Potamoi: Accelerating Neural Rendering via a Unified Streaming Architecture
作者: Yu Feng, Weikai Lin, Zihan Liu, Jingwen Leng, Minyi Guo, Han Zhao, Xiaofeng Hou, Jieru Zhao, Yuhao Zhu
分类: cs.AR, cs.GR
发布日期: 2024-08-13
备注: arXiv admin note: substantial text overlap with arXiv:2404.11852
💡 一句话要点
Potamoi:通过统一流式架构加速神经渲染,实现实时高性能。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 神经渲染 NeRF 算法-架构协同设计 实时渲染 流式架构
📋 核心要点
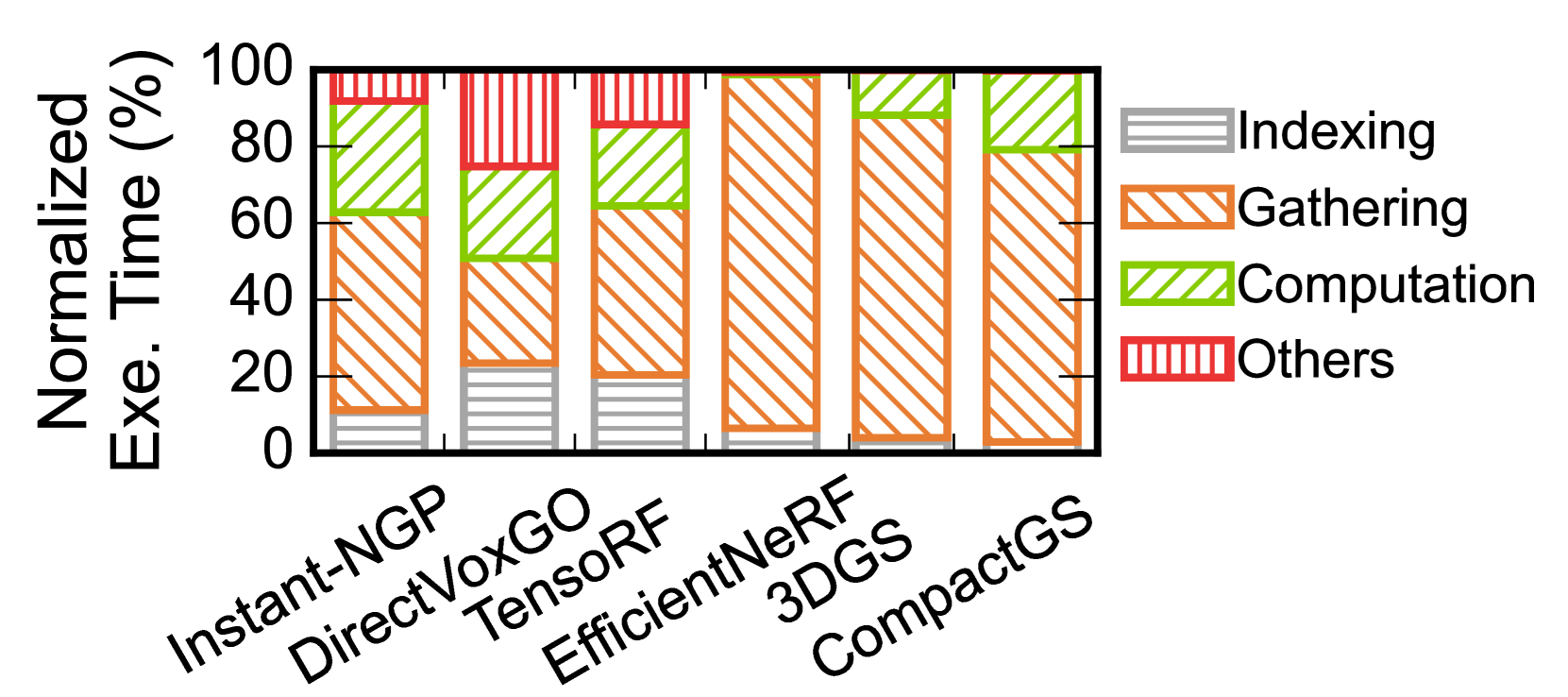
- 现有NeRF算法在资源受限设备上难以实现实时渲染,主要瓶颈在于计算量大和访存效率低。
- Potamoi提出了一种统一的算法-架构协同设计,包含即插即用算法SpaRW和统一流式pipeline,优化计算和访存。
- 实验表明,Potamoi相比于专用DNN加速器,实现了53.1倍的加速和67.7倍的能耗降低,视觉质量损失小于1dB。
📝 摘要(中文)
神经辐射场(NeRF)已成为照片级真实感渲染的一种有前景的替代方案。尽管最近算法取得了进展,但在当今资源受限的设备上实现实时性能仍然具有挑战性。本文确定了当前NeRF算法的主要瓶颈,并引入了一种统一的算法-架构协同设计Potamoi,旨在适应各种NeRF算法。具体来说,我们引入了一个具有即插即用算法SpaRW的运行时系统,该系统显著降低了每帧的计算工作量,并减轻了计算效率低下的问题。此外,我们的统一流式pipeline与定制的硬件支持相结合,通过最小化重复的DRAM访问并完全消除SRAM bank冲突,有效地解决了SRAM和DRAM效率低下的问题。与使用专用DNN加速器的基线相比,我们的框架展示了53.1倍的加速和67.7倍的能量降低,同时保持了较高的视觉质量,峰值信噪比降低小于1.0 dB。
🔬 方法详解
问题定义:NeRF在资源受限设备上实时渲染面临挑战,主要痛点在于计算复杂度高,导致计算效率低下;同时,频繁的DRAM访问和SRAM bank冲突导致访存效率低下,成为性能瓶颈。
核心思路:Potamoi的核心思路是算法-架构协同设计,通过优化算法降低计算量,并通过统一流式架构优化访存,从而在保证视觉质量的前提下,显著提升NeRF的渲染速度和能效。SpaRW算法降低每帧计算量,统一流式pipeline减少DRAM访问和SRAM冲突。
技术框架:Potamoi包含两个主要部分:一是即插即用的算法SpaRW,用于降低计算复杂度;二是统一流式pipeline,用于优化访存。运行时系统负责调度SpaRW算法,并管理数据在pipeline中的流动。定制硬件支持进一步优化了pipeline的性能。整体流程是从输入图像开始,经过SpaRW算法处理,然后通过流式pipeline进行渲染,最终输出渲染结果。
关键创新:Potamoi的关键创新在于统一的算法-架构协同设计。SpaRW算法和统一流式pipeline的结合,能够有效地解决NeRF在资源受限设备上的性能瓶颈。即插即用的算法设计使得Potamoi能够灵活地适应不同的NeRF算法。
关键设计:SpaRW算法的具体细节未知,但其目标是降低每帧的计算量。统一流式pipeline的关键设计在于最小化重复的DRAM访问和完全消除SRAM bank冲突。具体的参数设置、损失函数和网络结构等技术细节在论文中未详细描述,需要参考相关文献。
🖼️ 关键图片


📊 实验亮点
Potamoi框架在实验中表现出色,与使用专用DNN加速器的基线相比,实现了53.1倍的加速和67.7倍的能量降低,同时保持了较高的视觉质量,峰值信噪比降低小于1.0 dB。这表明Potamoi在提升NeRF渲染性能和能效方面具有显著优势。
🎯 应用场景
该研究成果可应用于移动设备、AR/VR设备等资源受限平台上的实时神经渲染,例如移动端的3D游戏、AR/VR场景的实时渲染、以及需要低功耗高性能渲染的应用场景。未来,该技术有望推动神经渲染在嵌入式设备上的普及,并为用户带来更逼真、更流畅的视觉体验。
📄 摘要(原文)
Neural Radiance Field (NeRF) has emerged as a promising alternative for photorealistic rendering. Despite recent algorithmic advancements, achieving real-time performance on today's resource-constrained devices remains challenging. In this paper, we identify the primary bottlenecks in current NeRF algorithms and introduce a unified algorithm-architecture co-design, Potamoi, designed to accommodate various NeRF algorithms. Specifically, we introduce a runtime system featuring a plug-and-play algorithm, SpaRW, which significantly reduces the per-frame computational workload and alleviates compute inefficiencies. Furthermore, our unified streaming pipeline coupled with customized hardware support effectively tames both SRAM and DRAM inefficiencies by minimizing repetitive DRAM access and completely eliminating SRAM bank conflicts. When evaluated against a baseline utilizing a dedicated DNN accelerator, our framework demonstrates a speed-up and energy reduction of 53.1$\times$ and 67.7$\times$, respectively, all while maintaining high visual quality with less than a 1.0 dB reduction in peak signal-to-noise ratio.