Robust Dual Gaussian Splatting for Immersive Human-centric Volumetric Videos
作者: Yuheng Jiang, Zhehao Shen, Yu Hong, Chengcheng Guo, Yize Wu, Yingliang Zhang, Jingyi Yu, Lan Xu
分类: cs.GR, cs.CV
发布日期: 2024-09-12
备注: Accepted at SIGGRAPH Asia 2024. Project page: https://nowheretrix.github.io/DualGS/
💡 一句话要点
提出DualGS,用于高保真、高压缩率的人体动态体积视频实时渲染
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 体积视频 高斯溅射 人体动态 运动解耦 实时渲染
📋 核心要点
- 现有体积视频工作流程需要大量手动干预来稳定网格序列,并生成过大的资产,阻碍了其广泛应用。
- DualGS通过分离运动和外观,分别用皮肤高斯和关节高斯表示,从而减少运动冗余并增强时间一致性。
- 该方法实现了高达120倍的压缩率,每帧仅需约350KB的存储空间,并在VR环境中实现了逼真的自由视角体验。
📝 摘要(中文)
本文提出了一种基于高斯分布的新方法DualGS,用于对复杂人体表演进行实时、高保真回放,并具有出色的压缩率。DualGS的核心思想是使用皮肤高斯和关节高斯分别表示运动和外观。这种显式的解耦可以显著减少运动冗余并增强时间一致性。首先初始化DualGS,并将皮肤高斯锚定到第一帧的关节高斯。然后,采用由粗到精的训练策略,逐帧建模人体表演,包括用于整体运动预测的粗对齐阶段,以及用于鲁棒跟踪和高保真渲染的精细优化阶段。为了将体积视频无缝集成到VR环境中,使用熵编码高效压缩运动,并使用编解码器压缩外观,同时结合持久代码本。该方法实现了高达120倍的压缩率,每帧仅需约350KB的存储空间。实验证明了该表示的有效性,通过VR头显上的逼真自由视角体验,使用户能够身临其境地观看音乐家的表演,并感受表演者指尖的音符节奏。
🔬 方法详解
问题定义:现有体积视频方法在处理复杂人体动态时,需要大量的人工干预来稳定网格序列,并且生成的数据量非常庞大,这限制了其在实际应用中的部署。这些方法难以在保证高保真度的同时,实现高效的压缩和实时渲染。
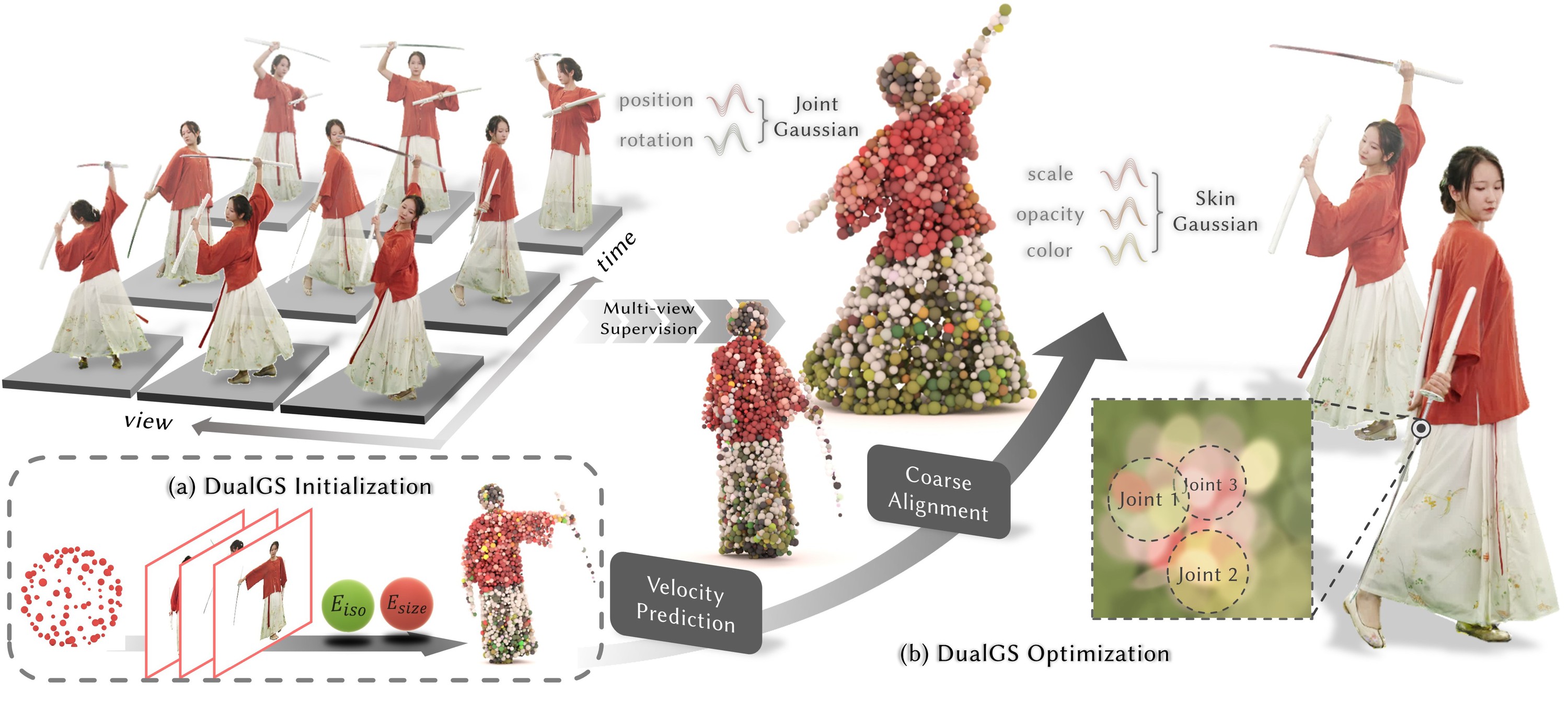
核心思路:DualGS的核心思路是将人体动态的运动和外观信息进行解耦,分别使用关节高斯和皮肤高斯进行表示。通过这种解耦,可以有效地减少运动信息的冗余,并提高时间一致性,从而实现更高的压缩率和更稳定的渲染效果。
技术框架:DualGS的整体框架包括初始化、粗对齐和精细优化三个阶段。首先,在第一帧初始化DualGS,并将皮肤高斯锚定到关节高斯。然后,通过粗对齐阶段进行整体运动预测,利用关节高斯估计皮肤高斯的大致位置。最后,通过精细优化阶段,对皮肤高斯的位置、形状和颜色进行优化,以实现鲁棒的跟踪和高保真渲染。为了实现高效的压缩,DualGS使用熵编码压缩运动信息,并使用编解码器压缩外观信息,同时结合持久代码本。
关键创新:DualGS的关键创新在于将运动和外观进行解耦表示。与传统的基于网格或单一高斯表示的方法相比,DualGS能够更有效地捕捉人体动态的复杂运动模式,并减少运动冗余。此外,DualGS采用由粗到精的训练策略,可以有效地提高跟踪的鲁棒性和渲染的质量。
关键设计:在初始化阶段,皮肤高斯的位置和形状是根据第一帧的网格数据估计的。粗对齐阶段使用关节高斯的位置来预测皮肤高斯的位置,可以使用简单的线性模型或更复杂的非线性模型。精细优化阶段使用光度损失和正则化项来优化皮肤高斯的位置、形状和颜色。光度损失衡量渲染图像与真实图像之间的差异,正则化项用于约束高斯分布的形状和大小,防止过拟合。运动信息的压缩采用熵编码,外观信息的压缩采用标准的视频编解码器,例如H.264或H.265。
🖼️ 关键图片


📊 实验亮点
DualGS实现了高达120倍的压缩率,每帧仅需约350KB的存储空间。在VR环境中,DualGS能够实现逼真的自由视角体验,用户可以自由地观看和互动。与现有的体积视频方法相比,DualGS在压缩率、渲染质量和实时性方面都取得了显著的提升。
🎯 应用场景
DualGS在虚拟现实、增强现实、游戏、远程呈现等领域具有广泛的应用前景。它可以用于创建逼真的虚拟化身,实现沉浸式的远程协作和娱乐体验。例如,用户可以在VR环境中观看音乐家的表演,并感受到身临其境的互动。此外,DualGS还可以用于运动分析、人体姿态估计等研究领域。
📄 摘要(原文)
Volumetric video represents a transformative advancement in visual media, enabling users to freely navigate immersive virtual experiences and narrowing the gap between digital and real worlds. However, the need for extensive manual intervention to stabilize mesh sequences and the generation of excessively large assets in existing workflows impedes broader adoption. In this paper, we present a novel Gaussian-based approach, dubbed \textit{DualGS}, for real-time and high-fidelity playback of complex human performance with excellent compression ratios. Our key idea in DualGS is to separately represent motion and appearance using the corresponding skin and joint Gaussians. Such an explicit disentanglement can significantly reduce motion redundancy and enhance temporal coherence. We begin by initializing the DualGS and anchoring skin Gaussians to joint Gaussians at the first frame. Subsequently, we employ a coarse-to-fine training strategy for frame-by-frame human performance modeling. It includes a coarse alignment phase for overall motion prediction as well as a fine-grained optimization for robust tracking and high-fidelity rendering. To integrate volumetric video seamlessly into VR environments, we efficiently compress motion using entropy encoding and appearance using codec compression coupled with a persistent codebook. Our approach achieves a compression ratio of up to 120 times, only requiring approximately 350KB of storage per frame. We demonstrate the efficacy of our representation through photo-realistic, free-view experiences on VR headsets, enabling users to immersively watch musicians in performance and feel the rhythm of the notes at the performers' fingertips.