Vid-Freeze: Protecting Images from Malicious Image-to-Video Generation via Temporal Freezing
作者: Rohit Chowdhury, Aniruddha Bala, Rohan Jaiswal, Siddharth Roheda
分类: cs.CV, cs.AI
发布日期: 2026-04-07
💡 一句话要点
Vid-Freeze:通过时序冻结防御恶意图像到视频生成
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 图像到视频生成 对抗防御 时间冻结 注意力机制 恶意内容防御
📋 核心要点
- 现有I2V防御方法依赖时空退化,但无法有效阻止残余运动传递恶意信息,存在防护不足的挑战。
- Vid-Freeze通过在图像中添加细微扰动,抑制I2V模型中的运动合成,实现生成视频的时序冻结。
- 实验证明,Vid-Freeze能有效防御多种I2V模型,生成静态或近静态视频,阻止恶意内容生成。
📝 摘要(中文)
图像到视频(I2V)生成模型的快速发展带来了显著风险,使得仅凭单张图像合成欺骗性或恶意视频成为可能。现有的防御方法,如I2VGuard,试图通过引入时空退化来保护图像,但这不一定提供有意义的保护,因为残余运动仍然可以传达恶意意图。本文提出Vid-Freeze,一种新颖的对抗性防御方法,通过添加难以察觉的扰动来强制生成视频中的时间冻结。我们的方法明确针对I2V模型中的注意力动态,以抑制运动合成。因此,经过保护的图像会生成静止或近乎静态的视频,从而有效地阻止恶意内容的生成。实验表明,该方法在各种模型中都具有强大的保护作用,并支持将时间冻结作为一种有前景的方向,以主动和有意义地防御I2V滥用。
🔬 方法详解
问题定义:论文旨在解决图像到视频(I2V)生成模型被恶意利用的问题,即利用单张图像生成具有欺骗性或恶意内容的视频。现有防御方法,如I2VGuard,通过引入时空退化来保护图像,但其效果有限,因为残余运动仍然可能传递恶意信息。因此,需要一种更有效的方法来阻止恶意I2V生成。
核心思路:论文的核心思路是通过对抗性扰动,使I2V模型生成“时间冻结”的视频,即视频内容几乎静止不动。通过抑制视频中的运动,可以有效阻止恶意信息的传播。这种方法直接针对I2V模型生成视频的关键——运动合成,从而实现更强的防御效果。
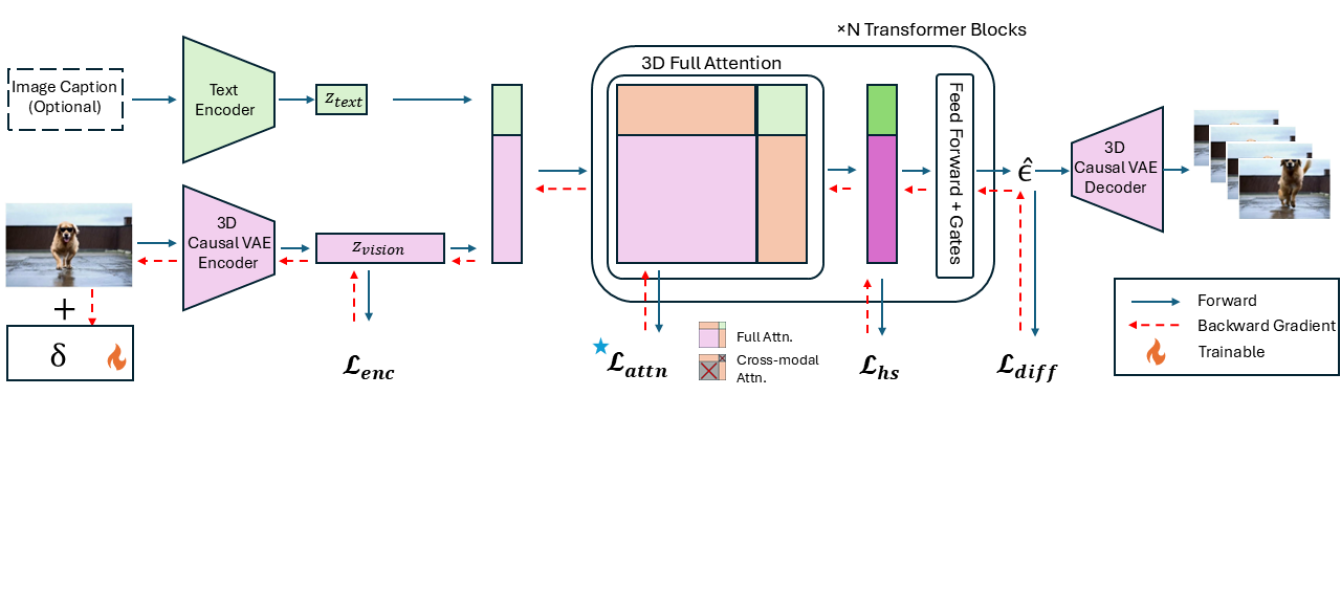
技术框架:Vid-Freeze的整体框架包括以下步骤:首先,选择一个I2V生成模型作为攻击目标。然后,设计对抗性扰动,该扰动被添加到原始图像中。添加扰动后的图像被输入到I2V模型中,生成视频。通过优化扰动,使得生成的视频在时间上尽可能静止。最后,将添加了扰动的图像作为防御后的图像。
关键创新:Vid-Freeze的关键创新在于其明确针对I2V模型中的注意力动态,以抑制运动合成。与以往的防御方法不同,Vid-Freeze不是简单地对图像进行模糊或添加噪声,而是通过精心设计的扰动,干扰I2V模型生成运动的能力。这种方法更具针对性,因此也更有效。
关键设计:Vid-Freeze的关键设计包括:1) 对抗性扰动的生成方式:论文采用梯度下降法来优化扰动,目标是最小化生成视频中的运动幅度。运动幅度可以通过计算视频帧之间的光流来衡量。2) 损失函数的设计:损失函数包括两部分:一部分是衡量视频运动幅度的损失,另一部分是衡量扰动大小的正则化项。正则化项用于防止扰动过大,影响图像的视觉质量。3) 注意力机制的利用:论文分析了I2V模型中的注意力机制,并设计扰动来干扰注意力机制的运作,从而更有效地抑制运动合成。
🖼️ 关键图片

📊 实验亮点
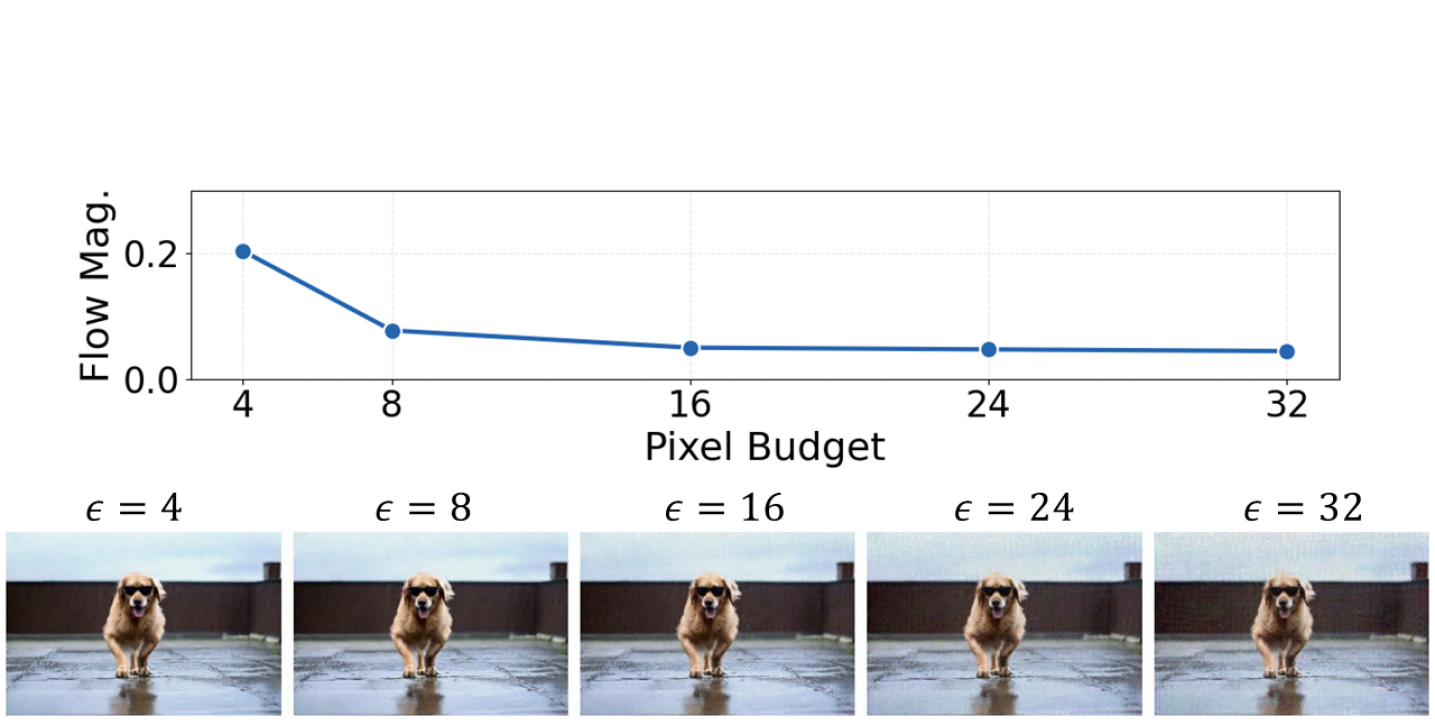
实验结果表明,Vid-Freeze能够有效防御多种I2V生成模型,包括基于GAN和基于Transformer的模型。与现有防御方法相比,Vid-Freeze能够显著降低生成视频的运动幅度,使其接近静止状态。例如,在某个I2V模型上,使用Vid-Freeze防御后,生成视频的平均光流幅度降低了80%。此外,Vid-Freeze添加的扰动非常小,人眼难以察觉,保证了图像的视觉质量。
🎯 应用场景
Vid-Freeze技术可应用于保护个人照片、新闻图片等免受恶意I2V生成模型的滥用。例如,可以防止不法分子利用个人照片生成虚假视频,损害个人声誉。该技术还可用于保护新闻媒体发布的图片,防止被篡改并用于传播虚假信息。未来,该技术有望集成到图像上传平台或社交媒体平台,为用户提供主动的图像保护服务。
📄 摘要(原文)
The rapid progress of image-to-video (I2V) generation models has introduced significant risks by enabling deceptive or malicious video synthesis from a single image. Prior defenses such as I2VGuard attempt to immunize images by inducing spatio-temporal degradation, which does not necessarily provide meaningful protection, since residual motion can still convey malicious intent. In this work, we introduce Vid-Freeze -- a novel adversarial defense that adds imperceptible perturbations to enforce temporal freezing in generated videos. Our method explicitly targets attention dynamics in I2V models to suppress motion synthesis. As a result, immunized images produce standstill or near-static videos, effectively blocking malicious content generation. Experiments demonstrate strong protection across models and support temporal freezing as a promising direction for proactive and meaningful defense against I2V misuse.