Privacy Beyond Pixels: Latent Anonymization for Privacy-Preserving Video Understanding
作者: Joseph Fioresi, Ishan Rajendrakumar Dave, Mubarak Shah
分类: cs.CV
发布日期: 2026-04-06
💡 一句话要点
提出基于隐空间的匿名化适配模块,用于保护视频理解模型的隐私
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频隐私保护 隐空间匿名化 视频理解 自监督学习 迁移学习
📋 核心要点
- 现有像素级匿名化方法需重训练整个模型,且任务特定,不适用于视频基础模型。
- 提出匿名化适配模块(AAM),在隐空间移除隐私信息,保留任务效用,即插即用。
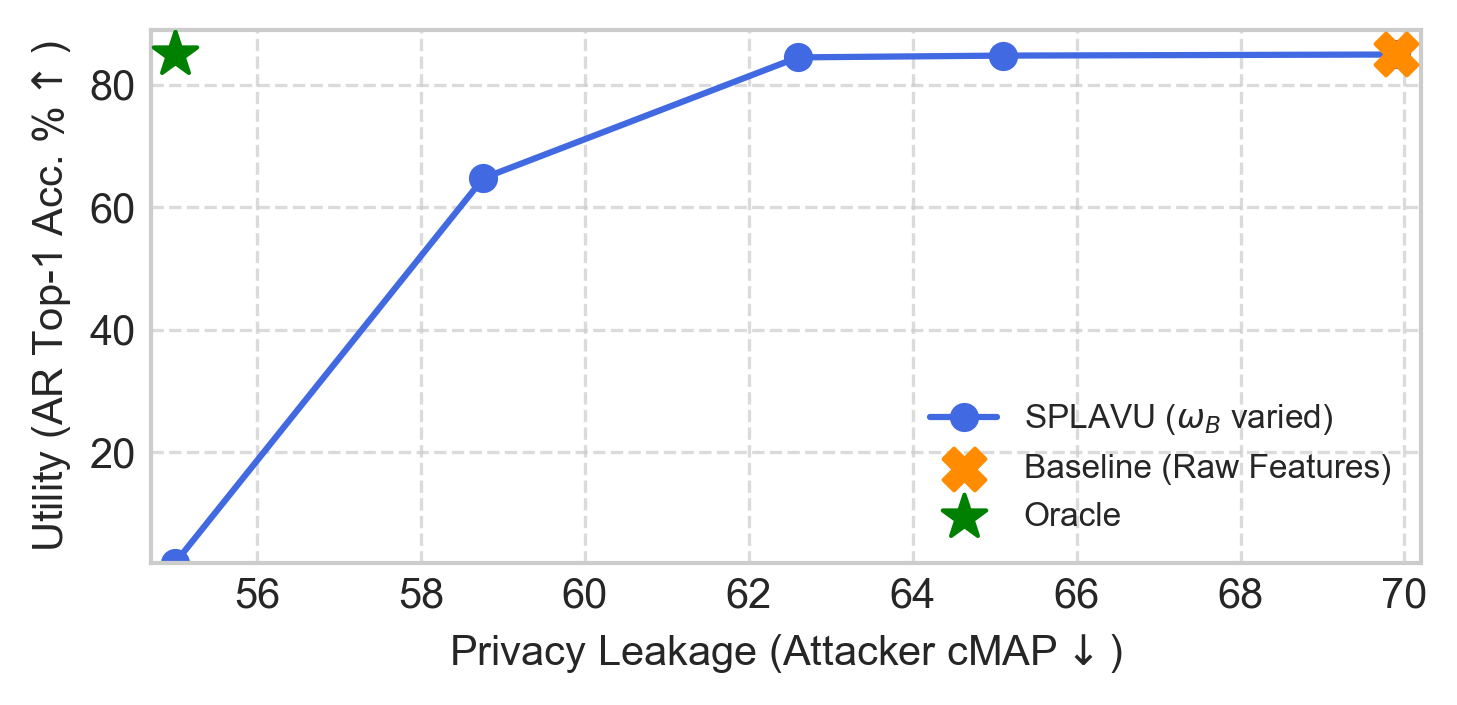
- 实验表明,隐私泄露减少35%,同时保持了动作识别、时间动作检测等任务的性能。
📝 摘要(中文)
本文提出了一种新颖的视频视觉隐私保护方法,该方法完全在隐空间中操作,适用于视频基础模型。虽然基础模型学习的时空特征加深了对视频内容的理解,但共享或存储这些提取的视觉特征会无意中泄露敏感的个人信息,如肤色、性别或服装。现有的隐私保护方法侧重于输入像素级的匿名化,这需要重新训练整个效用视频模型,并导致特定于任务的匿名化,使其不适用于最新的视频基础模型。为了解决这些挑战,我们引入了一个轻量级的匿名化适配模块(AAM),该模块从视频特征中删除私人信息,同时保留一般的任务效用。AAM可以以即插即用的方式应用于冻结的视频编码器,从而最大限度地减少了微调和重新提取特征的计算负担。我们的框架采用了三个新设计的训练目标:(1)剪辑级别的自监督隐私目标,以减少静态剪辑之间的互信息,(2)协同训练目标,以保持跨已见任务的效用,以及(3)潜在一致性损失,用于在未见任务上的泛化。我们广泛的评估表明,在各种下游任务中,隐私泄露显著减少了35%,同时保持了接近基线的效用性能:动作识别(Kinetics400、UCF101、HMDB51)、时间动作检测(THUMOS14)和异常检测(UCF-Crime)。我们还提供了对敏感时间属性识别的匿名化分析。此外,我们提出了新的协议来评估动作识别模型中的性别偏见,表明我们的方法有效地减轻了这种偏见,并促进了更公平的视频理解。
🔬 方法详解
问题定义:现有视频隐私保护方法主要集中在像素级别,需要对整个视频模型进行重新训练,计算成本高昂,并且匿名化效果是任务特定的,难以应用于预训练的视频基础模型。这些方法无法有效保护视频中潜在的敏感信息,例如身份、性别等,同时保持视频理解任务的性能。
核心思路:本文的核心思路是在视频基础模型的隐空间中进行匿名化处理,而不是直接在像素级别进行操作。通过学习一个轻量级的匿名化适配模块(AAM),将视频特征中的隐私信息移除,同时保留对下游任务有用的信息。这种方法避免了对整个模型的重新训练,降低了计算成本,并且可以灵活地应用于不同的视频基础模型。
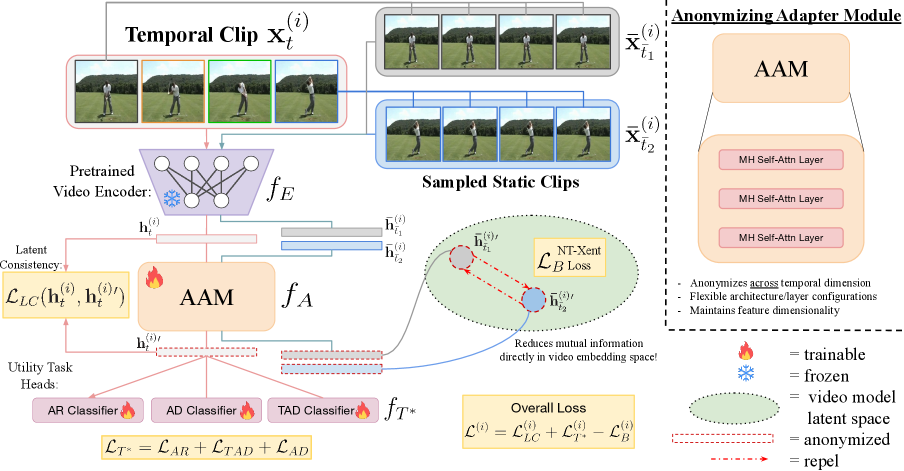
技术框架:该框架包含一个预训练的视频编码器和一个可学习的匿名化适配模块(AAM)。视频首先通过编码器提取特征,然后输入到AAM中进行匿名化处理。AAM的输出是匿名化的视频特征,可以用于下游任务。整个训练过程包括三个关键的损失函数:剪辑级别的自监督隐私损失,用于减少静态剪辑之间的互信息;协同训练损失,用于保持跨已见任务的效用;潜在一致性损失,用于在未见任务上的泛化。
关键创新:该方法最重要的创新点在于提出了在隐空间进行匿名化处理的思想,避免了对整个视频模型的重新训练,大大降低了计算成本。此外,AAM的设计使得它可以以即插即用的方式应用于不同的视频基础模型,具有很强的灵活性和通用性。三个损失函数的联合使用,保证了匿名化效果和任务性能的平衡。
关键设计:AAM的具体结构未知,但其目标是学习一个映射,将原始视频特征映射到匿名化的特征空间。剪辑级别的自监督隐私损失通过最大化不同剪辑之间的互信息来减少隐私泄露。协同训练损失通过在多个已见任务上进行训练来保持任务性能。潜在一致性损失通过鼓励AAM在不同任务上的输出一致性来提高泛化能力。具体的损失函数形式和网络结构细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在动作识别(Kinetics400、UCF101、HMDB51)、时间动作检测(THUMOS14)和异常检测(UCF-Crime)等多个下游任务上,隐私泄露显著减少了35%,同时保持了接近基线的效用性能。此外,该方法还能够有效减轻动作识别模型中的性别偏见。
🎯 应用场景
该研究成果可广泛应用于视频监控、视频会议、社交媒体等领域,保护用户隐私,防止敏感信息泄露。例如,在视频监控中,可以匿名化人脸、衣着等信息,同时保留对异常行为的检测能力。在视频会议中,可以匿名化背景信息,保护用户的家庭环境隐私。该技术还有助于减少视频分析中的性别偏见,促进更公平的视频理解。
📄 摘要(原文)
We introduce a novel formulation of visual privacy preservation for video foundation models that operates entirely in the latent space. While spatio-temporal features learned by foundation models have deepened general understanding of video content, sharing or storing these extracted visual features for downstream tasks inadvertently reveals sensitive personal information like skin color, gender, or clothing. Current privacy preservation methods focus on input-pixel-level anonymization, which requires retraining the entire utility video model and results in task-specific anonymization, making them unsuitable for recent video foundational models. To address these challenges, we introduce a lightweight Anonymizing Adapter Module (AAM) that removes private information from video features while retaining general task utility. AAM can be applied in a plug-and-play fashion to frozen video encoders, minimizing the computational burden of finetuning and re-extracting features. Our framework employs three newly designed training objectives: (1) a clip-level self-supervised privacy objective to reduce mutual information between static clips, (2) a co-training objective to retain utility across seen tasks, and (3) a latent consistency loss for generalization on unseen tasks. Our extensive evaluations demonstrate a significant 35% reduction in privacy leakage while maintaining near-baseline utility performance across various downstream tasks: Action Recognition (Kinetics400, UCF101, HMDB51), Temporal Action Detection (THUMOS14), and Anomaly Detection (UCF-Crime). We also provide an analysis on anonymization for sensitive temporal attribute recognition. Additionally, we propose new protocols for assessing gender bias in action recognition models, showing that our method effectively mitigates such biases and promotes more equitable video understanding.this https URL