Chain-of-Frames: Advancing Video Understanding in Multimodal LLMs via Frame-Aware Reasoning
作者: Sara Ghazanfari, Francesco Croce, Nicolas Flammarion, Prashanth Krishnamurthy, Farshad Khorrami, Siddharth Garg
分类: cs.CV
发布日期: 2026-04-07
💡 一句话要点
提出Chain-of-Frames框架,提升多模态LLM在视频理解中的帧感知推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频理解 多模态LLM 帧感知推理 Chain-of-Frames 视频问答
📋 核心要点
- 现有视频理解方法在时间建模上存在不足,要么流程复杂,要么时间定位不准确。
- 论文提出Chain-of-Frames框架,通过单阶段推理并显式引用关键帧,提升时间一致性。
- 实验表明,该方法在多个视频理解基准测试中表现出色,且合成数据能有效提升模型性能。
📝 摘要(中文)
本文提出了一种新的视频语言模型框架,旨在通过帧感知的推理来提升多模态大型语言模型(LLM)在视频理解方面的性能。现有方法通常采用复杂的多步骤流程,或者牺牲时间上的精确性来生成简单的单阶段推理轨迹。本文提出的方法是首个单阶段推理的视频LLM,它显式地引用相关帧,从而减少推理过程中的时间不一致性。为此,作者构建了一个名为COF-DATA的大型数据集,其中包含来自自然和合成视频的多样化问题、答案以及相应的帧定位推理轨迹。通过在该数据集上微调视频LLM,模型能够生成准确识别关键帧的推理轨迹,从而持续提高多个视频理解基准测试的性能。令人惊讶的是,即使合成数据与真实世界的基准测试存在分布差异,也能显著提高模型的准确性。
🔬 方法详解
问题定义:现有视频理解方法,特别是基于多模态LLM的方法,在处理视频时面临时间建模的挑战。一些方法采用复杂的多步骤流程,需要额外的模块进行帧选择和字幕生成,导致效率低下。另一些方法则采用单阶段推理,但由于缺乏对关键帧的显式引用,导致时间定位不准确,影响推理的质量。
核心思路:本文的核心思路是让LLM在推理过程中显式地引用视频中的关键帧,从而实现帧感知的推理。通过生成包含帧引用的推理链(Chain-of-Frames),模型可以更好地理解视频内容,并减少时间上的不一致性。这种方法旨在简化推理流程,同时提高时间建模的准确性。
技术框架:该方法采用单阶段推理框架,避免了复杂的多步骤流程。首先,构建了一个名为COF-DATA的大型数据集,其中包含视频、问题、答案以及对应的帧定位推理轨迹。然后,使用该数据集对视频LLM进行微调,使其能够生成包含帧引用的推理链。在推理阶段,模型接收视频和问题作为输入,直接生成包含帧引用的答案。
关键创新:该方法最重要的创新点在于提出了Chain-of-Frames的概念,并将其融入到单阶段推理框架中。与现有方法相比,该方法无需额外的帧选择或字幕生成模块,而是通过显式地引用关键帧来实现帧感知的推理。此外,该方法还发现合成数据可以有效提升模型在真实世界数据集上的性能,这为数据增强提供了一种新的思路。
关键设计:COF-DATA数据集是该方法的关键组成部分,它包含了来自自然和合成视频的多样化问题、答案以及对应的帧定位推理轨迹。数据集的构建需要仔细设计问题和答案,并确保推理轨迹能够准确地定位到关键帧。此外,模型微调过程中的损失函数和学习率等参数也需要进行仔细调整,以获得最佳的性能。
🖼️ 关键图片

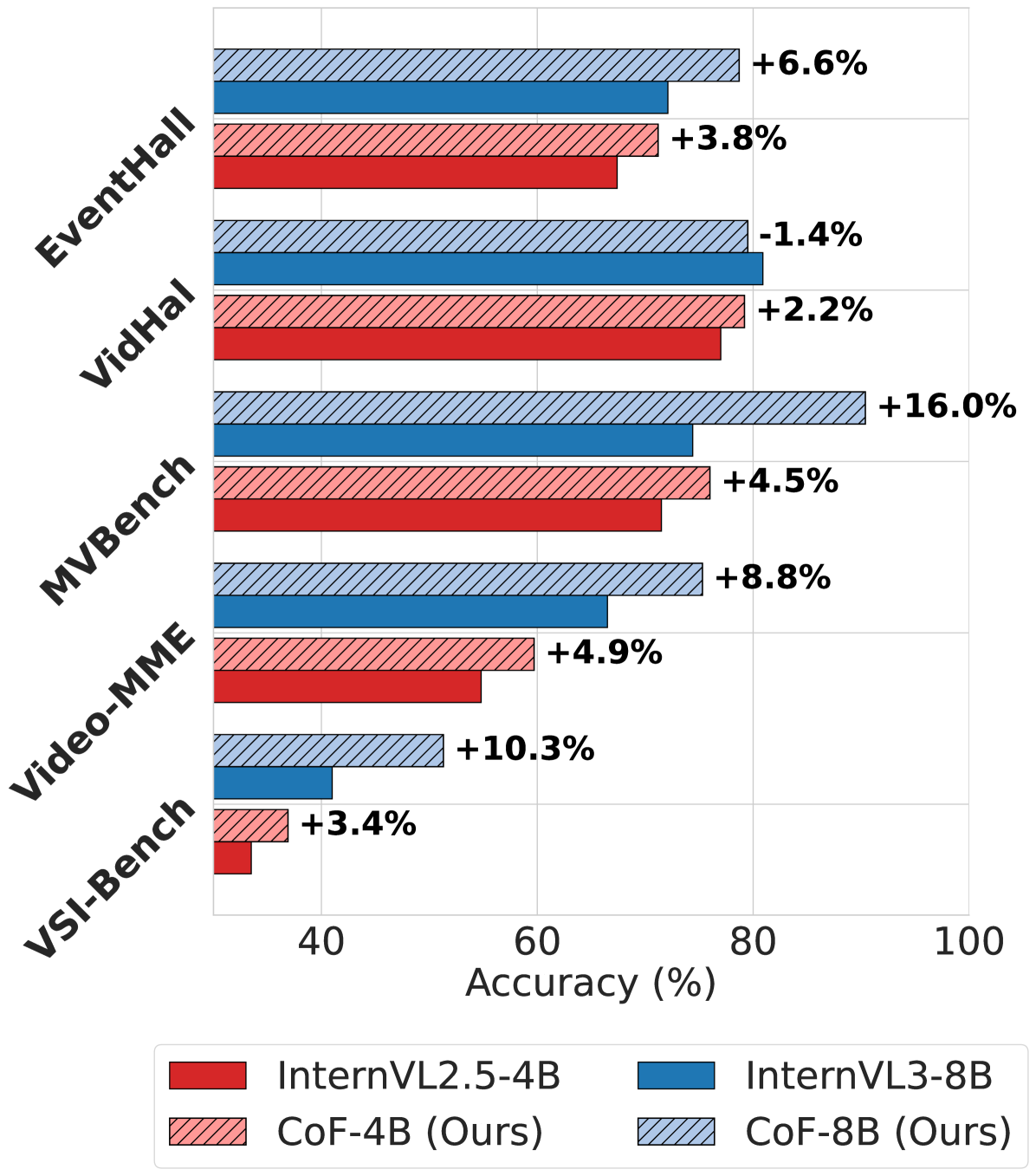

📊 实验亮点
实验结果表明,通过在COF-DATA数据集上进行微调,模型在多个视频理解基准测试中取得了显著的性能提升。更令人惊讶的是,即使使用与真实世界基准测试存在分布差异的合成数据进行训练,也能显著提高模型的准确性。这表明合成数据在视频理解任务中具有巨大的潜力。
🎯 应用场景
该研究成果可应用于智能视频监控、视频内容分析、视频问答系统、视频编辑等领域。通过提升视频理解的准确性和效率,可以实现更智能的视频分析和处理,例如自动识别异常事件、生成视频摘要、辅助视频编辑等,具有广泛的应用前景。
📄 摘要(原文)
Recent work has shown that eliciting Large Language Models (LLMs) to generate reasoning traces in natural language before answering the user's request can significantly improve their performance across tasks. This approach has been extended to multimodal LLMs, where the models can produce chains-of-thoughts (CoT) about the content of input images and videos. For video inputs, prior works use complex multi-step pipelines that extract and include relevant frames from videos in the CoT, or produce simpler single-stage reasoning traces at the expense of poor temporal grounding. Here, we propose the first video LLMs with single-stage reasoning that includes explicit references to relevant frames, thereby reducing temporal inconsistencies in the reasoning process. Our approach is simple, unified, and self-contained, employing a single-stage inference to handle complex video understanding tasks without relying on auxiliary modules for frame selection or caption generation. For this, we first create COF-DATA, a large dataset of diverse questions, answers, and corresponding frame-grounded reasoning traces from both natural and synthetic videos, spanning various topics and tasks. Our models, obtained fine-tuning video LLMs on this chain-of-frames (CoF) data, generate reasoning traces that accurately identify key frames to answer given questions. In turn, this consistently improves performance across multiple video understanding benchmarks. Surprisingly, we find that synthetic data alone, despite being out-of-distribution with respect to these real-world benchmarks, provides a significant boost in model accuracy. Code is available atthis https URL.