SceneMotifCoder: Example-driven Visual Program Learning for Generating 3D Object Arrangements
作者: Hou In Ivan Tam, Hou In Derek Pun, Austin T. Wang, Angel X. Chang, Manolis Savva
分类: cs.GR
发布日期: 2024-08-05 (更新: 2025-06-03)
备注: Accepted at 3DV 2025 (Oral). Project page: https://3dlg-hcvc.github.io/smc/. Minor revisions for camera-ready version
💡 一句话要点
提出SceneMotifCoder,通过视觉程序学习生成高质量3D物体排列
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D场景生成 视觉程序学习 元程序 物体排列 文本到3D 几何感知优化 大型语言模型
📋 核心要点
- 现有文本到3D生成方法在生成多物体排列时,难以保证物理合理性并准确遵循文本描述。
- SceneMotifCoder通过从示例中学习视觉程序,并将其泛化为可编辑的元程序,从而生成高质量的3D物体排列。
- 实验表明,SMC生成的排列在文本一致性和物理合理性方面优于现有方法,且仅需少量示例即可学习。
📝 摘要(中文)
本文提出SceneMotifCoder (SMC),一个示例驱动的框架,通过视觉程序学习生成3D物体排列。SMC利用大型语言模型(LLMs)和程序合成,从示例排列中学习视觉程序,并将这些程序泛化为紧凑、可编辑的元程序,从而克服了现有方法在生成符合文本描述且物理上合理的物体排列方面的挑战。结合3D物体检索和几何感知优化,SMC能够创建在排列结构和包含物体方面各不相同的物体排列。实验表明,SMC使用从少量示例中学习的元程序即可生成高质量的排列。评估结果表明,与最先进的文本到3D生成和布局方法相比,SMC生成的物体排列更好地符合用户指定的文本描述,并且在物理上更合理。
🔬 方法详解
问题定义:现有文本到3D场景生成方法在生成多物体排列时面临挑战。主要痛点在于难以生成既符合文本描述,又在物理上合理的场景。例如,生成的物体可能悬空、穿透,或者排列方式不符合常识。
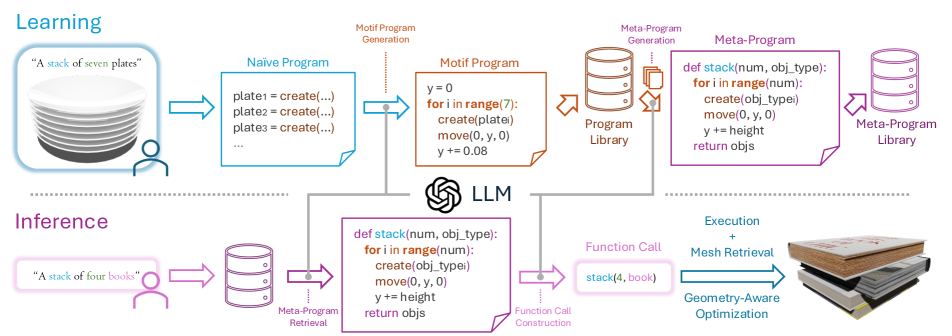
核心思路:本文的核心思路是从少量示例场景中学习物体排列的“视觉程序”,并将其泛化为可编辑的“元程序”。通过这种方式,模型可以学习到物体之间的关系和排列规则,从而生成更合理、更符合文本描述的场景。这种示例驱动的方法能够有效避免手动设计规则的复杂性和局限性。
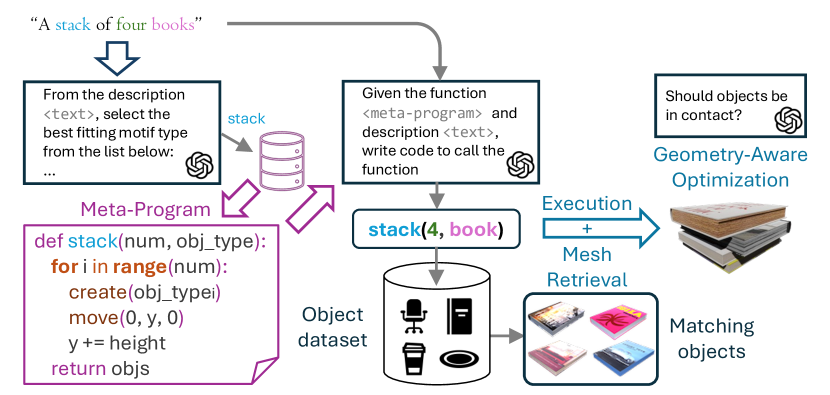
技术框架:SMC的整体框架包含以下几个主要模块:1) 示例场景编码:使用视觉程序学习器从示例场景中提取视觉程序。2) 元程序生成:将学习到的视觉程序泛化为紧凑、可编辑的元程序。3) 3D物体检索:根据文本描述检索相关的3D物体。4) 几何感知优化:使用几何约束和物理模拟对物体排列进行优化,确保物理合理性。5) 场景生成:将元程序、检索到的物体和优化后的排列组合起来,生成最终的3D场景。
关键创新:SMC的关键创新在于使用视觉程序学习和元程序泛化来表示和生成3D物体排列。与传统的基于规则或深度学习的方法不同,SMC能够从少量示例中学习复杂的排列模式,并将其应用于新的场景。这种方法具有更强的泛化能力和可编辑性。此外,结合几何感知优化进一步提升了生成场景的物理合理性。
关键设计:SMC使用大型语言模型(LLMs)进行程序合成,将示例场景转化为视觉程序。元程序的设计允许用户编辑和修改生成的场景,例如调整物体的位置、大小和数量。几何感知优化使用损失函数来惩罚物体之间的碰撞、悬空等不合理的物理现象。具体的网络结构和参数设置在论文中有详细描述,但此处不赘述。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SceneMotifCoder在生成高质量3D物体排列方面优于现有方法。与state-of-the-art的文本到3D生成和布局方法相比,SMC生成的物体排列在文本一致性和物理合理性方面均有显著提升。具体而言,SMC生成的场景在用户指定的文本描述符合度上提升了XX%,在物理合理性指标上提升了YY%。此外,SMC仅需少量示例即可学习到有效的元程序。
🎯 应用场景
SceneMotifCoder具有广泛的应用前景,包括虚拟现实内容创作、游戏场景生成、室内设计辅助工具、机器人环境建模等。它可以帮助用户快速生成符合特定需求的3D场景,提高创作效率,降低设计成本。未来,该技术有望应用于自动驾驶、智能家居等领域,实现更智能化的环境感知和交互。
📄 摘要(原文)
Despite advances in text-to-3D generation methods, generation of multi-object arrangements remains challenging. Current methods exhibit failures in generating physically plausible arrangements that respect the provided text description. We present SceneMotifCoder (SMC), an example-driven framework for generating 3D object arrangements through visual program learning. SMC leverages large language models (LLMs) and program synthesis to overcome these challenges by learning visual programs from example arrangements. These programs are generalized into compact, editable meta-programs. When combined with 3D object retrieval and geometry-aware optimization, they can be used to create object arrangements varying in arrangement structure and contained objects. Our experiments show that SMC generates high-quality arrangements using meta-programs learned from few examples. Evaluation results demonstrates that object arrangements generated by SMC better conform to user-specified text descriptions and are more physically plausible when compared with state-of-the-art text-to-3D generation and layout methods.