GCDance: Genre-Controlled Music-Driven 3D Full Body Dance Generation
作者: Xinran Liu, Xu Dong, Shenbin Qian, Diptesh Kanojia, Wenwu Wang, Zhenhua Feng
分类: cs.GR, cs.CV, cs.SD, eess.AS
发布日期: 2025-02-25 (更新: 2025-09-29)
💡 一句话要点
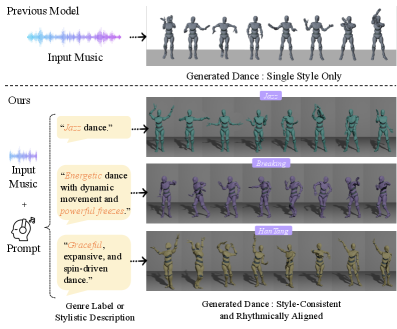
GCDance:提出基于扩散模型的流派可控音乐驱动3D全身舞蹈生成框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音乐驱动舞蹈生成 流派控制 扩散模型 文本引导 多任务学习 3D全身舞蹈 音乐基础模型
📋 核心要点
- 现有音乐驱动舞蹈生成方法难以生成具有特定风格属性的舞蹈,缺乏对舞蹈流派的有效控制。
- 提出一种基于扩散模型的框架,通过文本控制机制和多任务优化策略,实现流派可控的舞蹈生成。
- 在FineDance和AIST++数据集上进行实验,结果表明该方法在舞蹈质量和流派控制方面优于现有方法。
📝 摘要(中文)
本文提出了一种基于扩散模型的流派可控3D全身舞蹈生成框架GCDance,旨在解决现有音乐驱动舞蹈生成方法难以表达特定风格属性的问题。该框架以音乐和描述性文本为条件,通过文本控制机制将显式流派标签或自由形式描述文本映射为流派特定的控制信号,从而实现精确和可控的文本引导流派一致性舞蹈动作生成。此外,利用音乐基础模型的特征来增强音乐和文本条件之间的对齐,促进连贯和语义对齐的舞蹈合成。最后,提出了一种新的多任务优化策略,以平衡文本流派信息的提取和高质量生成结果的维持,有效平衡物理真实感、空间准确性和文本分类等竞争因素,显著提高生成序列的整体质量。在FineDance和AIST++数据集上的大量实验结果表明,GCDance优于现有的最先进方法。
🔬 方法详解
问题定义:音乐驱动的舞蹈生成任务旨在根据音乐生成逼真的舞蹈动作。然而,现有方法在生成具有特定流派风格的舞蹈方面存在困难,难以保证生成的舞蹈动作与目标流派的风格一致。此外,现有方法在音乐和舞蹈动作之间的同步性和语义一致性方面仍有提升空间。
核心思路:GCDance的核心思路是利用扩散模型强大的生成能力,并引入文本控制机制来控制生成舞蹈的流派风格。通过将流派信息编码为文本提示,并将其映射为流派特定的控制信号,从而引导扩散模型生成具有特定流派风格的舞蹈动作。此外,利用音乐基础模型的特征来增强音乐和文本条件之间的对齐,从而提高音乐和舞蹈动作之间的同步性和语义一致性。
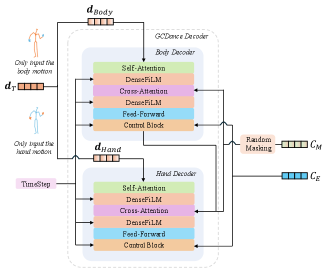
技术框架:GCDance的整体框架包括以下几个主要模块:1) 音乐特征提取模块:用于提取音乐的特征表示。2) 文本编码模块:用于将文本提示(流派标签或描述性文本)编码为文本特征。3) 文本控制模块:用于将文本特征映射为流派特定的控制信号。4) 扩散模型:用于根据音乐特征和流派控制信号生成舞蹈动作。5) 多任务优化模块:用于平衡文本流派信息的提取和高质量生成结果的维持。
关键创新:GCDance的关键创新在于以下几个方面:1) 提出了文本控制机制,实现了流派可控的舞蹈生成。2) 利用音乐基础模型的特征来增强音乐和文本条件之间的对齐。3) 提出了多任务优化策略,平衡了文本流派信息的提取和高质量生成结果的维持。
关键设计:在文本控制模块中,使用了一个文本编码器(例如,BERT)来将文本提示编码为文本特征。然后,使用一个映射网络将文本特征映射为流派特定的控制信号。在扩散模型中,使用了一个U-Net结构来逐步去噪,从而生成舞蹈动作。在多任务优化模块中,使用了多个损失函数,包括:1) 舞蹈动作的重建损失。2) 文本分类损失,用于确保生成的舞蹈动作与目标流派一致。3) 物理真实感损失,用于确保生成的舞蹈动作是物理上可行的。
🖼️ 关键图片

📊 实验亮点
在FineDance和AIST++数据集上的实验结果表明,GCDance在舞蹈质量和流派控制方面优于现有的最先进方法。例如,在FineDance数据集上,GCDance在FCD(Fréchet Choreography Distance)指标上取得了显著的提升,表明生成的舞蹈动作更加逼真和流畅。此外,GCDance在流派分类准确率方面也取得了显著的提升,表明生成的舞蹈动作与目标流派更加一致。
🎯 应用场景
GCDance具有广泛的应用前景,例如:1) 虚拟现实和增强现实:可以用于生成虚拟人物的舞蹈动作,增强用户的沉浸式体验。2) 游戏开发:可以用于生成游戏角色的舞蹈动作,提高游戏的趣味性和可玩性。3) 音乐创作:可以用于根据音乐自动生成舞蹈动作,为音乐创作提供灵感。4) 舞蹈教学:可以用于生成教学舞蹈动作,辅助舞蹈教学。
📄 摘要(原文)
Music-driven dance generation is a challenging task as it requires strict adherence to genre-specific choreography while ensuring physically realistic and precisely synchronized dance sequences with the music's beats and rhythm. Although significant progress has been made in music-conditioned dance generation, most existing methods struggle to convey specific stylistic attributes in generated dance. To bridge this gap, we propose a diffusion-based framework for genre-specific 3D full-body dance generation, conditioned on both music and descriptive text. To effectively incorporate genre information, we develop a text-based control mechanism that maps input prompts, either explicit genre labels or free-form descriptive text, into genre-specific control signals, enabling precise and controllable text-guided generation of genre-consistent dance motions. Furthermore, to enhance the alignment between music and textual conditions, we leverage the features of a music foundation model, facilitating coherent and semantically aligned dance synthesis. Last, to balance the objectives of extracting text-genre information and maintaining high-quality generation results, we propose a novel multi-task optimization strategy. This effectively balances competing factors such as physical realism, spatial accuracy, and text classification, significantly improving the overall quality of the generated sequences. Extensive experimental results obtained on the FineDance and AIST++ datasets demonstrate the superiority of GCDance over the existing state-of-the-art approaches.