EGM: Efficient Visual Grounding Language Models
作者: Guanqi Zhan, Changye Li, Zhijian Liu, Yao Lu, Yi Wu, Song Han, Ligeng Zhu
分类: cs.CV
发布日期: 2026-04-06
💡 一句话要点
提出EGM:通过生成更多中等质量tokens,提升小型视觉语言模型在视觉定位任务中的效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉定位 视觉语言模型 模型效率 tokens生成 非模态定位
📋 核心要点
- 现有视觉语言模型在视觉定位任务中存在模型体积大、推理速度慢的问题,限制了其在实际场景中的部署。
- EGM的核心思想是通过生成更多中等质量的tokens,来弥补小型视觉语言模型在语言理解能力上的不足,从而提升定位性能。
- 实验结果表明,EGM在RefCOCO等基准测试中,显著提升了小型模型的定位精度和推理速度,甚至超越了大型模型。
📝 摘要(中文)
视觉定位是视觉语言模型(VLM)理解真实物理世界的关键能力。目前最先进的视觉定位语言模型通常模型规模庞大,导致部署困难且推理速度慢。我们发现,小型和大型VLM的视觉编码器大小几乎相同,主要区别在于语言模型的大小。小型VLM在定位方面落后于大型VLM,原因在于语言理解能力的差异,而非视觉信息处理能力。为了弥补这一差距,我们提出了“高效视觉定位语言模型”(EGM):生成大量中等质量的tokens(来自小型模型),以匹配大型VLM少量但高质量tokens的性能。该方法易于部署,并能带来更好的端到端延迟:在RefCOCO基准测试中,我们的EGM-Qwen3-VL-8B以平均737ms(快5.9倍)的延迟达到91.4的IoU,而Qwen3-VL-235B需要4,320ms才能达到90.5的IoU。为了验证我们方法的通用性,我们进一步设置了一个新的非模态定位场景,要求模型预测物体的可见和遮挡部分。实验表明,我们的方法持续改进了小型模型的普通和非模态定位能力,使其能够匹配甚至超过大型模型,从而提高了视觉定位的效率。
🔬 方法详解
问题定义:论文旨在解决视觉语言模型在视觉定位任务中,小型模型性能不足且大型模型推理速度慢的问题。现有方法依赖于大型语言模型来提升定位精度,但计算成本高昂,难以部署。小型模型虽然速度快,但由于语言理解能力不足,定位精度较低。
核心思路:论文的核心思路是,与其追求少量高质量的tokens(大型模型),不如生成大量中等质量的tokens(小型模型)。通过增加tokens的数量,弥补单个token质量上的差距,从而在保证推理速度的同时,提升定位精度。这种方法更适合小型模型,使其能够以更低的计算成本达到与大型模型相当的性能。
技术框架:EGM的技术框架主要包括视觉编码器和语言模型两部分。视觉编码器负责提取图像特征,语言模型负责处理文本输入并进行视觉定位。EGM的关键在于对语言模型的改进,通过生成更多的tokens来提升语言理解能力。具体流程为:首先,视觉编码器提取图像特征;然后,语言模型根据文本输入和图像特征生成多个候选区域;最后,模型选择与文本描述最匹配的区域作为定位结果。
关键创新:EGM最重要的技术创新点在于,它打破了“高质量tokens=高性能”的传统观念,提出了一种“多数量、中等质量tokens”的替代方案。这种方案更适合小型模型,使其能够在计算资源有限的情况下,达到与大型模型相当的性能。与现有方法相比,EGM的本质区别在于,它更加注重效率,通过优化tokens的生成方式来提升整体性能,而不是单纯地增加模型规模。
关键设计:论文中没有明确给出关键参数设置、损失函数或网络结构的具体细节。但是,可以推测,EGM可能涉及到对语言模型的训练策略进行调整,例如,使用更宽松的约束条件来鼓励模型生成更多的tokens。此外,EGM可能还涉及到对tokens的选择机制进行优化,例如,使用一种基于置信度的选择策略,来过滤掉质量较差的tokens。
🖼️ 关键图片
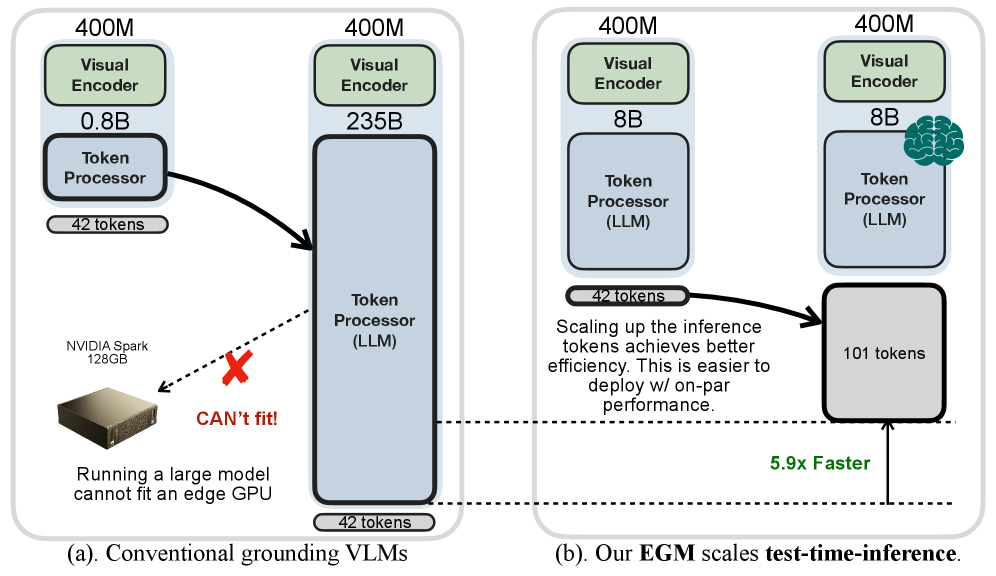

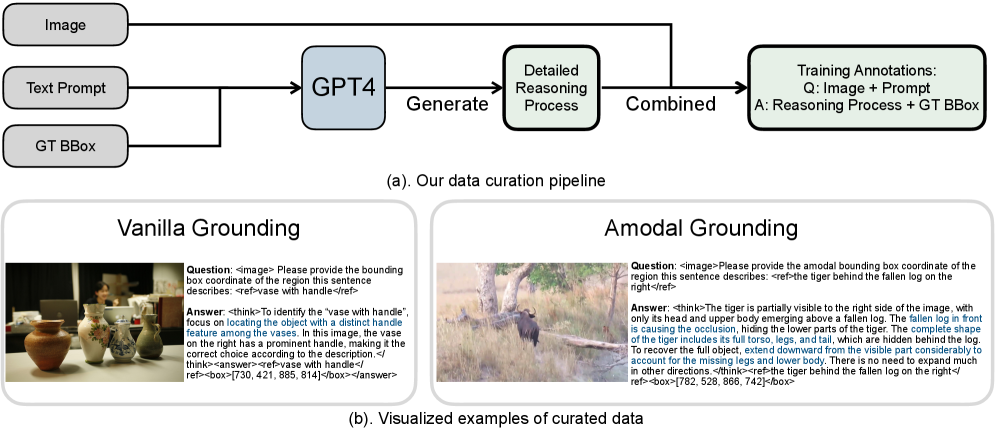
📊 实验亮点
EGM在RefCOCO基准测试中表现出色,EGM-Qwen3-VL-8B以平均737ms的延迟达到91.4的IoU,速度比Qwen3-VL-235B快5.9倍,同时精度更高(Qwen3-VL-235B需要4,320ms才能达到90.5的IoU)。此外,EGM在非模态定位任务中也取得了显著的提升,证明了其通用性和有效性。
🎯 应用场景
EGM具有广泛的应用前景,例如智能零售、自动驾驶、机器人导航等领域。它可以用于提升小型设备在视觉定位任务中的性能,使其能够更好地理解周围环境,并做出相应的决策。此外,EGM还可以用于开发更高效的视觉语言模型,从而降低计算成本,促进人工智能技术的普及。
📄 摘要(原文)
Visual grounding is an essential capability of Visual Language Models (VLMs) to understand the real physical world. Previous state-of-the-art grounding visual language models usually have large model sizes, making them heavy for deployment and slow for inference. However, we notice that the sizes of visual encoders are nearly the same for small and large VLMs and the major difference is the sizes of the language models. Small VLMs fall behind larger VLMs in grounding because of the difference in language understanding capability rather than visual information handling. To mitigate the gap, we introduce 'Efficient visual Grounding language Models' (EGM): generate many mid-quality tokens (from small models) to match the performance of large VLMs with few high-quality but expensive tokens. This method is deployment-friendly, and yields better end-to-end latency: On the RefCOCO benchmark, our EGM-Qwen3-VL-8B demonstrates 91.4 IoU with an average of 737ms (5.9x faster) latency while Qwen3-VL-235B demands 4,320ms to reach 90.5 IoU. To validate our approach's generality, we further set up a new amodal grounding setting that requires the model to predict both the visible and occluded parts of the objects. Experiments show our method consistently improves both vanilla and amodal grounding capabilities of small models to match or outperform larger models, thereby improving efficiency for visual grounding.