VideoDetective: Clue Hunting via both Extrinsic Query and Intrinsic Relevance for Long Video Understanding
作者: Ruoliu Yang, Chu Wu, Caifeng Shan, Ran He, Chaoyou Fu
分类: cs.CV
发布日期: 2026-03-23
💡 一句话要点
VideoDetective:通过外部查询和内在关联进行线索挖掘,解决长视频理解难题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长视频理解 多模态学习 视频问答 图神经网络 线索挖掘
📋 核心要点
- 现有长视频理解方法主要依赖查询定位线索,忽略了视频内在结构和片段间相关性差异。
- VideoDetective框架融合查询-片段相关性和片段间亲和性,构建视觉-时间亲和图进行线索挖掘。
- 实验结果表明,该方法在多个基准测试中显著提升了长视频问答的准确率,最高达7.5%。
📝 摘要(中文)
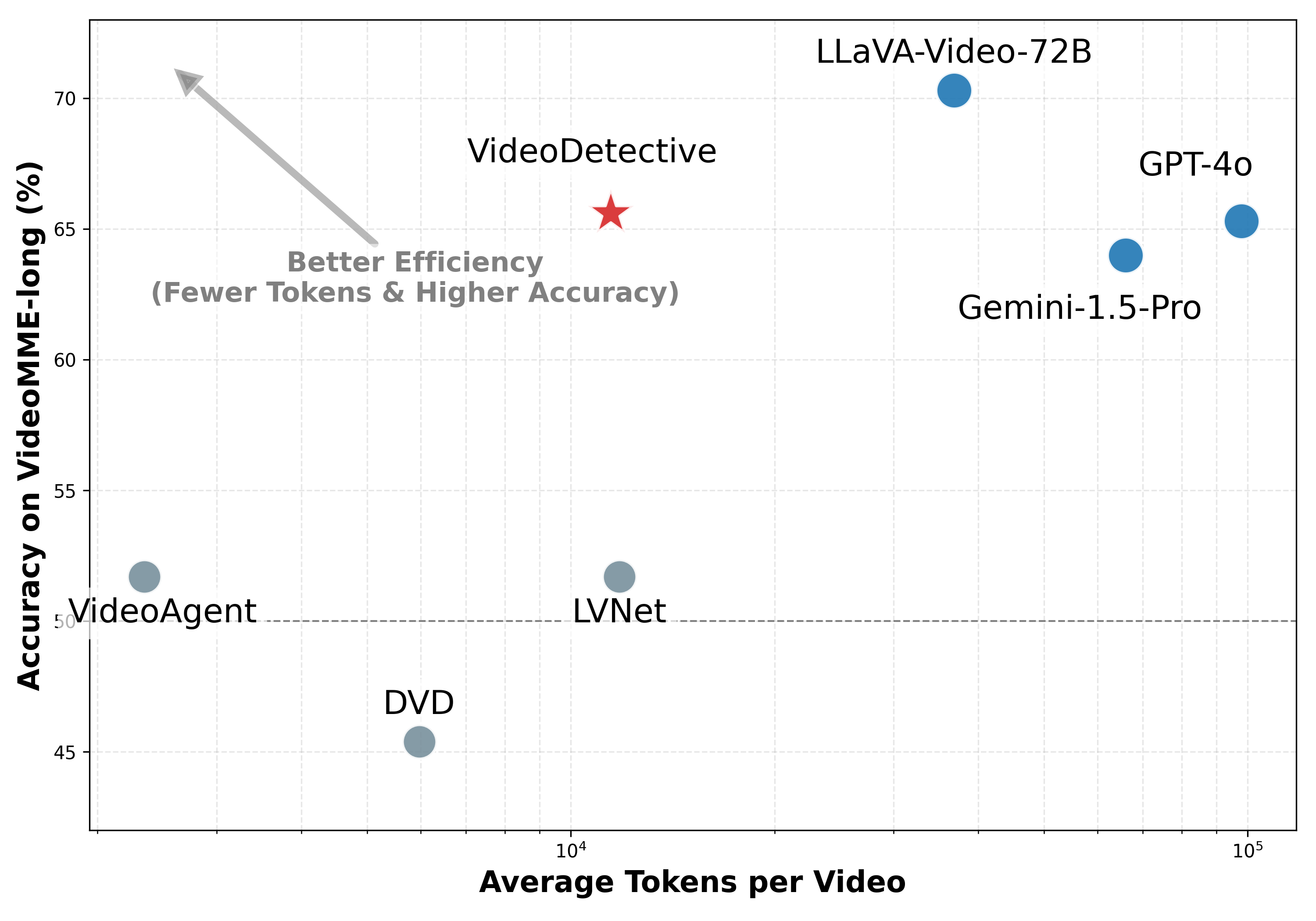
由于上下文窗口的限制,多模态大型语言模型(MLLM)在长视频理解方面仍然面临挑战,这需要识别与查询相关的稀疏视频片段。然而,现有方法主要基于查询来定位线索,忽略了视频的内在结构以及片段间不同的相关性。为了解决这个问题,我们提出了VideoDetective框架,该框架集成了查询到片段的相关性和片段间的亲和性,从而在长视频问答中进行有效的线索挖掘。具体来说,我们将视频分成多个片段,并将它们表示为一个由视觉相似性和时间邻近性构建的视觉-时间亲和图。然后,我们执行一个假设-验证-细化循环,以估计观察到的片段与查询的相关性得分,并将它们传播到未观察到的片段,从而产生一个全局相关性分布,该分布指导关键片段的定位,以便使用稀疏观察进行最终回答。实验表明,我们的方法在各种主流MLLM的代表性基准测试中始终如一地实现了显著的收益,在VideoMME-long上的准确率提高了高达7.5%。
🔬 方法详解
问题定义:长视频理解任务中,多模态大语言模型受限于上下文窗口大小,难以处理长视频。现有方法主要依赖查询来定位相关片段,忽略了视频自身的内容结构和片段之间的关联性,导致无法有效提取关键信息。这使得模型难以准确回答关于长视频的问题。
核心思路:VideoDetective的核心思路是同时考虑外部查询和视频内在关联性。它通过构建视频片段之间的亲和图,将查询相关性信息在图上传播,从而更全面地评估每个片段的重要性。这种方法能够利用视频自身的结构信息,弥补仅依赖查询的不足。
技术框架:VideoDetective框架主要包含以下几个阶段:1) 视频分割:将长视频分割成多个片段。2) 特征提取:提取每个片段的视觉特征。3) 亲和图构建:基于视觉相似性和时间邻近性构建片段间的亲和图。4) 相关性估计:使用假设-验证-细化循环估计观察到的片段与查询的相关性。5) 相关性传播:将相关性得分在亲和图上传播,得到全局相关性分布。6) 片段选择:根据全局相关性分布选择最关键的片段。7) 答案生成:使用选定的片段和查询生成最终答案。
关键创新:VideoDetective的关键创新在于同时利用外部查询和视频内在关联性进行线索挖掘。它通过构建视觉-时间亲和图,将查询相关性信息在图上传播,从而更全面地评估每个片段的重要性。这种方法能够有效利用视频自身的结构信息,弥补了仅依赖查询的不足。
关键设计:框架的关键设计包括:1) 亲和图的构建方式,如何平衡视觉相似性和时间邻近性。2) 假设-验证-细化循环的具体实现,如何有效地估计片段与查询的相关性。3) 相关性传播算法,如何保证信息在图上的有效传递。4) 片段选择策略,如何选择最关键的片段以提高答案的准确性。具体的参数设置、损失函数和网络结构等细节在论文中进行了详细描述。
🖼️ 关键图片


📊 实验亮点
实验结果表明,VideoDetective在多个长视频问答基准测试中取得了显著的性能提升。例如,在VideoMME-long数据集上,该方法在各种主流MLLM上实现了高达7.5%的准确率提升。这些结果证明了VideoDetective框架在长视频理解方面的有效性,并优于现有的方法。
🎯 应用场景
VideoDetective框架可应用于各种需要理解长视频内容的场景,例如:视频监控分析、智能安防、在线教育、电影分析、新闻报道等。通过更准确地提取视频中的关键信息,该研究可以提升相关应用的智能化水平,例如自动生成视频摘要、智能问答、内容推荐等,具有重要的实际应用价值和广阔的未来发展前景。
📄 摘要(原文)
Long video understanding remains challenging for multimodal large language models (MLLMs) due to limited context windows, which necessitate identifying sparse query-relevant video segments. However, existing methods predominantly localize clues based solely on the query, overlooking the video's intrinsic structure and varying relevance across segments. To address this, we propose VideoDetective, a framework that integrates query-to-segment relevance and inter-segment affinity for effective clue hunting in long-video question answering. Specifically, we divide a video into various segments and represent them as a visual-temporal affinity graph built from visual similarity and temporal proximity. We then perform a Hypothesis-Verification-Refinement loop to estimate relevance scores of observed segments to the query and propagate them to unseen segments, yielding a global relevance distribution that guides the localization of the most critical segments for final answering with sparse observation. Experiments show our method consistently achieves substantial gains across a wide range of mainstream MLLMs on representative benchmarks, with accuracy improvements of up to 7.5% on VideoMME-long. Our code is available at https://videodetective.github.io/