3D Dynamic Fluid Assets from Single-View Videos with Generative Gaussian Splatting
作者: Zhiwei Zhao, Alan Zhao, Minchen Li, Yixin Hu
分类: cs.GR
发布日期: 2025-03-02 (更新: 2025-10-30)
💡 一句话要点
提出基于生成式高斯溅射的单视角视频三维动态流体资产重建方法
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 三维重建 动态流体 高斯溅射 单视角视频 物理模拟
📋 核心要点
- 现有方法难以从单视角视频中创建具有物理一致性的三维动态场景,尤其是在流体模拟方面。
- 该论文提出利用生成式3D高斯溅射模型,从单视角视频中提取并重新模拟3D动态流体对象,实现物理一致性。
- 该方法适用于多种流体类型,允许用户编辑几何体或延长运动,为低成本生成大规模3D流体资产带来潜力。
📝 摘要(中文)
本文提出了一种新颖的框架,利用生成式三维高斯溅射(3DGS)模型,从单视角视频中提取并重新模拟三维动态流体对象。首先,从单视角图像生成并优化由3DGS表示的流体几何体,然后进行去噪、致密化和跨帧对齐。利用光流估计流体表面速度,并提出主流提取算法对其进行优化。然后,从流体封闭表面的速度推导出三维体积速度场。速度场被转换为无散度的、基于网格的表示,从而可以通过其跨帧的可微性来优化模拟参数。此过程输出具有物理动力学的、可用于模拟的流体资产,其物理动力学与源视频中观察到的动力学非常匹配。该方法适用于各种液体流体,包括无粘性和粘性流体,并允许用户编辑输出几何体或无缝地延长运动持续时间。这种从单视角视频自动创建三维动态流体资产的方法,易于从互联网获取,显示出以低成本生成大规模三维流体资产的巨大潜力。
🔬 方法详解
问题定义:现有方法难以从单视角视频中重建出具有物理真实感的动态流体场景。痛点在于如何从有限的视角信息中推断出准确的三维几何结构和运动信息,并将其转化为可用于物理模拟的参数。
核心思路:该论文的核心思路是利用3D高斯溅射(3DGS)来表示流体几何体,并结合光流估计和可微渲染技术,从单视角视频中提取流体的表面速度和三维体积速度场。然后,将速度场转换为无散度的网格表示,并通过优化模拟参数,使得模拟结果与原始视频中的流体运动相匹配。这样设计的目的是为了充分利用3DGS的表达能力和可微性,实现从视频到可模拟流体资产的自动转换。
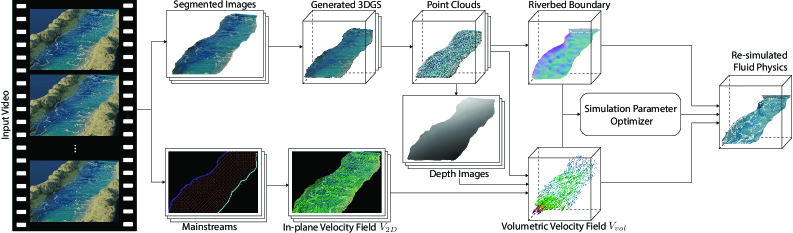
技术框架:整体框架包含以下几个主要阶段:1) 基于单视角图像生成和优化3DGS表示的流体几何体;2) 对3DGS表示进行去噪、致密化和跨帧对齐;3) 利用光流估计流体表面速度,并进行优化;4) 从表面速度推导出三维体积速度场;5) 将速度场转换为无散度的网格表示;6) 通过可微渲染优化模拟参数,生成可用于模拟的流体资产。
关键创新:最重要的技术创新点在于将生成式3DGS模型与物理模拟相结合,实现从单视角视频到可模拟流体资产的自动转换。与现有方法相比,该方法无需复杂的多视角设置或深度信息,即可重建出具有物理真实感的动态流体场景。此外,利用可微渲染技术优化模拟参数,使得模拟结果与原始视频高度一致。
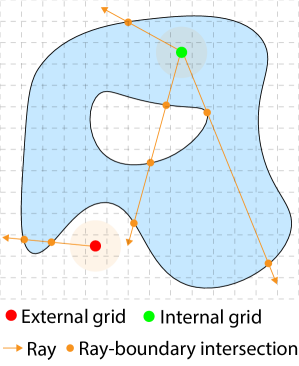
关键设计:关键设计包括:1) 使用3DGS表示流体几何体,利用其表达能力和可微性;2) 利用光流估计流体表面速度,并提出主流提取算法进行优化;3) 将速度场转换为无散度的网格表示,保证流体模拟的稳定性;4) 通过可微渲染优化模拟参数,例如粘度、表面张力等,使得模拟结果与原始视频匹配。损失函数的设计需要考虑几何重建的准确性、速度场估计的准确性和模拟结果的物理真实性。
🖼️ 关键图片
📊 实验亮点
该论文提出了一种从单视角视频重建三维动态流体资产的全新方法,无需多视角数据或深度信息。通过生成式3DGS模型和可微渲染技术,实现了物理真实感的流体模拟。实验结果表明,该方法能够有效地重建各种类型的流体,并允许用户编辑几何体和延长运动,为三维内容创作提供了新的可能性。
🎯 应用场景
该研究成果可广泛应用于电影特效、游戏开发、虚拟现实等领域。通过该方法,可以低成本地从互联网视频中提取并重建三维动态流体资产,极大地降低了三维内容创作的门槛。未来,该技术有望应用于更复杂的流体模拟和交互式应用中,例如虚拟水族馆、流体艺术设计等。
📄 摘要(原文)
While the generation of 3D content from single-view images has been extensively studied, the creation of physically consistent 3D dynamic scenes from videos remains in its early stages. We propose a novel framework leveraging generative 3D Gaussian Splatting (3DGS) models to extract and re-simulate 3D dynamic fluid objects from single-view videos using simulation methods. The fluid geometry represented by 3DGS is initially generated and optimized from single-view images, then denoised, densified, and aligned across frames. We estimate the fluid surface velocity using optical flow, propose a mainstream extraction algorithm to refine it. The 3D volumetric velocity field is then derived from the velocity of the fluid's enclosed surface. The velocity field is therewith converted into a divergence-free, grid-based representation, enabling the optimization of simulation parameters through its differentiability across frames. This process outputs simulation-ready fluid assets with physical dynamics closely matching those observed in the source video. Our approach is applicable to various liquid fluids, including inviscid and viscous types, and allows users to edit the output geometry or extend movement durations seamlessly. This automatic method for creating 3D dynamic fluid assets from single-view videos, easily obtainable from the internet, shows great potential for generating large-scale 3D fluid assets at a low cost.