Adapting Foundation Models for Annotation-Efficient Adnexal Mass Segmentation in Cine Images
作者: Francesca Fati, Alberto Rota, Adriana V. Gregory, Anna Catozzo, Maria C. Giuliano, Mrinal Dhar, Luigi De Vitis, Annie T. Packard, Francesco Multinu, Elena De Momi, Carrie L. Langstraat, Timothy L. Kline
分类: cs.CV
发布日期: 2026-04-09
🔗 代码/项目: GITHUB
💡 一句话要点
利用预训练DINOv3,高效标注的电影图像附件肿块分割
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 附件肿块分割 超声图像 DINOv3 自监督学习 Transformer 医学图像分割 数据高效 DPT解码器
📋 核心要点
- 超声附件肿块评估易受主观影响,传统全监督分割方法需要大量标注且泛化性差。
- 利用预训练DINOv3的语义先验,结合DPT解码器,实现全局语义和局部细节融合。
- 实验表明,该方法在数据量不足时仍表现出色,Dice系数达0.945,Hausdorff距离降低11.4%。
📝 摘要(中文)
通过超声评估附件肿块是一项具有挑战性的临床任务,通常受到主观解释和观察者间差异的影响。自动分割是定量风险评估的基础步骤,但传统的全监督卷积架构通常需要大量的像素级标注,并且难以应对医学成像中常见的领域转移。本文提出了一种标签高效的分割框架,该框架利用了预训练的DINOv3基础视觉Transformer主干网络的强大语义先验。通过将该主干网络与Dense Prediction Transformer (DPT)风格的解码器集成,我们的模型分层地重新组合多尺度特征,以结合全局语义表示和细粒度的空间细节。在来自112名患者的7777个带注释帧的临床数据集上进行评估,与已建立的全监督基线(包括U-Net、U-Net++、DeepLabV3和MAnet)相比,我们的方法实现了最先进的性能。具体而言,我们获得了0.945的Dice分数,并提高了边界依从性,相对于最强的卷积基线,95百分位数的Hausdorff距离降低了11.4%。此外,我们进行了广泛的效率分析,表明我们的基于DINOv3的方法在数据匮乏的情况下保持了显著更高的性能,即使仅在25%的数据上进行训练也能保持强大的结果。这些结果表明,利用大规模自监督基础模型为数据受限的临床环境中的医学图像分割提供了一种有前景且数据高效的解决方案。
🔬 方法详解
问题定义:论文旨在解决附件肿块超声图像分割问题,现有全监督方法依赖大量精确标注,标注成本高昂,且模型泛化能力受限,难以适应不同超声设备和患者间的差异。
核心思路:利用大规模自监督学习得到的预训练视觉Transformer模型(DINOv3)所学习到的通用视觉特征,将其作为分割模型的主干网络,从而减少对特定任务标注数据的依赖,提高模型的泛化能力和数据利用率。
技术框架:该方法采用编码器-解码器结构。编码器部分使用预训练的DINOv3视觉Transformer提取图像特征。解码器部分采用DPT (Dense Prediction Transformer) 风格的解码器,用于将编码器提取的多尺度特征进行融合,并生成最终的分割结果。整体流程为:输入超声图像 -> DINOv3编码器提取特征 -> DPT解码器融合特征 -> 输出分割结果。
关键创新:关键创新在于将大规模自监督学习得到的视觉Transformer模型应用于医学图像分割任务。与传统方法相比,该方法能够利用预训练模型所学习到的通用视觉知识,从而减少对特定任务标注数据的依赖,提高模型的泛化能力。
关键设计:DINOv3作为主干网络,其预训练权重被初始化并进行微调。DPT解码器采用多尺度特征融合策略,将不同尺度的特征进行有效组合,以获得更精确的分割结果。损失函数方面,可能采用了Dice loss或交叉熵损失函数,以优化分割性能。具体参数设置和网络结构细节可能在论文附录或补充材料中。
🖼️ 关键图片


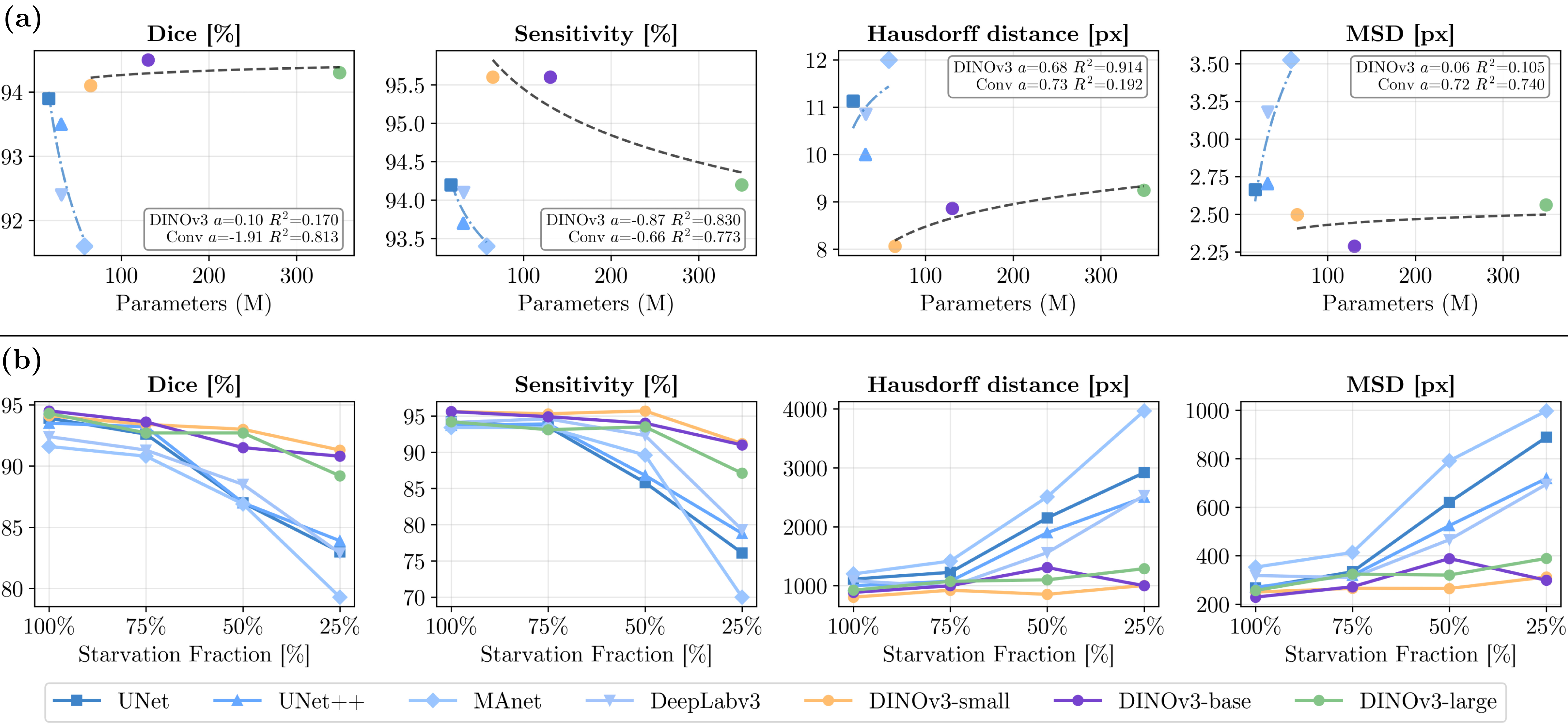
📊 实验亮点
该方法在临床数据集上取得了state-of-the-art的性能,Dice系数达到0.945,并且显著提高了边界依从性,95百分位数的Hausdorff距离相对于最强的卷积基线降低了11.4%。更重要的是,该方法在数据量不足的情况下仍能保持良好的性能,即使只使用25%的数据进行训练,也能取得令人满意的结果,体现了其数据高效性。
🎯 应用场景
该研究成果可应用于辅助医生进行附件肿块的超声图像诊断,提高诊断效率和准确性,减少主观误差。该方法具有数据高效性,尤其适用于标注数据匮乏的医疗场景。未来可推广至其他医学图像分割任务,例如肿瘤分割、器官分割等,具有广阔的应用前景。
📄 摘要(原文)
Adnexal mass evaluation via ultrasound is a challenging clinical task, often hindered by subjective interpretation and significant inter-observer variability. While automated segmentation is a foundational step for quantitative risk assessment, traditional fully supervised convolutional architectures frequently require large amounts of pixel-level annotations and struggle with domain shifts common in medical imaging. In this work, we propose a label-efficient segmentation framework that leverages the robust semantic priors of a pretrained DINOv3 foundational vision transformer backbone. By integrating this backbone with a Dense Prediction Transformer (DPT)-style decoder, our model hierarchically reassembles multi-scale features to combine global semantic representations with fine-grained spatial details. Evaluated on a clinical dataset of 7,777 annotated frames from 112 patients, our method achieves state-of-the-art performance compared to established fully supervised baselines, including U-Net, U-Net++, DeepLabV3, and MAnet. Specifically, we obtain a Dice score of 0.945 and improved boundary adherence, reducing the 95th-percentile Hausdorff Distance by 11.4% relative to the strongest convolutional baseline. Furthermore, we conduct an extensive efficiency analysis demonstrating that our DINOv3-based approach retains significantly higher performance under data starvation regimes, maintaining strong results even when trained on only 25% of the data. These results suggest that leveraging large-scale self-supervised foundations provides a promising and data-efficient solution for medical image segmentation in data-constrained clinical environments. Project Repository: https://github.com/FrancescaFati/MESA