MoGraphGPT: Creating Interactive Scenes Using Modular LLM and Graphical Control
作者: Hui Ye, Chufeng Xiao, Jiaye Leng, Pengfei Xu, Hongbo Fu
分类: cs.HC, cs.GR
发布日期: 2025-02-07
备注: 16 pages, 10 figures
💡 一句话要点
MoGraphGPT:利用模块化LLM和图形控制创建交互式场景
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 交互式场景生成 大型语言模型 模块化设计 图形用户界面 无代码编程
📋 核心要点
- 现有方法在创建复杂交互式场景时,LLM生成的代码容易出错,且缺乏对单个元素编辑的灵活性。
- MoGraphGPT采用元素级模块化技术,通过分离的LLM模块处理元素描述,并用中央模块管理元素交互。
- 实验表明,MoGraphGPT显著提升了创建复杂2D交互式场景的易用性、可控性和改进性,优于基线系统。
📝 摘要(中文)
创建交互式场景通常涉及复杂的编程任务。尽管像ChatGPT这样的大型语言模型(LLM)可以从自然语言生成代码,但它们的输出常常容易出错,尤其是在编写多个元素之间交互的脚本时。线性对话结构限制了对单个元素的编辑,并且缺乏图形化和精确的控制使得视觉集成变得复杂。为了解决这些问题,我们集成了一种元素级模块化技术,该技术通过单独的LLM模块处理单个元素的文本描述,并由一个中央模块管理元素之间的交互。这种模块化方法允许独立地改进每个元素。我们设计了一个图形用户界面MoGraphGPT,它结合了模块化LLM和增强的图形控制,以生成2D交互式场景的代码。它能够直接集成图形信息,并通过自动生成的滑块提供快速、精确的控制。我们与AI编码工具Cursor Composer进行的对比评估以及可用性研究表明,MoGraphGPT在以无代码方式创建具有多个视觉元素的复杂2D交互式场景时,显著提高了易用性、可控性和改进性。
🔬 方法详解
问题定义:现有方法在利用大型语言模型(LLM)生成交互式场景代码时,存在以下痛点:一是生成的代码容易出错,尤其是在处理多个元素之间的复杂交互时;二是线性对话结构限制了对单个元素的独立编辑和优化;三是缺乏图形化和精确的控制,导致视觉集成困难。这些问题使得创建复杂交互式场景变得繁琐且效率低下。
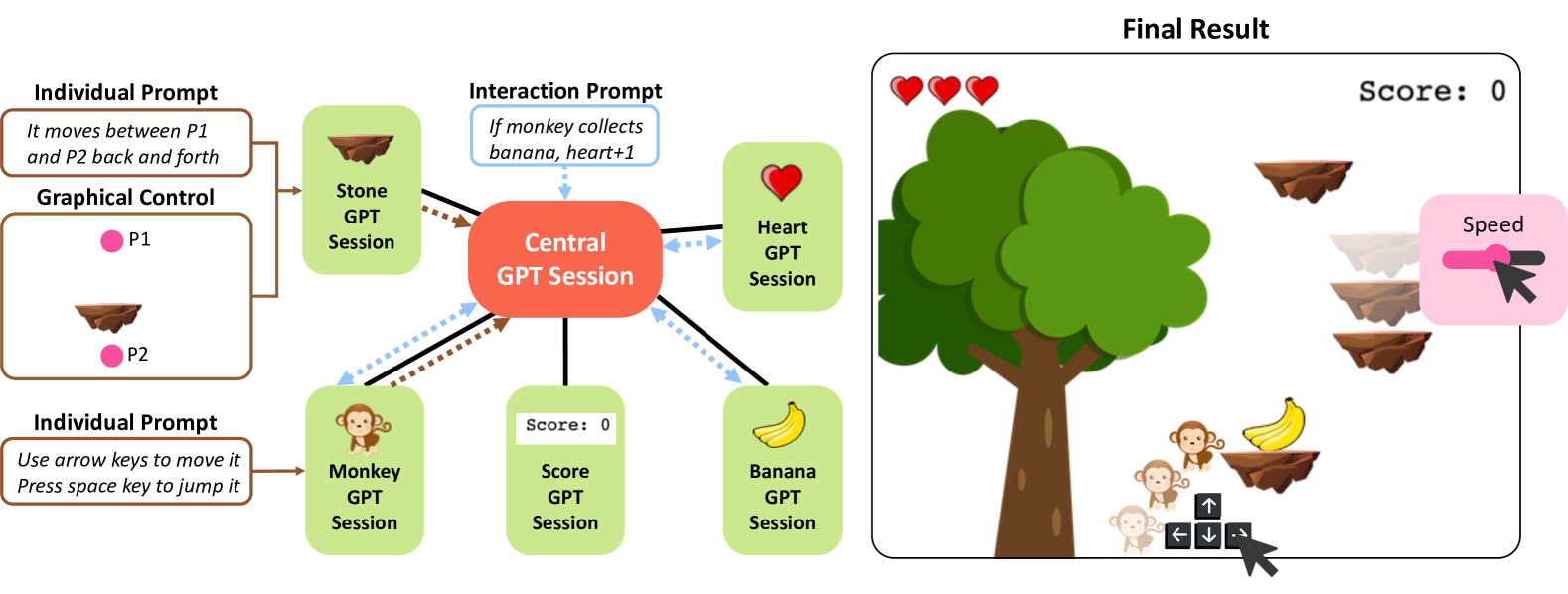
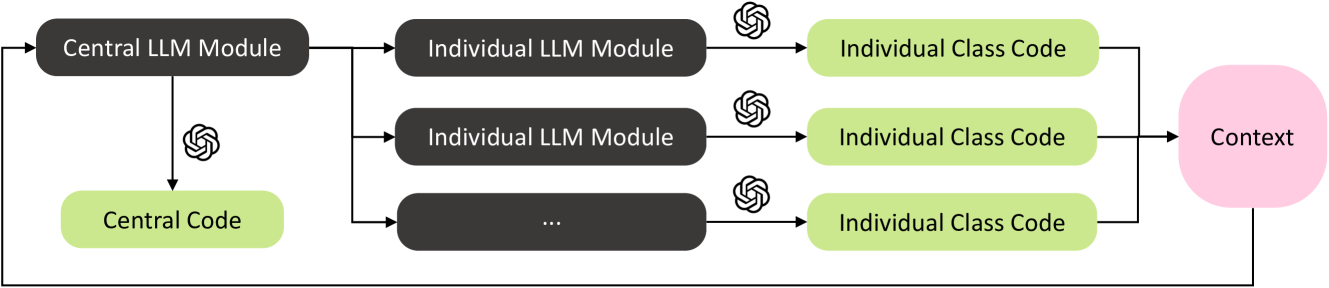
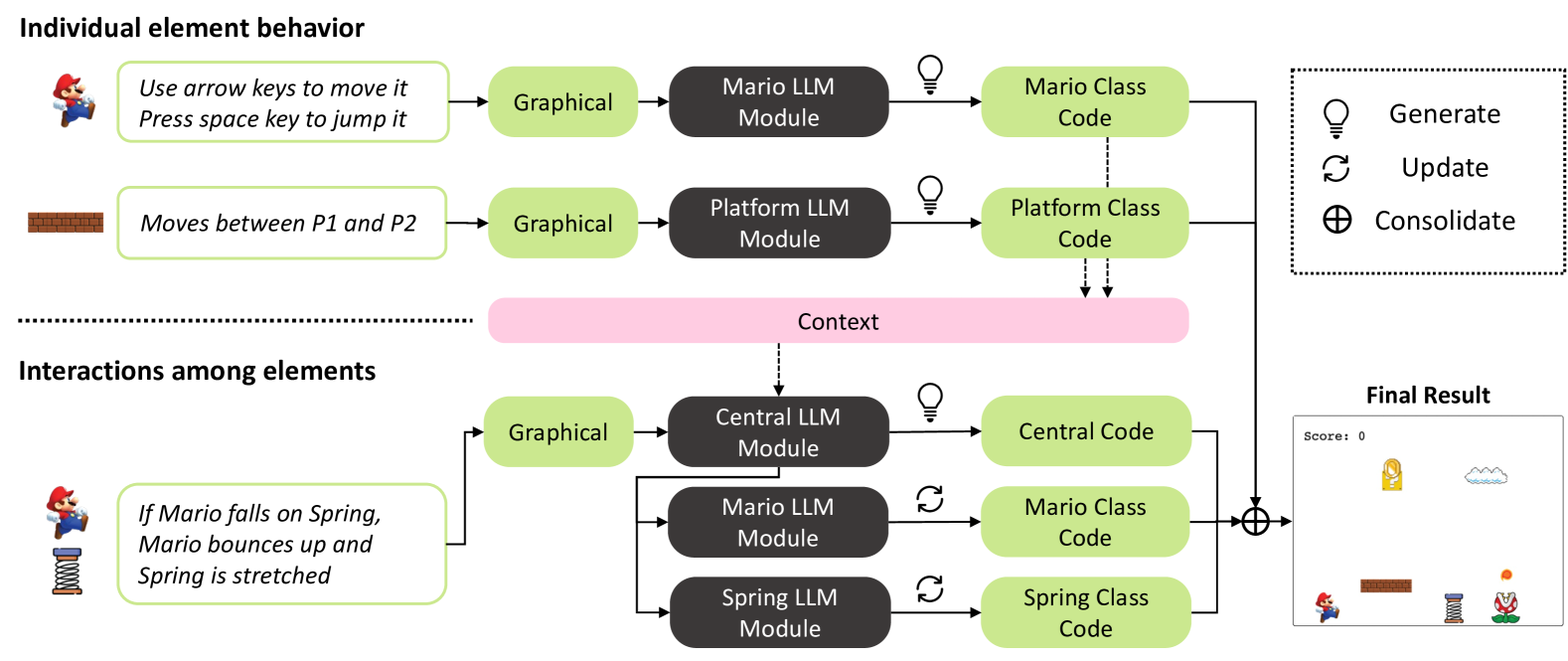
核心思路:MoGraphGPT的核心思路是将交互式场景的创建过程模块化。具体来说,它将场景中的每个元素视为一个独立的模块,并使用单独的LLM模块来处理每个元素的文本描述。同时,引入一个中央模块来管理各个元素之间的交互逻辑。这种模块化的设计使得可以独立地编辑和优化每个元素,从而提高代码的准确性和可维护性。此外,MoGraphGPT还提供了一个图形用户界面,允许用户通过图形化的方式直接控制场景中的元素,从而简化了视觉集成的过程。
技术框架:MoGraphGPT的整体架构包含以下几个主要模块:1) 元素描述模块:负责接收用户对场景中各个元素的文本描述;2) LLM模块:针对每个元素,使用独立的LLM模块生成相应的代码;3) 交互管理模块:负责管理各个元素之间的交互逻辑,例如事件触发、状态更新等;4) 图形用户界面:提供图形化的界面,允许用户直接控制场景中的元素,并实时预览效果。整个流程是:用户通过GUI输入元素描述,LLM模块生成代码,交互管理模块处理元素交互,最终在GUI上呈现交互式场景。
关键创新:MoGraphGPT最重要的技术创新点在于其元素级的模块化设计。与传统的线性对话式代码生成方法不同,MoGraphGPT将场景中的每个元素视为一个独立的模块,并使用单独的LLM模块来处理每个元素的文本描述。这种模块化的设计使得可以独立地编辑和优化每个元素,从而提高代码的准确性和可维护性。此外,MoGraphGPT还提供了一个图形用户界面,允许用户通过图形化的方式直接控制场景中的元素,从而简化了视觉集成的过程。
关键设计:MoGraphGPT的关键设计包括:1) 针对不同类型的元素,选择合适的LLM模型;2) 设计合理的交互管理机制,确保各个元素之间的交互逻辑正确;3) 设计易于使用的图形用户界面,方便用户进行图形化控制和视觉集成。具体的技术细节(如损失函数、网络结构等)在论文中未明确提及,属于未知信息。
🖼️ 关键图片
📊 实验亮点
MoGraphGPT与基线系统Cursor Composer相比,在创建复杂2D交互式场景时,显著提高了易用性、可控性和改进性。具体性能数据未知,但可用性研究表明,用户在使用MoGraphGPT时能够更轻松地创建和修改交互式场景,从而提高了开发效率。
🎯 应用场景
MoGraphGPT可应用于游戏开发、教育软件、交互式演示文稿等领域。它降低了创建交互式场景的编程门槛,使得非专业人士也能轻松创建复杂的交互式应用。未来,该技术有望扩展到更复杂的3D场景和更高级的交互模式,推动交互式内容创作的普及。
📄 摘要(原文)
Creating interactive scenes often involves complex programming tasks. Although large language models (LLMs) like ChatGPT can generate code from natural language, their output is often error-prone, particularly when scripting interactions among multiple elements. The linear conversational structure limits the editing of individual elements, and lacking graphical and precise control complicates visual integration. To address these issues, we integrate an element-level modularization technique that processes textual descriptions for individual elements through separate LLM modules, with a central module managing interactions among elements. This modular approach allows for refining each element independently. We design a graphical user interface, MoGraphGPT , which combines modular LLMs with enhanced graphical control to generate codes for 2D interactive scenes. It enables direct integration of graphical information and offers quick, precise control through automatically generated sliders. Our comparative evaluation against an AI coding tool, Cursor Composer, as the baseline system and a usability study show MoGraphGPT significantly improves easiness, controllability, and refinement in creating complex 2D interactive scenes with multiple visual elements in a coding-free manner.