Synchronize Dual Hands for Physics-Based Dexterous Guitar Playing
作者: Pei Xu, Ruocheng Wang
分类: cs.GR
发布日期: 2024-09-25 (更新: 2025-02-19)
备注: SIGGRAPH Asia 2024. Video: https://www.youtube.com/watch?v=r_y0P2pIeF8&list=PLLfEynalFz6j0X5Kiut0U3GLRxt3Oz_oa. Project Webpage: https://pei-xu.github.io/guitar
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出基于物理的双手协同吉他演奏动作生成方法,提升控制效率。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 双手协同控制 物理模拟 强化学习 合作学习 动作生成
📋 核心要点
- 现有方法难以在高维状态-动作空间中直接学习双手协同控制策略,导致训练效率低下。
- 采用合作学习,将双手视为独立智能体,分别训练策略后,通过潜在空间操作实现同步。
- 在吉他演奏任务中验证了方法的有效性,能够根据吉他谱生成复杂的和弦按压和拨弦动作。
📝 摘要(中文)
本文提出了一种新颖的方法,用于合成物理模拟双手在需要高时间精度双手动协调任务中的灵巧运动。该方法不直接学习联合策略来控制双手,而是通过合作学习执行双手动控制,其中每只手都被视为一个独立的智能体。首先分别训练每只手的独立策略,然后通过集中式环境中的潜在空间操作同步这些策略,作为双手控制的联合策略。 这样做避免了直接在高维双手的联合状态-动作空间中进行策略学习,大大提高了整体训练效率。 我们在具有挑战性的吉他演奏任务中证明了我们提出的方法的有效性。 由我们的方法训练的虚拟吉他手可以从一般吉他演奏练习动作的非结构化参考数据中合成动作,并根据输入的不存在于参考数据中的吉他谱,准确地演奏具有复杂和弦按压和拨弦模式的各种节奏。 随本文一起,我们提供了收集的动作捕捉数据,作为策略训练的参考。 代码可在以下网址获得:https://pei-xu.github.io/guitar。
🔬 方法详解
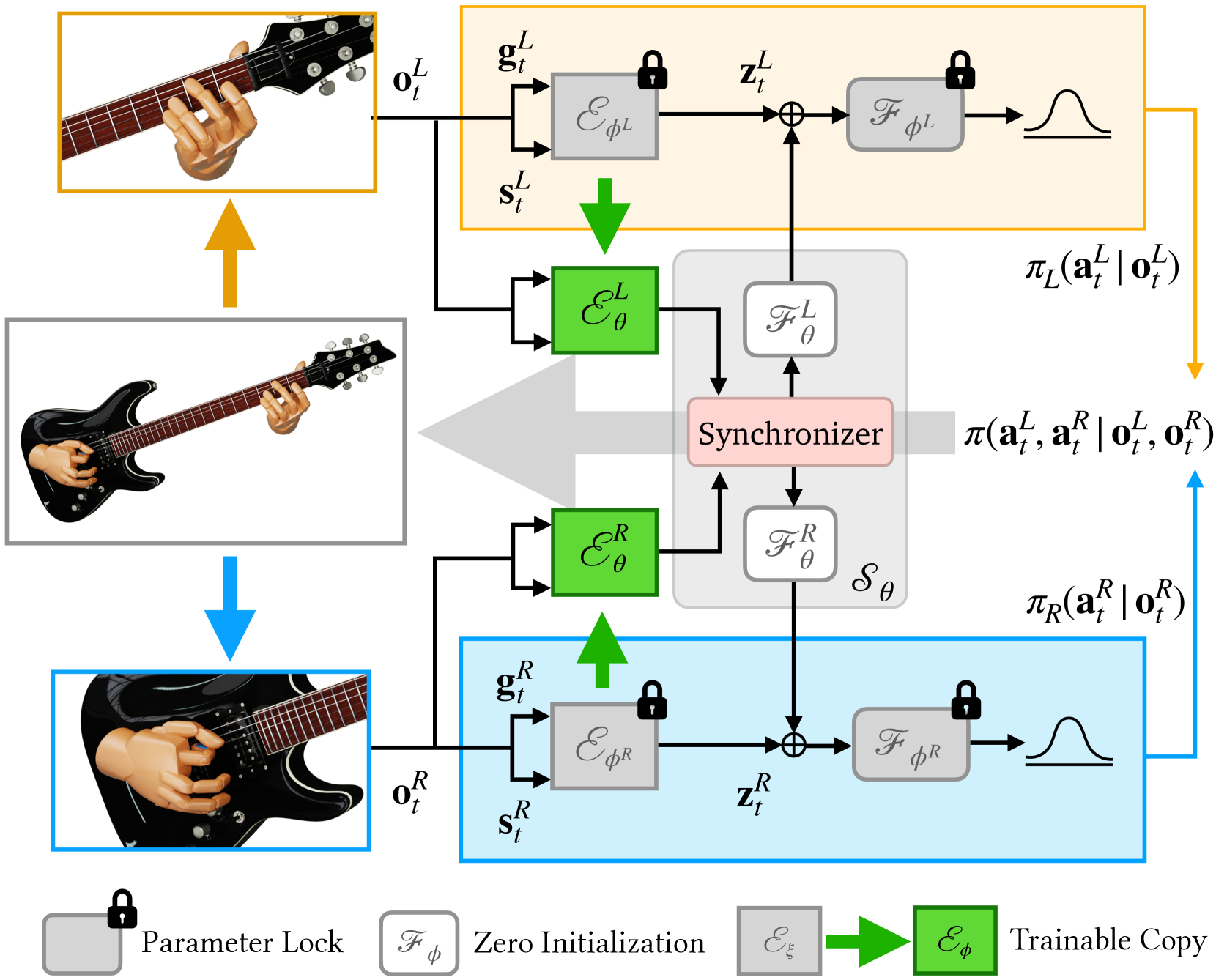
问题定义:该论文旨在解决物理模拟环境中,双手协同完成复杂任务(如吉他演奏)的动作生成问题。现有方法通常直接学习联合策略,但由于双手控制涉及高维状态-动作空间,导致训练难度大、效率低。尤其是在需要精确时间同步的任务中,问题更加突出。
核心思路:论文的核心思路是将双手的控制解耦,分别训练每只手的策略,然后通过一个集中的环境将这些策略同步起来。这种合作学习的方式避免了直接在高维联合空间中进行策略学习,从而降低了问题的复杂度,提高了训练效率。
技术框架:整体框架包含以下几个主要阶段:1) 单手策略训练:分别训练左手和右手的独立策略。2) 潜在空间同步:通过集中的环境,利用潜在空间操作将两个独立策略同步,形成双手的联合策略。3) 动作生成:根据输入的吉他谱,利用训练好的联合策略生成双手协同的吉他演奏动作。
关键创新:该论文的关键创新在于提出了基于合作学习的双手协同控制方法。与直接学习联合策略相比,该方法将问题分解为两个更简单的单手策略学习问题,并通过潜在空间同步实现双手协同。这种解耦和同步的策略能够有效降低问题的复杂度,提高训练效率。
关键设计:论文中可能涉及的关键设计包括:1) 单手策略的网络结构设计,例如使用循环神经网络(RNN)来处理时序信息。2) 潜在空间的维度和表示方式,以及如何通过潜在空间操作实现策略同步。3) 损失函数的设计,例如使用模仿学习损失来学习参考动作,并使用奖励函数来鼓励完成任务。
🖼️ 关键图片


📊 实验亮点
该论文在吉他演奏任务中验证了所提出方法的有效性。实验结果表明,该方法能够根据吉他谱生成复杂的和弦按压和拨弦动作,并且能够准确地演奏各种节奏。与直接学习联合策略的方法相比,该方法在训练效率方面有显著提升。此外,论文还提供了收集的动作捕捉数据,为相关研究提供了宝贵的资源。
🎯 应用场景
该研究成果可应用于虚拟现实、游戏开发、机器人控制等领域。例如,可以用于创建更逼真的虚拟乐器演奏体验,或者用于训练机器人完成需要双手协同的复杂操作,如装配、医疗手术等。此外,该方法还可以推广到其他需要多智能体协同控制的任务中,具有广泛的应用前景。
📄 摘要(原文)
We present a novel approach to synthesize dexterous motions for physically simulated hands in tasks that require coordination between the control of two hands with high temporal precision. Instead of directly learning a joint policy to control two hands, our approach performs bimanual control through cooperative learning where each hand is treated as an individual agent. The individual policies for each hand are first trained separately, and then synchronized through latent space manipulation in a centralized environment to serve as a joint policy for two-hand control. By doing so, we avoid directly performing policy learning in the joint state-action space of two hands with higher dimensions, greatly improving the overall training efficiency. We demonstrate the effectiveness of our proposed approach in the challenging guitar-playing task. The virtual guitarist trained by our approach can synthesize motions from unstructured reference data of general guitar-playing practice motions, and accurately play diverse rhythms with complex chord pressing and string picking patterns based on the input guitar tabs that do not exist in the references. Along with this paper, we provide the motion capture data that we collected as the reference for policy training. Code is available at: https://pei-xu.github.io/guitar.