DePT3R: Joint Dense Point Tracking and 3D Reconstruction of Dynamic Scenes in a Single Forward Pass
作者: Vivek Alumootil, Tuan-Anh Vu
分类: cs.CV, cs.AI
发布日期: 2026-04-06
💡 一句话要点
DePT3R:单次前向传播实现动态场景的联合稠密点追踪与3D重建
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 动态场景理解 三维重建 稠密点追踪 多任务学习 深度学习
📋 核心要点
- 现有动态场景三维点追踪方法受限于成对处理、已知相机位姿或时间顺序,缺乏灵活性。
- DePT3R通过单次前向传播,联合执行稠密点追踪和三维重建,无需相机位姿。
- 实验表明,DePT3R在动态场景基准测试中表现出色,并在内存效率方面优于现有方法。
📝 摘要(中文)
目前动态场景中的稠密3D点追踪方法通常依赖于成对处理、需要已知的相机位姿或假设输入帧的时间顺序,从而限制了它们的灵活性和适用性。此外,最近的进展已成功地实现了从大规模、无位姿图像集合中进行高效的3D重建,突出了统一动态场景理解方法的机遇。受此启发,我们提出了DePT3R,这是一个新颖的框架,它在单次前向传播中同时执行来自多个图像的动态场景的稠密点追踪和3D重建。这种多任务学习是通过使用强大的骨干网络提取深度时空特征,并使用稠密预测头回归像素级图来实现的。至关重要的是,DePT3R在不需要相机位姿的情况下运行,从而大大提高了其适应性和效率,这在快速变化的动态环境中尤为重要。我们在几个涉及动态场景的具有挑战性的基准上验证了DePT3R,证明了其强大的性能,并且在内存效率方面比现有的最先进方法有了显著的改进。
🔬 方法详解
问题定义:论文旨在解决动态场景下稠密三维点追踪与三维重建问题。现有方法通常需要已知的相机位姿、依赖帧间配对或时间顺序,限制了其在复杂动态环境中的应用。这些限制导致计算效率低下,且难以处理无序或相机位姿未知的图像序列。
核心思路:DePT3R的核心思路是通过多任务学习,在一个统一的框架中同时进行稠密点追踪和三维重建。通过共享的深度时空特征提取,以及针对不同任务的预测头,实现高效且无需相机位姿的动态场景理解。这种设计旨在克服传统方法的局限性,提高处理动态场景的灵活性和效率。
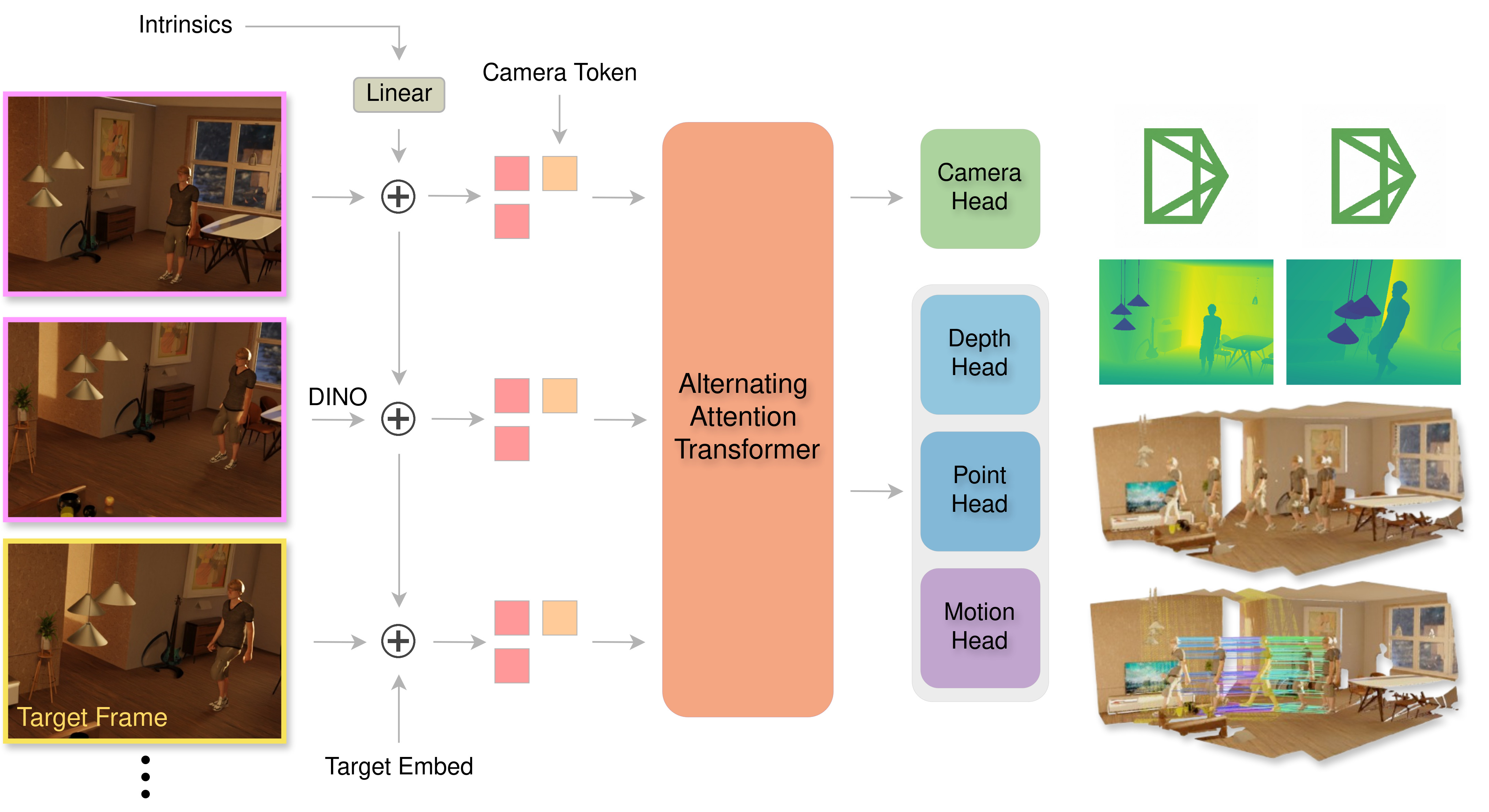
技术框架:DePT3R的整体框架包括以下几个主要模块:1) 深度时空特征提取骨干网络:用于从多张输入图像中提取丰富的时空特征。2) 稠密预测头:针对稠密点追踪和三维重建任务,分别设计预测头,将提取的特征映射到像素级别的追踪和重建结果。3) 多任务学习框架:通过联合优化追踪和重建任务的损失函数,实现知识共享和性能提升。整个流程以单次前向传播的方式进行,无需迭代优化或帧间配准。
关键创新:DePT3R最重要的技术创新在于其联合稠密点追踪和三维重建的能力,以及无需相机位姿的特性。与现有方法相比,DePT3R避免了复杂的帧间配准和位姿估计过程,大大简化了流程,提高了效率。此外,多任务学习框架使得追踪和重建任务可以相互促进,提升整体性能。
关键设计:DePT3R的关键设计包括:1) 深度时空特征提取骨干网络的选择,需要具备强大的特征表达能力和处理时序信息的能力。2) 针对追踪和重建任务的预测头的设计,需要能够有效地将特征映射到像素级别的结果。3) 多任务学习损失函数的设计,需要平衡不同任务之间的权重,并促进知识共享。具体的网络结构、损失函数和训练策略等细节在论文中进行了详细描述。
🖼️ 关键图片


📊 实验亮点
DePT3R在多个动态场景基准测试中取得了优异的性能,显著提高了内存效率。与现有最先进方法相比,DePT3R在保持甚至提升追踪和重建精度的同时,大幅降低了内存占用,使其更适用于资源受限的平台。具体的性能数据和对比结果可在论文的实验部分找到。
🎯 应用场景
DePT3R在机器人导航、自动驾驶、增强现实等领域具有广泛的应用前景。例如,在机器人导航中,可以利用DePT3R实时重建动态环境,并追踪运动物体的轨迹,从而实现更安全、更智能的导航。在自动驾驶中,可以用于感知周围的动态环境,预测行人和车辆的运动轨迹,提高驾驶安全性。在增强现实中,可以用于将虚拟物体与真实动态场景进行融合,提供更逼真的用户体验。
📄 摘要(原文)
Current methods for dense 3D point tracking in dynamic scenes typically rely on pairwise processing, require known camera poses, or assume temporal ordering of input frames, thereby constraining their flexibility and applicability. Additionally, recent advances have successfully enabled efficient 3D reconstruction from large-scale, unposed image collections, underscoring opportunities for unified approaches to dynamic scene understanding. Motivated by this, we propose DePT3R, a novel framework that simultaneously performs dense point tracking and 3D reconstruction of dynamic scenes from multiple images in a single forward pass. This multi-task learning is achieved by extracting deep spatio-temporal features with a powerful backbone and regressing pixel-wise maps with dense prediction heads. Crucially, DePT3R operates without requiring camera poses, substantially enhancing its adaptability and efficiency, especially important in dynamic environments with rapid changes. We validate DePT3R on several challenging benchmarks involving dynamic scenes, demonstrating strong performance and significant improvements in memory efficiency over existing state-of-the-art methods. Data and codes are available via the open repository:this https URL