Low-Bitrate Video Compression through Semantic-Conditioned Diffusion
作者: Lingdong Wang, Guan-Ming Su, Divya Kothandaraman, Tsung-Wei Huang, Mohammad Hajiesmaili, Ramesh K. Sitaraman
分类: cs.CV, cs.AI
发布日期: 2026-04-07
💡 一句话要点
提出DiSCo:一种基于语义条件扩散的低码率视频压缩框架,显著提升感知质量。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频压缩 低码率 语义理解 扩散模型 条件生成
📋 核心要点
- 传统视频编解码器在极低码率下表现不佳,主要原因是其优化目标与人类感知不一致,导致伪影严重。
- DiSCo框架通过语义分解和条件扩散模型,仅传输关键语义信息,利用生成先验重建高质量视频。
- 实验结果表明,DiSCo在低码率下,感知指标显著优于传统和语义编解码器,提升幅度达到2-10倍。
📝 摘要(中文)
传统的视频编解码器在极低码率下,为了追求像素级保真度而失效,产生严重的伪影。这种失败源于像素精度与人类感知之间的根本不匹配。我们提出了一种名为DiSCo的语义视频压缩框架,该框架仅传输最有意义的信息,并依赖生成先验来合成细节。源视频被分解为三个紧凑的模态:文本描述、时空退化的视频以及可选的草图或姿势,分别捕获语义、外观和运动线索。然后,条件视频扩散模型从这些紧凑的表示中重建高质量、时间一致的视频。提出了时间前向填充、token交错和模态特定编解码器来改善多模态生成和模态紧凑性。实验表明,在低码率下,我们的方法在感知指标上优于基线语义和传统编解码器2-10倍。
🔬 方法详解
问题定义:在极低码率下,传统视频编解码器为了追求像素级的精确匹配,会产生严重的伪影,导致感知质量下降。现有的方法难以在极低码率下保持视频的语义信息和时间一致性。
核心思路:DiSCo的核心思路是将视频分解为语义、外观和运动三个模态,并分别进行压缩。然后,利用条件视频扩散模型,根据这些压缩后的模态重建高质量的视频。这种方法的核心在于将像素级的重建问题转化为语义理解和生成问题,从而更好地适应人类的感知。
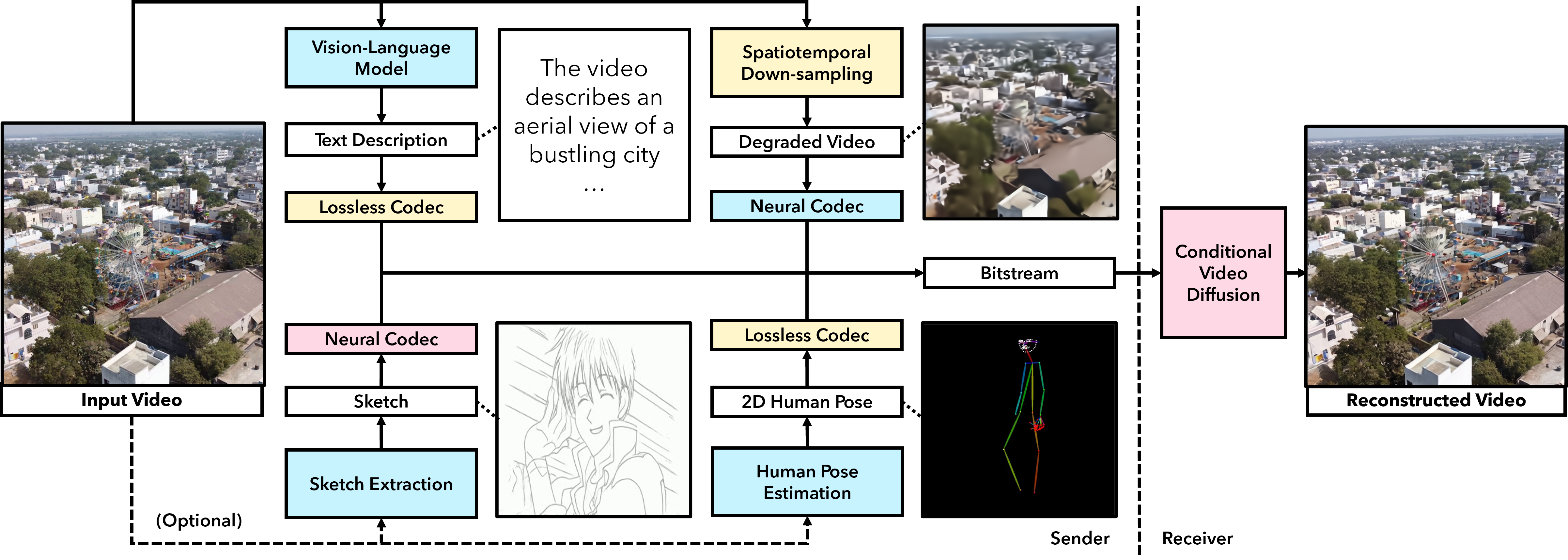
技术框架:DiSCo框架主要包含以下几个模块:1) 视频分解模块:将原始视频分解为文本描述(语义)、时空退化的视频(外观)以及可选的草图或姿势(运动)。2) 模态特定编解码器:对每个模态进行压缩,以实现低码率传输。3) 条件视频扩散模型:根据压缩后的模态重建高质量、时间一致的视频。该模型以文本描述、退化视频和草图/姿势作为条件,生成最终的视频。
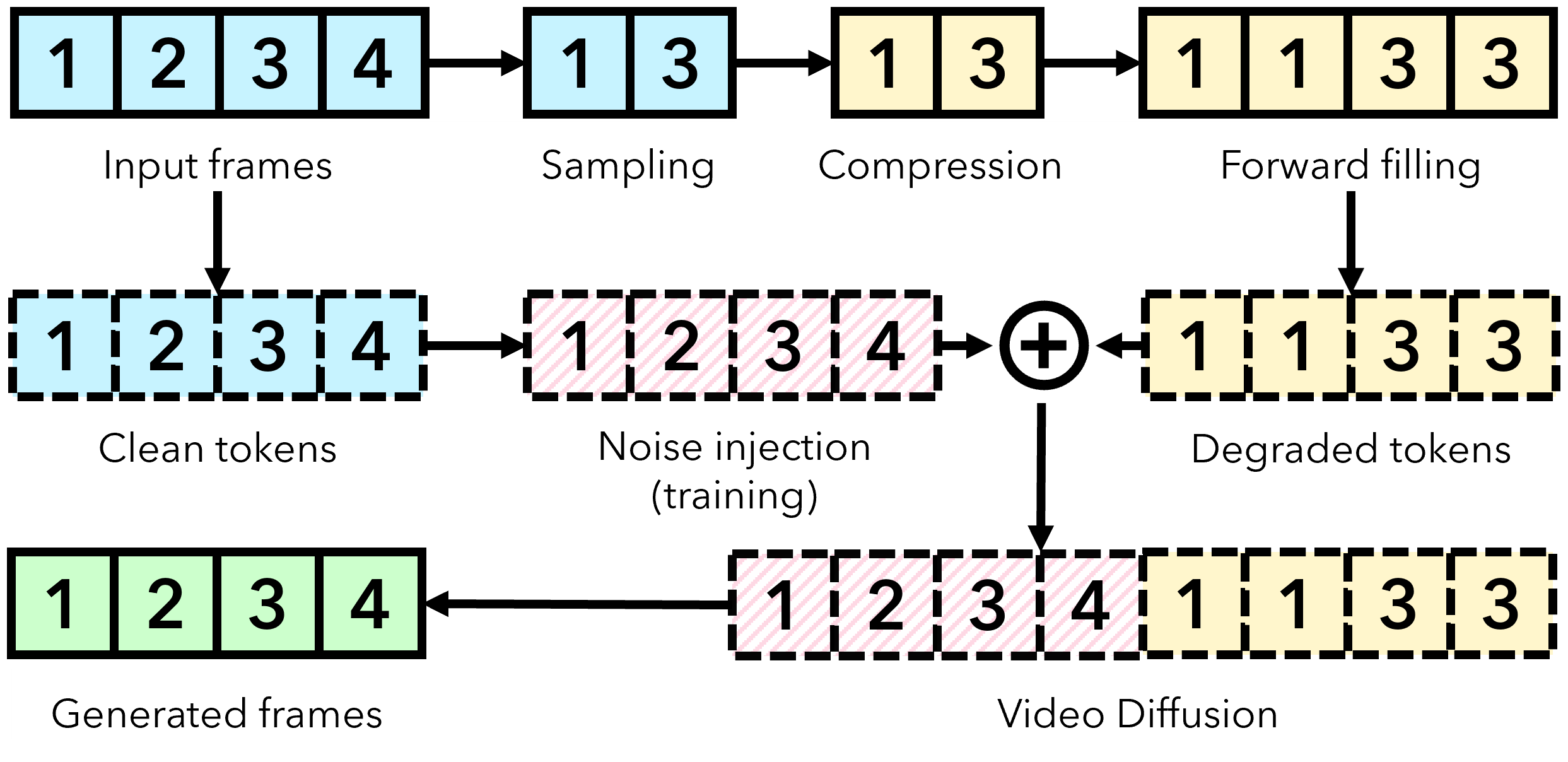
关键创新:DiSCo的关键创新在于其语义分解和条件扩散的结合。通过将视频分解为不同的模态,可以更好地捕捉视频的语义信息,并针对每个模态进行优化压缩。同时,利用条件视频扩散模型,可以有效地利用生成先验,从而在低码率下重建高质量的视频。此外,时间前向填充和token交错等技术进一步提升了多模态生成的效果。
关键设计:在视频分解模块中,可以使用现成的图像/视频描述模型提取文本描述。时空退化视频可以通过降低分辨率和帧率来实现。草图或姿势可以通过姿态估计模型提取。模态特定编解码器可以使用现有的图像/视频编解码器,也可以针对特定模态进行定制设计。条件视频扩散模型可以使用U-Net架构,并引入注意力机制来融合不同模态的信息。损失函数可以包括像素级的重建损失和感知损失,以提高重建视频的质量。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在低码率下,DiSCo框架在感知指标(如LPIPS、FID)上显著优于传统的视频编解码器(如H.264、H.265)和基于GAN的语义视频编解码器。具体来说,DiSCo在某些场景下可以实现2-10倍的性能提升,表明其在低码率视频压缩方面具有显著的优势。
🎯 应用场景
DiSCo框架在低带宽视频传输、视频监控、远程会议等领域具有广泛的应用前景。例如,在网络条件较差的情况下,可以使用DiSCo框架传输高质量的视频,从而提升用户体验。此外,该框架还可以用于视频编辑、视频修复等任务,通过语义理解和生成,实现更智能的视频处理。
📄 摘要(原文)
Traditional video codecs optimized for pixel fidelity collapse at ultra-low bitrates and produce severe artifacts. This failure arises from a fundamental misalignment between pixel accuracy and human perception. We propose a semantic video compression framework named DiSCo that transmits only the most meaningful information while relying on generative priors for detail synthesis. The source video is decomposed into three compact modalities: a textual description, a spatiotemporally degraded video, and optional sketches or poses that respectively capture semantic, appearance, and motion cues. A conditional video diffusion model then reconstructs high-quality, temporally coherent videos from these compact representations. Temporal forward filling, token interleaving, and modality-specific codecs are proposed to improve multimodal generation and modality compactness. Experiments show that our method outperforms baseline semantic and traditional codecs by 2-10X on perceptual metrics at low bitrates.