Face Anything: 4D Face Reconstruction from Any Image Sequence
作者: Umut Kocasari, Simon Giebenhain, Richard Shaw, Matthias Nießner
分类: cs.CV
发布日期: 2026-04-21
备注: Project website: https://kocasariumut.github.io/FaceAnything/ , Video: https://www.youtube.com/watch?v=wSGHpAscp0Y
💡 一句话要点
提出基于规范面部点预测的4D人脸重建方法,解决动态人脸重建中的几何和对应关系歧义问题。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 4D人脸重建 动态人脸 规范面部点预测 Transformer 深度估计
📋 核心要点
- 动态人脸重建面临非刚性形变、表情变化和视角变化带来的几何与对应关系估计的歧义性挑战。
- 论文提出基于规范面部点预测的方法,将动态重建转化为规范空间中的重建问题,实现时间一致性和可靠对应。
- 实验表明,该方法在重建和跟踪任务上达到SOTA,对应误差降低3倍,深度精度提升16%。
📝 摘要(中文)
本文提出了一种统一的方法,用于从图像序列中进行高保真4D人脸重建。该方法基于规范面部点预测,即为每个像素分配一个共享规范空间中的归一化面部坐标。这种方法将密集跟踪和动态重建转化为规范重建问题,从而在单个前馈模型中实现时间上一致的几何形状和可靠的对应关系。通过联合预测深度和规范坐标,该方法能够在单个架构中实现精确的深度估计、时间稳定的重建、密集的3D几何形状和鲁棒的面部点跟踪。该方法使用基于Transformer的模型实现,该模型联合预测深度和规范面部坐标,并使用非刚性地扭曲到规范空间中的多视图几何数据进行训练。在图像和视频基准上的大量实验表明,该方法在重建和跟踪任务中实现了最先进的性能,与先前的动态重建方法相比,对应误差降低了约3倍,推理速度更快,同时深度精度提高了16%。这些结果表明,规范面部点预测是统一前馈4D人脸重建的有效基础。
🔬 方法详解
问题定义:现有动态人脸重建方法难以同时处理非刚性形变、表情变化和视角变化,导致几何形状和对应关系估计存在显著歧义性。这些方法通常需要复杂的优化过程或多个阶段,计算成本高昂,且难以保证时间一致性。
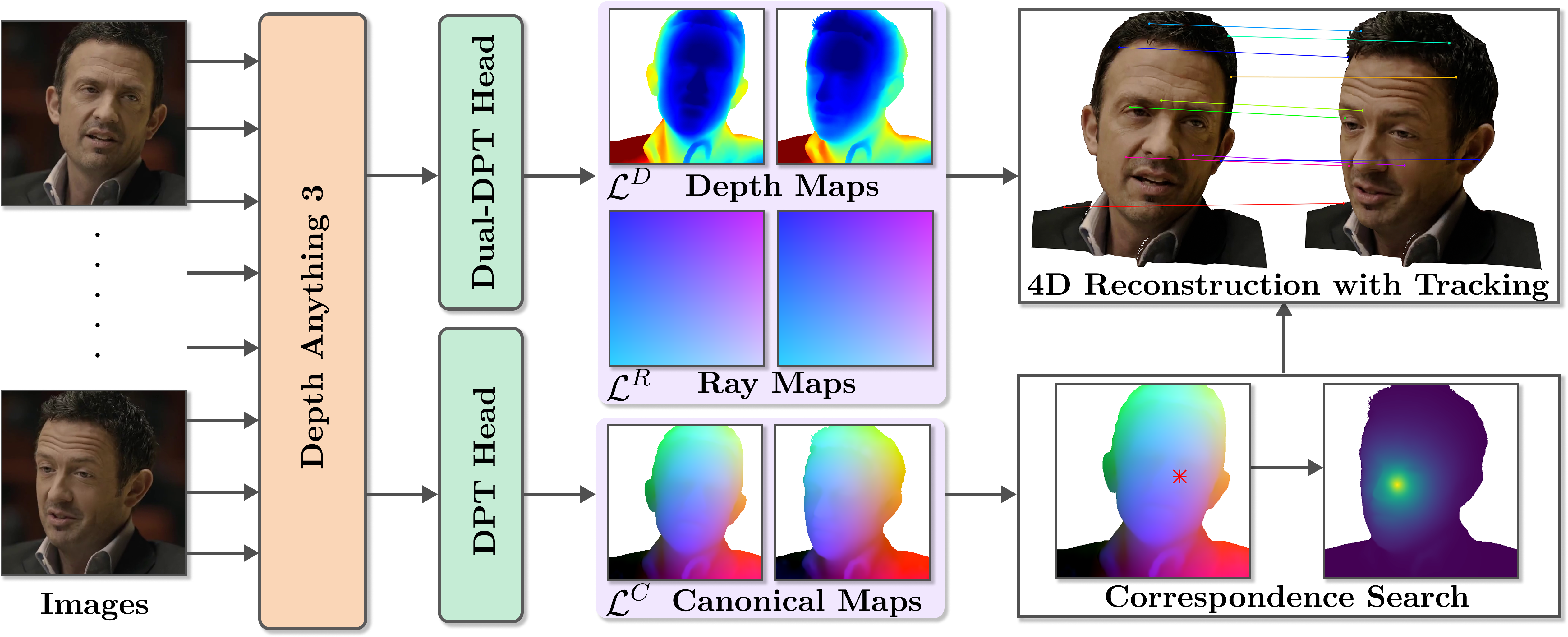
核心思路:论文的核心思路是将动态人脸重建问题转化为一个规范空间中的重建问题。通过预测每个像素在规范空间中的坐标(规范面部点),可以将不同姿态、表情的人脸映射到同一空间,从而简化了跟踪和重建过程。这种方法能够实现时间一致的几何形状和可靠的对应关系。
技术框架:该方法使用一个基于Transformer的模型,该模型以图像序列作为输入,并联合预测深度图和规范面部坐标。整个流程是一个端到端的学习过程,无需复杂的后处理。模型首先提取图像特征,然后使用Transformer进行特征融合和预测。最后,根据预测的深度图和规范面部坐标,重建出4D人脸模型。
关键创新:该方法最重要的创新点在于提出了“规范面部点预测”这一概念,并将动态人脸重建问题转化为规范空间中的重建问题。与传统方法相比,该方法无需显式地进行跟踪或对应关系估计,而是通过学习一个映射函数,直接将图像像素映射到规范空间中的坐标。
关键设计:模型使用Transformer作为核心架构,以捕捉图像中的长程依赖关系。损失函数包括深度损失和规范面部坐标损失,用于约束模型的预测结果。训练数据使用多视图几何数据,这些数据被非刚性地扭曲到规范空间中,以增强模型的泛化能力。具体来说,使用了L1损失来约束深度预测,并使用Chamfer距离来约束规范面部点预测。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在重建和跟踪任务中均取得了最先进的性能。在标准数据集上,该方法的对应误差比现有方法降低了约3倍,推理速度更快,同时深度精度提高了16%。这些结果验证了规范面部点预测作为统一前馈4D人脸重建基础的有效性。
🎯 应用场景
该研究成果可应用于虚拟现实、增强现实、人机交互、动画制作、安全监控等领域。例如,可以用于创建逼真的虚拟化身,实现更自然的人脸动画,或者用于身份验证和面部识别系统。该方法的高精度和高效率使其在实时应用中具有很大的潜力。
📄 摘要(原文)
Accurate reconstruction and tracking of dynamic human faces from image sequences is challenging because non-rigid deformations, expression changes, and viewpoint variations occur simultaneously, creating significant ambiguity in geometry and correspondence estimation. We present a unified method for high-fidelity 4D facial reconstruction based on canonical facial point prediction, a representation that assigns each pixel a normalized facial coordinate in a shared canonical space. This formulation transforms dense tracking and dynamic reconstruction into a canonical reconstruction problem, enabling temporally consistent geometry and reliable correspondences within a single feed-forward model. By jointly predicting depth and canonical coordinates, our method enables accurate depth estimation, temporally stable reconstruction, dense 3D geometry, and robust facial point tracking within a single architecture. We implement this formulation using a transformer-based model that jointly predicts depth and canonical facial coordinates, trained using multi-view geometry data that non-rigidly warps into the canonical space. Extensive experiments on image and video benchmarks demonstrate state-of-the-art performance across reconstruction and tracking tasks, achieving approximately 3$\times$ lower correspondence error and faster inference than prior dynamic reconstruction methods, while improving depth accuracy by 16%. These results highlight canonical facial point prediction as an effective foundation for unified feed-forward 4D facial reconstruction.