Sampling for View Synthesis: From Local Light Field Fusion to Neural Radiance Fields and Beyond
作者: Ravi Ramamoorthi
分类: cs.GR, cs.AI, cs.CV, cs.LG
发布日期: 2024-08-08
备注: Article written for Frontiers of Science Award, International Congress on Basic Science, 2024
💡 一句话要点
提出局部光场融合算法,结合采样理论指导稀疏视角合成,并探讨神经辐射场应用前景。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视角合成 图像渲染 局部光场融合 全光函数采样 神经辐射场
📋 核心要点
- 现有视角合成方法要么需要密集采样,要么缺乏采样指导,导致实际应用受限。
- 论文提出局部光场融合算法,通过扩展全光函数采样理论,指导用户如何稀疏采样视角。
- 实验表明,该算法在保证感知质量的前提下,可将视角数量减少高达4000倍。
📝 摘要(中文)
捕捉和渲染复杂真实世界场景的新视角是一个长期存在的计算机图形学和视觉问题,在增强现实、虚拟现实、沉浸式体验和3D摄影等领域有广泛应用。深度学习的出现推动了该领域革命性的进步,该领域传统上被称为基于图像的渲染。然而,先前的方法需要难以处理的密集视角采样,或者对于用户应该如何采样场景视角以可靠地渲染高质量的新视角几乎没有或根本没有指导。局部光场融合提出了一种从不规则网格的采样视角进行实际视角合成的算法,该算法首先通过多平面图像场景表示将每个采样视角扩展到局部光场,然后通过混合相邻的局部光场来渲染新视角。至关重要的是,我们扩展了传统的全光函数采样理论,以推导出精确指定用户在使用我们的算法时应该如何密集地采样给定场景视角的界限。我们实现了奈奎斯特速率视角采样的感知质量,同时使用的视角减少了高达4000倍。随后的发展导致了用于深度学习和视角合成的新场景表示,特别是神经辐射场,但是从少量图像进行稀疏视角合成的问题变得越来越重要。我们重述了一些关于稀疏甚至单图像视角合成的最新结果,同时提出了对于新一代基于图像的渲染算法,规定性采样指南是否可行的问题。
🔬 方法详解
问题定义:论文旨在解决从少量采样视角高质量合成新视角的问题。现有方法要么需要极其密集的视角采样,这在实际应用中难以实现;要么缺乏明确的采样指导,用户难以确定如何采样才能保证合成质量。这限制了基于图像渲染技术在增强现实、虚拟现实等领域的应用。
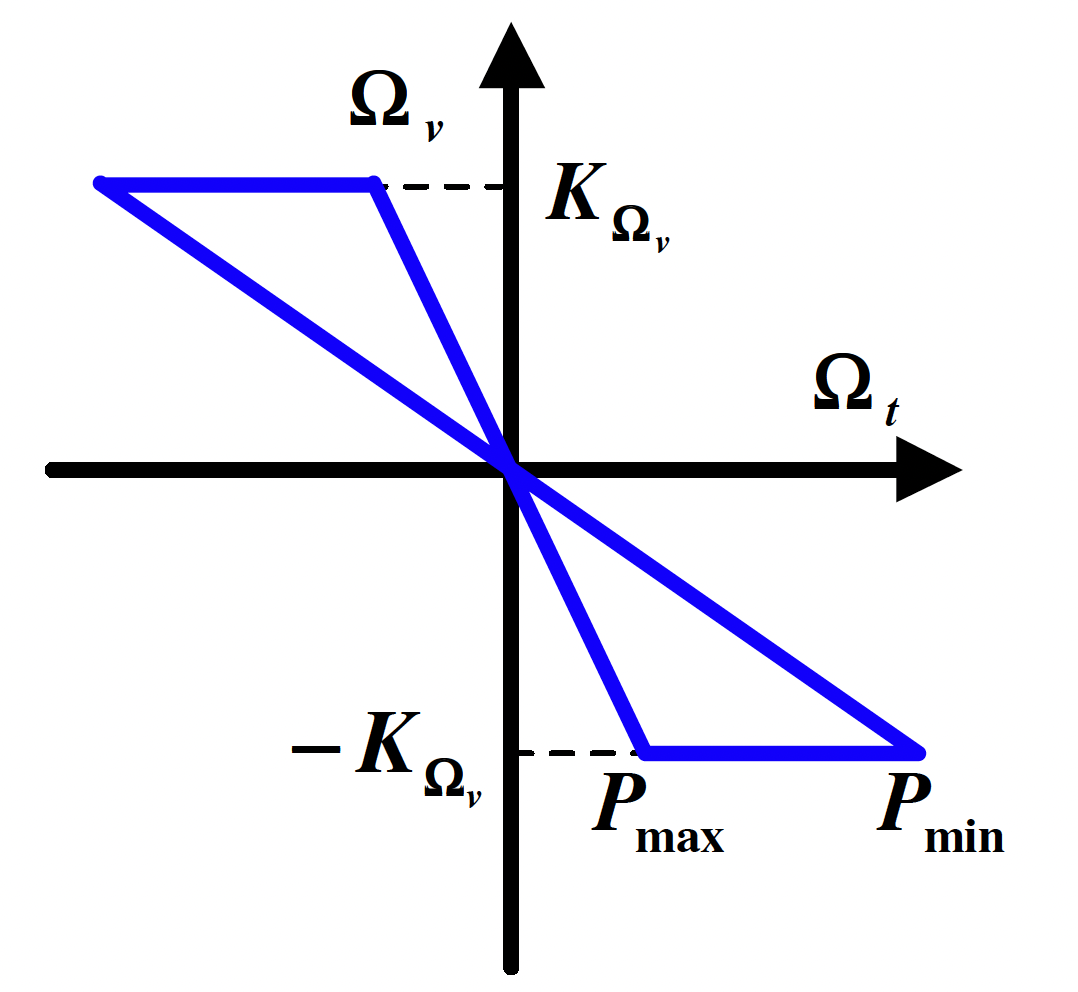
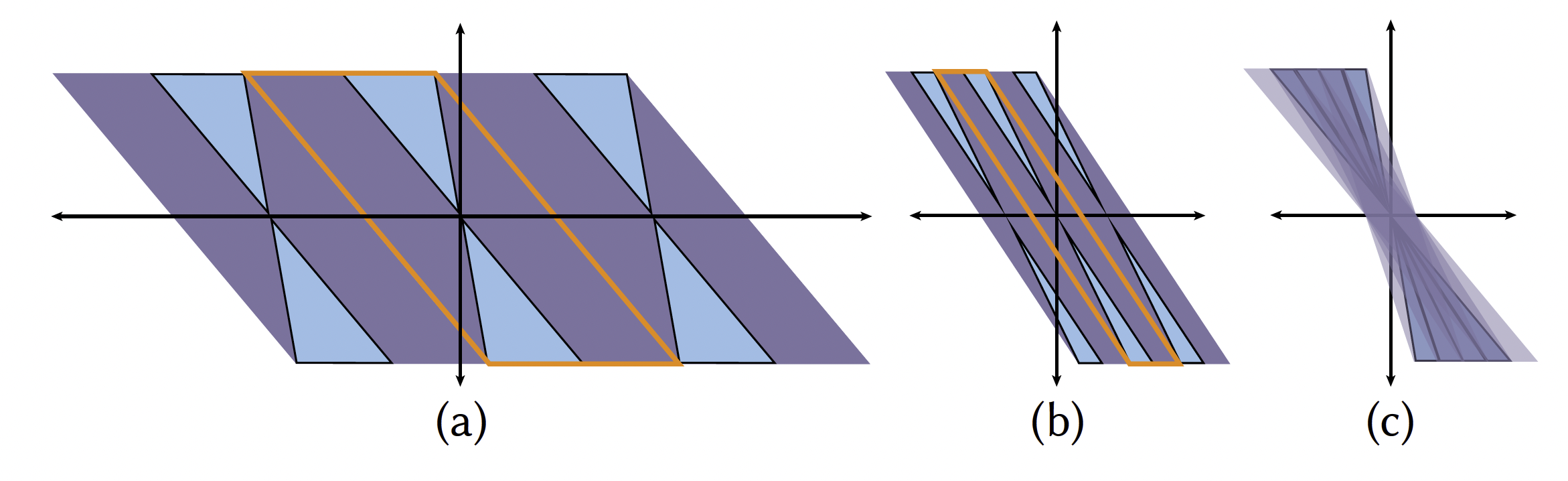
核心思路:论文的核心思路是将每个采样视角扩展成一个局部光场,然后通过融合相邻的局部光场来渲染新视角。关键在于扩展了传统的全光函数采样理论,推导出一个采样界限,指导用户如何根据场景复杂度进行稀疏采样,从而在保证合成质量的前提下,显著减少所需的视角数量。
技术框架:该方法主要包含以下几个阶段:1) 视角采样:根据扩展的全光函数采样理论,对场景进行稀疏视角采样。2) 局部光场构建:将每个采样视角扩展成一个局部光场,通过多平面图像(MPI)表示场景。3) 视角合成:通过融合相邻的局部光场来渲染新视角。
关键创新:最重要的技术创新在于扩展了传统的全光函数采样理论,推导出了一个采样界限,该界限明确指定了在给定场景下,为了保证合成质量,用户应该如何密集地采样视角。这与现有方法依赖于密集采样或缺乏采样指导形成了本质区别。
关键设计:论文的关键设计包括:1) 使用多平面图像(MPI)作为局部光场的表示,MPI能够有效地捕捉场景的视差和遮挡信息。2) 提出了一种局部光场融合算法,通过加权平均相邻局部光场的颜色值来渲染新视角。3) 推导出的采样界限与场景的深度变化有关,深度变化越大,所需的采样密度越高。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该算法在保证感知质量的前提下,可以将视角数量减少高达4000倍。这意味着可以使用更少的图像来合成高质量的新视角,从而显著降低了数据采集和存储成本。该算法的性能优于现有的基于图像的渲染方法,为稀疏视角合成提供了一种有效的解决方案。
🎯 应用场景
该研究成果可广泛应用于增强现实、虚拟现实、3D摄影等领域。通过稀疏视角合成,可以降低数据采集成本,提高渲染效率,从而为用户提供更便捷、更沉浸式的体验。此外,该研究对于开发新一代基于图像的渲染算法具有重要指导意义,有望推动相关技术的发展。
📄 摘要(原文)
Capturing and rendering novel views of complex real-world scenes is a long-standing problem in computer graphics and vision, with applications in augmented and virtual reality, immersive experiences and 3D photography. The advent of deep learning has enabled revolutionary advances in this area, classically known as image-based rendering. However, previous approaches require intractably dense view sampling or provide little or no guidance for how users should sample views of a scene to reliably render high-quality novel views. Local light field fusion proposes an algorithm for practical view synthesis from an irregular grid of sampled views that first expands each sampled view into a local light field via a multiplane image scene representation, then renders novel views by blending adjacent local light fields. Crucially, we extend traditional plenoptic sampling theory to derive a bound that specifies precisely how densely users should sample views of a given scene when using our algorithm. We achieve the perceptual quality of Nyquist rate view sampling while using up to 4000x fewer views. Subsequent developments have led to new scene representations for deep learning with view synthesis, notably neural radiance fields, but the problem of sparse view synthesis from a small number of images has only grown in importance. We reprise some of the recent results on sparse and even single image view synthesis, while posing the question of whether prescriptive sampling guidelines are feasible for the new generation of image-based rendering algorithms.