Vision-as-Inverse-Graphics Agent via Interleaved Multimodal Reasoning
作者: Shaofeng Yin, Jiaxin Ge, Zora Zhiruo Wang, Chenyang Wang, Xiuyu Li, Michael J. Black, Trevor Darrell, Angjoo Kanazawa, Haiwen Feng
分类: cs.CV, cs.AI, cs.GR
发布日期: 2026-04-07
💡 一句话要点
提出VIGA:通过交错多模态推理实现视觉逆向图形Agent
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉逆向图形 多模态推理 视觉-语言模型 代码生成 3D重建
📋 核心要点
- 现有视觉-语言模型在视觉逆向图形任务中,缺乏细粒度的空间定位能力,难以一次性将图像转换为可编辑程序。
- VIGA通过交错多模态推理,利用符号逻辑和视觉感知相互验证,迭代地合成、渲染和检查代码,从而实现精确的图像重建。
- VIGA在BlenderGym、SlideBench和BlenderBench等基准测试中,显著优于一次性基线,验证了其有效性。
📝 摘要(中文)
本文提出VIGA(Vision-as-Inverse-Graphics Agent),一个交错多模态推理框架,旨在解决视觉-语言模型(VLMs)在一次性设置中缺乏细粒度空间基础的难题,从而实现将图像重建为可编辑程序这一目标。VIGA通过紧密耦合的代码-渲染-检查循环运行:合成符号程序,将其投影到视觉状态,并检查差异以指导迭代编辑。凭借高级语义技能和不断发展的多模态记忆,VIGA能够在长时间内维持基于证据的修改。这个免训练、任务无关的框架无缝支持2D文档生成、3D重建、多步骤3D编辑和4D物理交互。此外,我们提出了一个具有挑战性的视觉到代码基准BlenderBench。实验结果表明,与BlenderGym(35.32%)、SlideBench(117.17%)以及我们提出的BlenderBench(124.70%)中的一次性基线相比,VIGA显著提高了准确性。
🔬 方法详解
问题定义:视觉逆向图形旨在将图像转换为可编辑的程序代码,这对于视觉-语言模型来说是一个挑战,因为它们通常缺乏细粒度的空间定位能力,尤其是在单次推理的情况下。现有的方法难以准确地将视觉信息映射到可执行的代码指令,导致重建结果不精确或无法编辑。
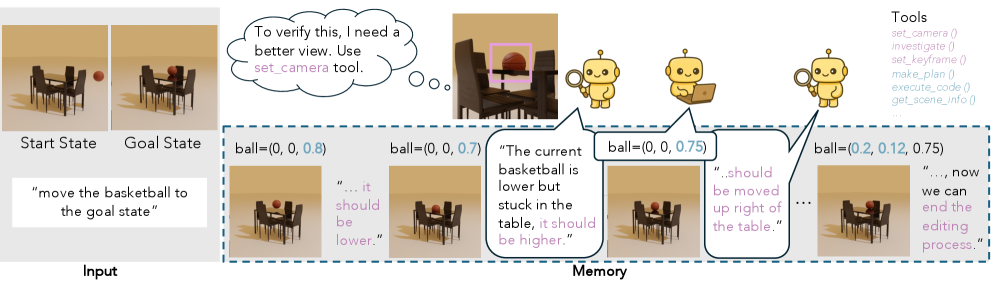
核心思路:VIGA的核心思路是采用交错多模态推理,通过代码-渲染-检查的循环迭代过程,逐步完善生成的代码。它利用符号逻辑进行程序合成,然后将程序渲染成视觉状态,并通过视觉感知模块检查渲染结果与目标图像之间的差异。这种循环反馈机制允许模型在每次迭代中修正错误,从而提高代码生成的准确性。
技术框架:VIGA的整体框架包含以下几个主要模块:1) 代码生成器:负责生成初始的符号程序代码。2) 渲染器:将生成的代码渲染成视觉图像。3) 检查器:比较渲染图像与目标图像之间的差异,并生成反馈信号。4) 编辑器:根据检查器的反馈信号,对代码进行修改和优化。这些模块通过一个紧密耦合的循环迭代过程协同工作,直到生成的代码能够准确地重建目标图像。此外,VIGA还配备了高级语义技能和不断发展的多模态记忆,以支持长时间的推理和修改。
关键创新:VIGA的关键创新在于其交错多模态推理框架,它将符号逻辑和视觉感知紧密结合,通过循环迭代的方式逐步完善代码生成。与传统的单次推理方法相比,VIGA能够更好地利用视觉信息来指导代码生成,从而提高重建的准确性和可编辑性。此外,VIGA的免训练、任务无关特性使其能够灵活地应用于各种视觉逆向图形任务。
关键设计:VIGA的关键设计包括:1) 使用预训练的视觉-语言模型作为代码生成器的基础,以提高代码生成的质量。2) 设计合适的渲染器,将代码转换为视觉图像。3) 开发有效的检查器,能够准确地检测渲染图像与目标图像之间的差异。4) 实现高效的编辑器,能够根据检查器的反馈信号,对代码进行修改和优化。具体的参数设置、损失函数和网络结构等技术细节在论文中进行了详细描述(未知)。
🖼️ 关键图片

📊 实验亮点
VIGA在BlenderGym、SlideBench和BlenderBench等基准测试中取得了显著的性能提升。具体来说,与一次性基线相比,VIGA在BlenderGym上提高了35.32%,在SlideBench上提高了117.17%,在BlenderBench上提高了124.70%。这些结果表明,VIGA的交错多模态推理框架能够有效地提高视觉逆向图形任务的准确性。
🎯 应用场景
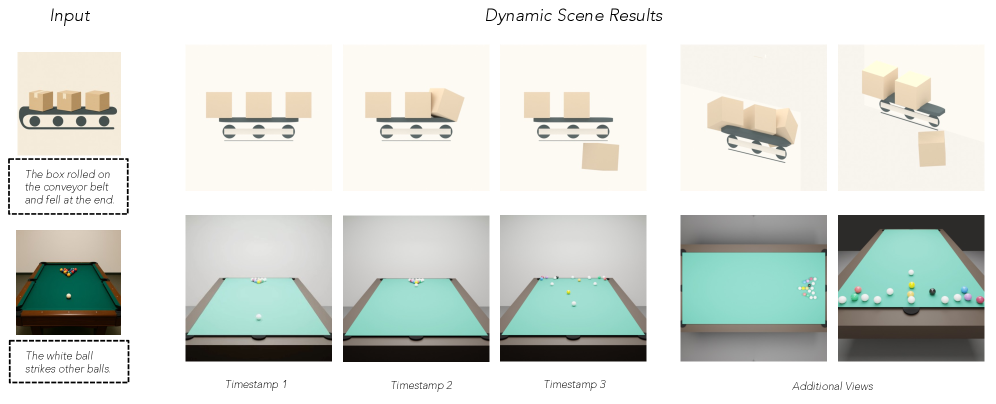
VIGA具有广泛的应用前景,包括2D文档生成、3D重建、多步骤3D编辑和4D物理交互等领域。它可以用于自动化设计、虚拟现实、机器人控制等应用场景,例如,可以根据用户提供的草图自动生成3D模型,或者根据用户的指令编辑现有的3D场景。VIGA的出现为视觉逆向图形领域带来了新的可能性,有望推动相关技术的发展。
📄 摘要(原文)
Vision-as-inverse-graphics, the concept of reconstructing images into editable programs, remains challenging for Vision-Language Models (VLMs), which inherently lack fine-grained spatial grounding in one-shot settings. To address this, we introduce VIGA (Vision-as-Inverse-Graphics Agent), an interleaved multimodal reasoning framework where symbolic logic and visual perception actively cross-verify each other. VIGA operates through a tightly coupled code-render-inspect loop: synthesizing symbolic programs, projecting them into visual states, and inspecting discrepancies to guide iterative edits. Equipped with high-level semantic skills and an evolving multimodal memory, VIGA sustains evidence-based modifications over long horizons. This training-free, task-agnostic framework seamlessly supports 2D document generation, 3D reconstruction, multi-step 3D editing, and 4D physical interaction. Finally, we introduce BlenderBench, a challenging visual-to-code benchmark. Empirically, VIGA substantially improves accuracy compared with one-shot baselines in BlenderGym (35.32%), SlideBench (117.17%) and our proposed BlenderBench (124.70%).