ToG-Bench: Task-Oriented Spatio-Temporal Grounding in Egocentric Videos
作者: Qi'ao Xu, Tianwen Qian, Yuqian Fu, Kailing Li, Yang Jiao, Jiacheng Zhang, Xiaoling Wang, Liang He
分类: cs.CV, cs.AI
发布日期: 2026-04-07
💡 一句话要点
提出ToG-Bench:一个面向任务的自中心视频时空定位基准
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时空视频定位 具身智能 面向任务 显隐式推理 多对象定位
📋 核心要点
- 现有STVG研究忽略了具身智能体完成任务所需的面向任务的推理,限制了其在实际场景中的应用。
- ToG-Bench通过构建面向任务的指令、支持显隐式推理和一对多对象定位,弥补了现有基准的不足。
- 实验表明,现有MLLM在ToG-Bench上表现不佳,尤其是在隐式推理和多对象定位方面,存在显著差距。
📝 摘要(中文)
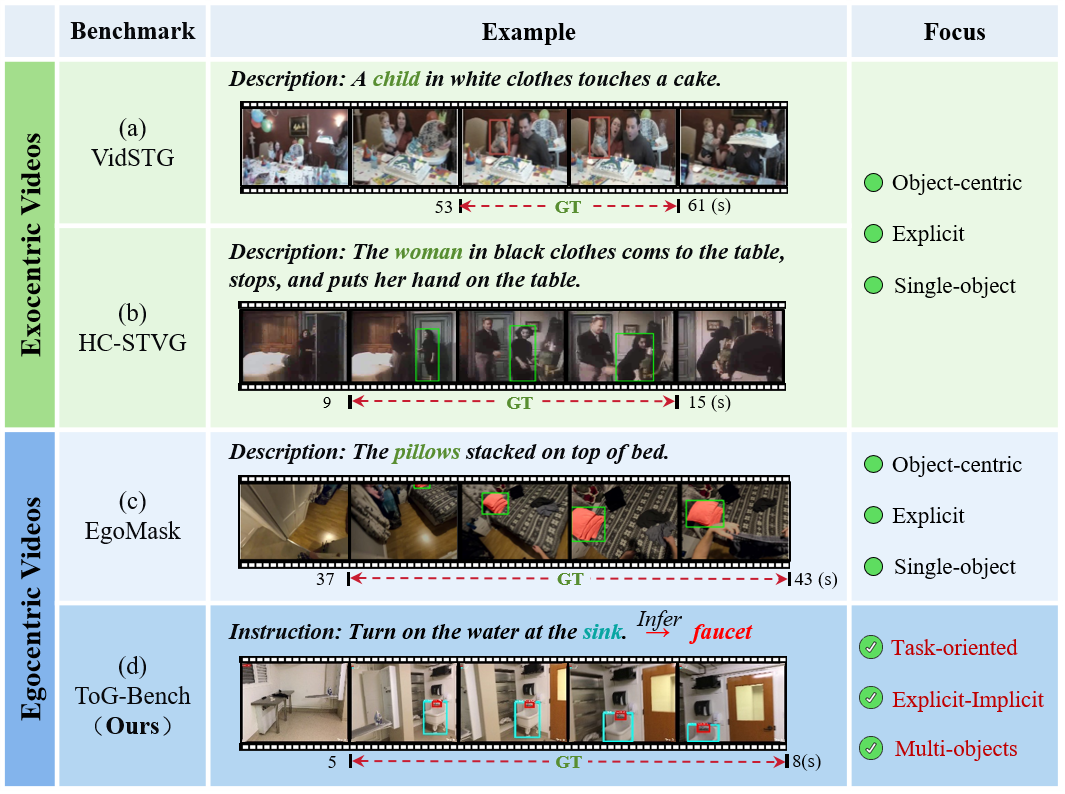
本文提出了ToG-Bench,这是一个面向任务的自中心视频时空定位基准。现有的时空视频定位研究主要集中在以物体为中心和描述性的指令上,忽略了具身智能体完成目标导向交互所需的面向任务的推理。ToG-Bench具有三个关键特征:(1)面向任务的定位,需要根据预期的任务识别和定位对象,而不是直接的描述;(2)显式-隐式双重定位,目标对象可以被显式提及或通过上下文推理隐式推断;(3)一对多定位,单个指令可能对应于任务执行中涉及的多个对象。ToG-Bench基于ScanNet的视频构建,包含100个带注释的片段,具有2,704个面向任务的定位指令,通过结合基础模型注释和人工改进的半自动流程构建。此外,本文还引入了一组针对多对象和显式-隐式对象定位的任务级评估指标,并系统地评估了七个最先进的多模态大语言模型。大量实验揭示了面向任务的时空视频定位的内在挑战,以及显式-隐式和多对象定位方面的巨大性能差距,突出了在具身场景中桥接感知和交互的难度。
🔬 方法详解
问题定义:论文旨在解决现有STVG研究缺乏面向任务的推理能力的问题。现有方法主要关注对象中心和描述性指令,无法满足具身智能体在复杂任务中定位目标对象的需求,尤其是在需要隐式推理和涉及多个对象时。
核心思路:论文的核心思路是构建一个更贴近实际任务场景的STVG基准,该基准不仅包含面向任务的指令,还支持显式和隐式对象定位,以及一对多对象定位。通过这样的基准,可以更好地评估和提升模型在具身智能任务中的感知和交互能力。
技术框架:ToG-Bench的构建流程包括:1) 从ScanNet视频中选择片段;2) 使用基础模型进行初步注释;3) 通过人工改进和验证,生成最终的面向任务的定位指令。评估指标包括针对多对象和显式-隐式对象定位的任务级指标。论文还使用七个最先进的MLLM在ToG-Bench上进行了基准测试。
关键创新:ToG-Bench的关键创新在于其面向任务的特性,以及对显式-隐式双重定位和一对多定位的支持。这使得ToG-Bench能够更真实地反映具身智能体在实际任务中面临的挑战,并促进相关算法的发展。
关键设计:ToG-Bench的数据集包含100个视频片段,共2704条指令。指令的构建采用了半自动化的流程,以保证数据质量和标注效率。评估指标的设计考虑了多对象和显式-隐式定位的特点,例如,针对多对象定位,需要同时正确识别和定位所有目标对象才能算作正确。
🖼️ 关键图片


📊 实验亮点
实验结果表明,现有最先进的MLLM在ToG-Bench上的表现远低于人类水平,尤其是在隐式推理和多对象定位方面。例如,在隐式对象定位任务中,模型的平均精度显著低于显式对象定位。此外,模型在处理涉及多个对象的指令时,性能也明显下降。这些结果突出了ToG-Bench的挑战性,并为未来的研究方向提供了重要的参考。
🎯 应用场景
ToG-Bench的潜在应用领域包括机器人导航、人机协作、智能家居等。通过提升模型在面向任务的时空定位能力,可以使具身智能体更好地理解人类指令,并在复杂环境中完成各种任务,从而提高工作效率和生活质量。该研究的未来影响在于推动具身智能的进一步发展,使其更具实用性和智能化。
📄 摘要(原文)
A core capability towards general embodied intelligence lies in localizing task-relevant objects from an egocentric perspective, formulated as Spatio-Temporal Video Grounding (STVG). Despite recent progress, existing STVG studies remain largely confined to object-centric and descriptive instructions, neglecting the task-oriented reasoning that is crucial for embodied agents to accomplish goal-directed interactions. To bridge this gap, we introduce \textbf{ToG-Bench}, the first task-oriented spatio-temporal video grounding benchmark for egocentric videos. ToG-Bench is characterized by three key features: (1) \textbf{Task-oriented Grounding}, which requires identifying and localizing objects based on intended tasks rather than straightforward descriptions; (2) \textbf{Explicit-Implicit Dual Grounding}, where target objects can be either explicitly mentioned or implicitly inferred by contextual reasoning; (3) \textbf{One-to-Many Grounding}, where a single instruction may correspond to multiple objects involved in task execution. Built upon videos sourced from ScanNet, ToG-Bench comprises 100 annotated clips with 2,704 task-oriented grounding instructions, constructed via a semi-automated pipeline that combines foundation model annotation and human refinement. In addition, we introduce a set of task-level evaluation metrics tailored for multi-object and explicit-implicit object grounding, and systematically benchmark seven state-of-the-art MLLMs. Extensive experiments reveal the intrinsic challenges of task-oriented STVG and substantial performance gaps across explicit-implicit and multi-object grounding, highlighting the difficulty of bridging perception and interaction in embodied scenarios. Data and code will be released at: \href{this https URL}{this https URL}..