RAD: Retrieval-Augmented Monocular Metric Depth Estimation for Underrepresented Classes
作者: Michael Baltaxe, Dan Levi, Sagie Benaim
分类: cs.CV
发布日期: 2026-04-07
💡 一句话要点
RAD:检索增强的单目深度估计,提升欠表示类别的深度预测精度
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 单目深度估计 检索增强学习 欠表示类别 几何信息融合 交叉注意力机制
📋 核心要点
- 现有单目深度估计方法在处理复杂场景中欠表示类别时,深度预测精度显著下降,成为制约物理智能系统发展的瓶颈。
- RAD框架利用检索增强策略,通过检索语义相似的RGB-D上下文样本,作为几何结构代理,弥补单目视觉的固有缺陷。
- 实验结果表明,RAD在多个数据集的欠表示类别上显著优于现有方法,相对绝对误差降低高达29.2%。
📝 摘要(中文)
单目度量深度估计(MMDE)对于物理智能系统至关重要,但复杂场景中欠表示类别的精确深度估计仍然是一个持续的挑战。为了解决这个问题,我们提出了RAD,一个检索增强框架,它通过利用检索到的邻居作为结构几何代理来近似多视图立体的优势。我们的方法首先采用一种不确定性感知的检索机制来识别输入中的低置信度区域,并检索包含语义相似内容的RGB-D上下文样本。然后,我们通过一个双流网络处理输入和检索到的上下文,并使用匹配的交叉注意力模块融合它们,该模块仅在可靠的点对应关系处传递几何信息。在NYU Depth v2、KITTI和Cityscapes上的评估表明,RAD在欠表示类别上显著优于最先进的基线,在NYU Depth v2上将相对绝对误差降低了29.2%,在KITTI上降低了13.3%,在Cityscapes上降低了7.2%,同时在标准领域内基准测试中保持了具有竞争力的性能。
🔬 方法详解
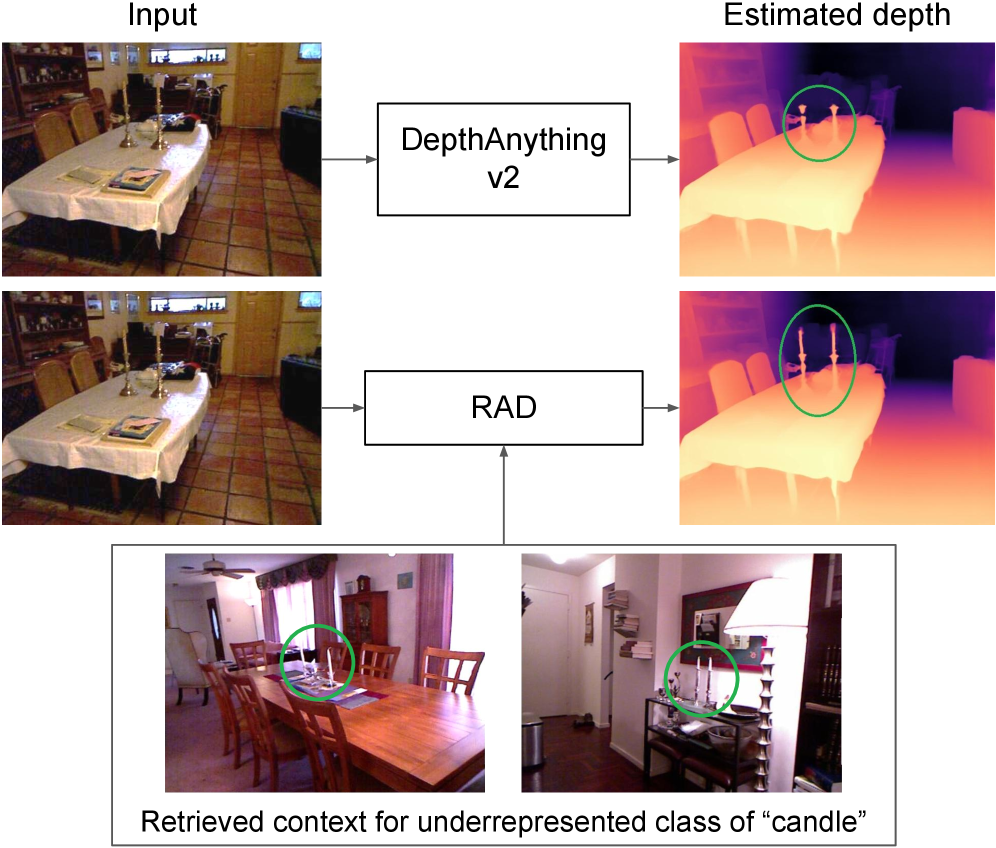
问题定义:论文旨在解决单目深度估计(MMDE)在处理场景中欠表示类别时精度不足的问题。现有方法在这些类别上表现不佳,因为单目视觉缺乏足够的几何信息,导致深度估计模糊和不准确。
核心思路:核心思路是通过检索与输入图像中低置信度区域语义相似的RGB-D图像,利用这些检索到的图像作为几何结构代理,从而增强单目深度估计的准确性。这种方法模仿了多视图立体的优势,但无需实际的多视图数据。
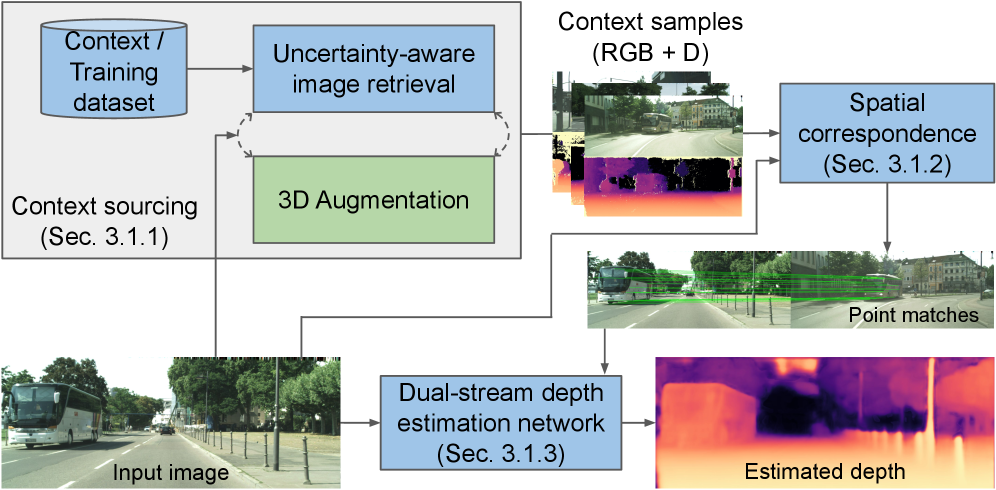
技术框架:RAD框架包含以下主要模块:1) 不确定性感知检索模块:用于识别输入图像中的低置信度区域,并检索语义相似的RGB-D上下文样本。2) 双流网络:分别处理输入图像和检索到的上下文图像。3) 匹配的交叉注意力模块:用于融合来自两个流的信息,仅在可靠的点对应关系处传递几何信息。
关键创新:关键创新在于将检索增强策略应用于单目深度估计,并设计了不确定性感知的检索机制和匹配的交叉注意力模块。这种方法能够有效地利用外部知识来弥补单目视觉的不足,从而提高欠表示类别的深度估计精度。与现有方法相比,RAD不是直接依赖于单张图像进行深度估计,而是引入了外部的几何信息作为补充。
关键设计:不确定性感知检索模块使用深度估计的不确定性作为检索的关键指标,优先检索那些模型预测不确定的区域。匹配的交叉注意力模块通过计算输入图像和检索图像之间的注意力权重,选择性地融合信息,避免引入噪声。损失函数方面,论文可能采用了深度预测常用的L1损失或L2损失,具体细节未知。
🖼️ 关键图片

📊 实验亮点
RAD在NYU Depth v2、KITTI和Cityscapes数据集上进行了评估,结果表明其在欠表示类别上显著优于最先进的基线方法。具体而言,在NYU Depth v2上,RAD将相对绝对误差降低了29.2%,在KITTI上降低了13.3%,在Cityscapes上降低了7.2%。同时,RAD在标准领域内基准测试中保持了具有竞争力的性能,表明其具有良好的泛化能力。
🎯 应用场景
该研究成果可广泛应用于机器人导航、自动驾驶、增强现实等领域。通过提高对欠表示类别的深度感知能力,可以增强机器人在复杂环境中的适应性和鲁棒性,例如在光照不足或遮挡严重的情况下,更好地识别和理解周围环境,从而做出更安全、更有效的决策。未来,该技术有望进一步推动智能系统的发展。
📄 摘要(原文)
Monocular Metric Depth Estimation (MMDE) is essential for physically intelligent systems, yet accurate depth estimation for underrepresented classes in complex scenes remains a persistent challenge. To address this, we propose RAD, a retrieval-augmented framework that approximates the benefits of multi-view stereo by utilizing retrieved neighbors as structural geometric proxies. Our method first employs an uncertainty-aware retrieval mechanism to identify low-confidence regions in the input and retrieve RGB-D context samples containing semantically similar content. We then process both the input and retrieved context via a dual-stream network and fuse them using a matched cross-attention module, which transfers geometric information only at reliable point correspondences. Evaluations on NYU Depth v2, KITTI, and Cityscapes demonstrate that RAD significantly outperforms state-of-the-art baselines on underrepresented classes, reducing relative absolute error by 29.2% on NYU Depth v2, 13.3% on KITTI, and 7.2% on Cityscapes, while maintaining competitive performance on standard in-domain benchmarks.