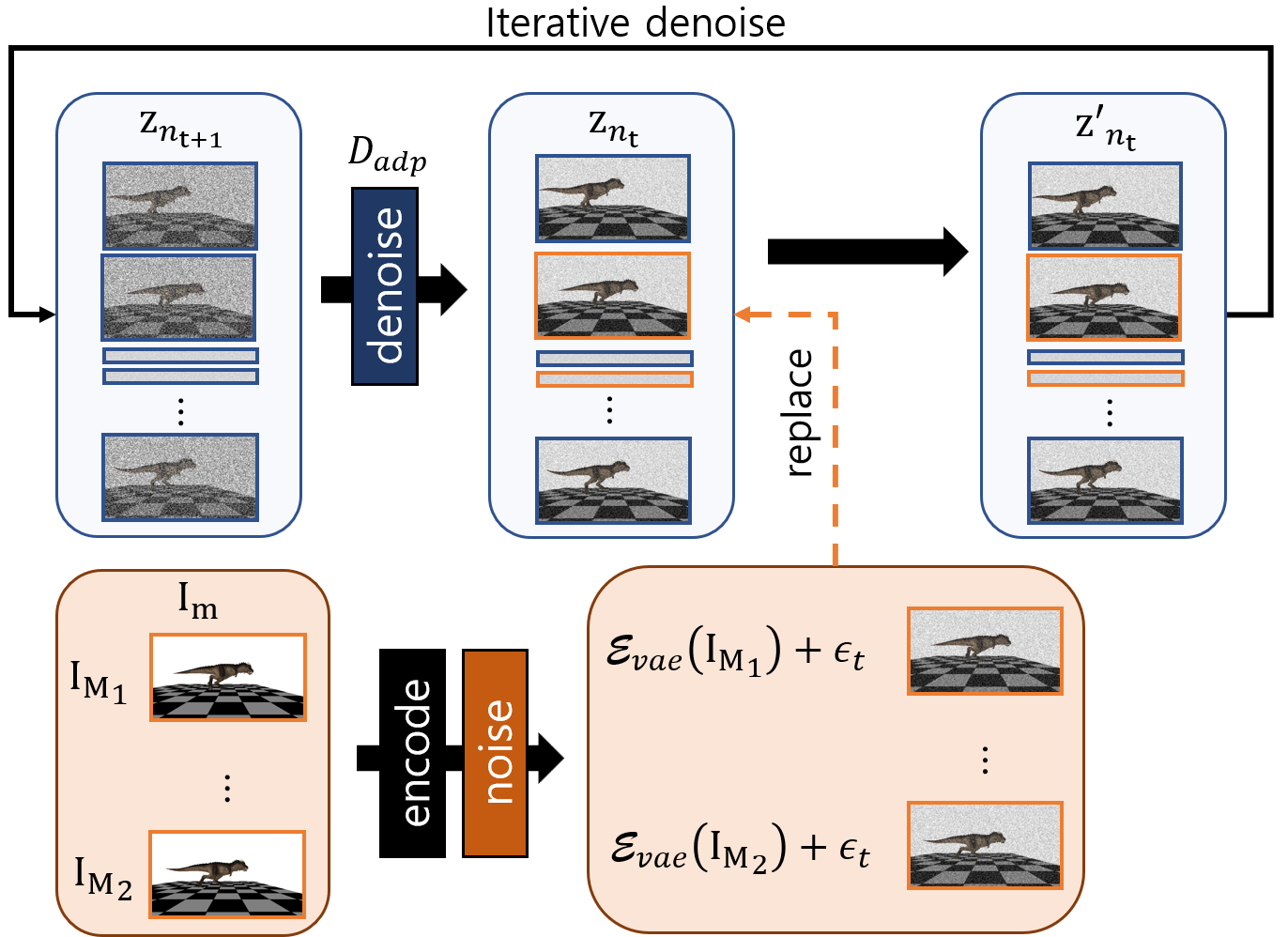
技术框架:AnyMoLe包含以下几个主要模块:1) 两阶段帧生成:首先生成粗略的中间帧,然后进行细化,以增强上下文理解。2) ICAdapt:一种用于视频扩散模型的微调技术,用于弥合真实世界和渲染角色动画之间的领域差距。3) 运动-视频模仿优化:利用2D和3D感知特征,使模型能够理解和模仿输入运动的风格,从而为具有任意关节结构的角色生成无缝运动。
关键创新:AnyMoLe最重要的技术创新在于它能够利用视频扩散模型进行任意角色的运动插帧,而无需特定角色的训练数据。这极大地降低了数据依赖性,并提高了模型的泛化能力。此外,ICAdapt和运动-视频模仿优化技术进一步提高了生成动画的质量和逼真度。
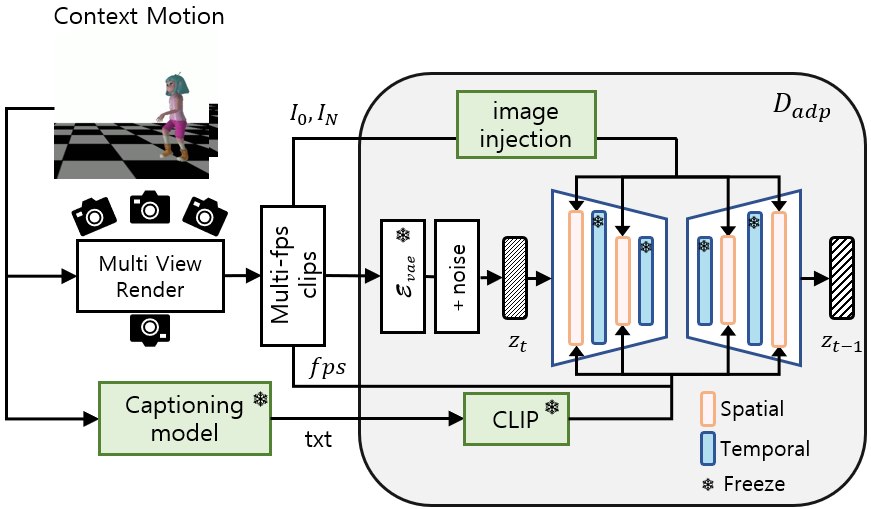
关键设计:ICAdapt通过在目标领域数据上微调视频扩散模型,使其能够更好地适应渲染角色动画的风格。运动-视频模仿优化则通过最小化生成动画与输入运动之间的差异,确保生成动画的平滑性和一致性。具体的损失函数包括运动损失、风格损失和对抗损失等。网络结构方面,采用了标准的视频扩散模型架构,并针对运动插帧任务进行了优化。
🖼️ 关键图片
📊 实验亮点
AnyMoLe通过在多个数据集上进行实验,验证了其有效性。实验结果表明,AnyMoLe能够生成平滑逼真的运动插帧,并且在数据依赖性方面优于现有方法。具体的性能数据(例如,运动平滑度、逼真度等指标)和对比基线(例如,基于传统插值的方法、基于学习的插帧方法)的详细信息需要在论文中查找。
🎯 应用场景
AnyMoLe在游戏开发、动画制作、虚拟现实等领域具有广泛的应用前景。它可以用于自动生成角色动画的过渡帧,减少人工制作的工作量,提高生产效率。此外,AnyMoLe还可以用于创建个性化的角色动画,满足用户的定制化需求。未来,该技术有望应用于更复杂的动画生成任务,例如动作捕捉数据的修复和增强。
📄 摘要(原文)
Despite recent advancements in learning-based motion in-betweening, a key limitation has been overlooked: the requirement for character-specific datasets. In this work, we introduce AnyMoLe, a novel method that addresses this limitation by leveraging video diffusion models to generate motion in-between frames for arbitrary characters without external data. Our approach employs a two-stage frame generation process to enhance contextual understanding. Furthermore, to bridge the domain gap between real-world and rendered character animations, we introduce ICAdapt, a fine-tuning technique for video diffusion models. Additionally, we propose a ``motion-video mimicking'' optimization technique, enabling seamless motion generation for characters with arbitrary joint structures using 2D and 3D-aware features. AnyMoLe significantly reduces data dependency while generating smooth and realistic transitions, making it applicable to a wide range of motion in-betweening tasks.