Omni-3DEdit: Generalized Versatile 3D Editing in One-Pass
作者: Chen Liyi, Wang Pengfei, Zhang Guowen, Ma Zhiyuan, Zhang Lei
分类: cs.CV
发布日期: 2026-03-18
备注: accepted by CVPR26
💡 一句话要点
Omni-3DEdit:提出一种通用、单次完成的3D编辑框架,解决传统方法效率低和任务依赖问题。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 3D编辑 指令驱动 生成模型 多视图学习 LoRA 隐式表示 数据合成
📋 核心要点
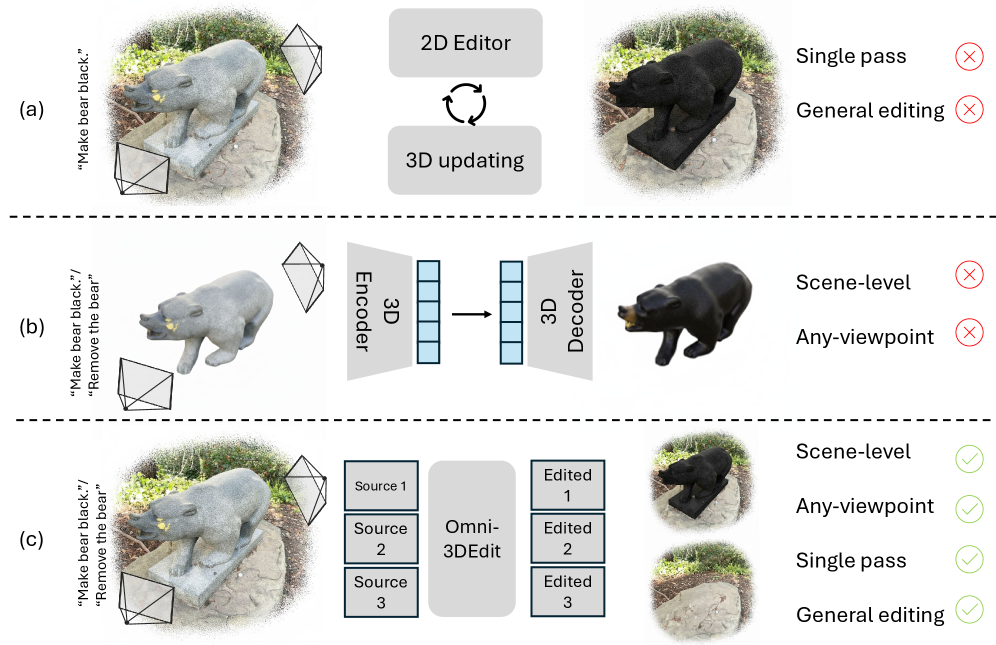
- 现有指令驱动的3D编辑方法依赖迭代优化,效率低下,且针对不同编辑任务需要定制规则,缺乏通用性。
- Omni-3DEdit提出一种基于学习的统一模型,通过隐式方式处理多种3D编辑任务,避免了耗时的迭代优化。
- 该方法构建了高质量的配对多视图编辑数据集,并设计了双流LoRA模块,提升了模型的表征学习能力,实验表明其有效性和效率。
📝 摘要(中文)
大多数指令驱动的3D编辑方法依赖于2D模型来指导3D表示的显式和迭代优化。然而,这种范式存在两个主要缺点。首先,它缺乏针对不同3D编辑任务的通用设计,因为对3D几何体的显式操作需要依赖于任务的规则,例如,3D外观编辑需要固有的源3D几何体,而3D移除会改变源几何体。其次,迭代优化过程非常耗时,通常需要数千次2D/3D更新。我们提出了Omni-3DEdit,一个统一的、基于学习的模型,它隐式地推广了各种3D编辑任务。实现我们目标的一个关键挑战是缺乏用于训练的配对源-编辑多视图资产。为了解决这个问题,我们构建了一个数据管道,合成相对丰富的、高质量的配对多视图编辑样本。随后,我们通过在序列空间中连接源视图潜在变量和条件token,将预训练的生成模型SEVA作为我们的骨干。我们提出了一种双流LoRA模块来解耦不同的视图线索,从而大大增强了我们模型的表征学习能力。作为一个基于学习的模型,我们的模型无需耗时的在线优化,并且可以在一次前向传递中完成各种3D编辑任务,将推理时间从数十分钟减少到大约两分钟。大量的实验证明了Omni-3DEdit的有效性和效率。
🔬 方法详解
问题定义:现有指令驱动的3D编辑方法主要依赖于2D模型指导3D表示的显式迭代优化。这种方法的痛点在于:一是缺乏通用性,不同编辑任务(如外观编辑、移除)需要不同的规则和操作;二是迭代优化过程耗时,需要大量的2D/3D更新,效率低下。
核心思路:Omni-3DEdit的核心思路是采用一个基于学习的统一模型,通过隐式的方式处理各种3D编辑任务。模型学习从源视图到编辑后视图的映射关系,避免了显式的几何操作和迭代优化,从而提高了效率和通用性。
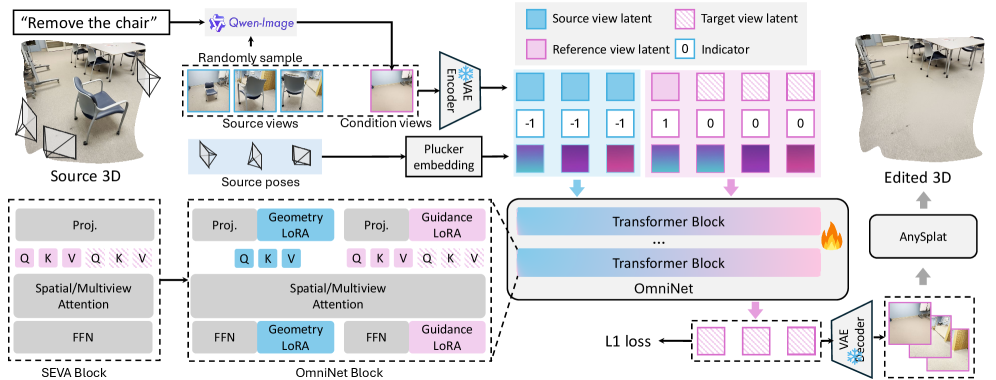
技术框架:Omni-3DEdit的整体框架包括数据合成管道和模型架构两部分。数据合成管道用于生成高质量的配对源-编辑多视图数据集。模型架构基于预训练的生成模型SEVA,通过连接源视图潜在变量和条件token作为输入。为了解耦不同视图的信息,引入了双流LoRA模块。
关键创新:Omni-3DEdit的关键创新在于:一是提出了一个统一的、基于学习的3D编辑框架,能够处理多种编辑任务;二是设计了双流LoRA模块,有效解耦了不同视图的信息,提升了模型的表征能力;三是构建了一个高质量的配对多视图编辑数据集,为模型的训练提供了数据支持。
关键设计:模型使用预训练的SEVA作为backbone,并在此基础上进行fine-tune。双流LoRA模块分别处理源视图和条件token,然后将它们融合。损失函数未知,但可以推测使用了重建损失和对抗损失等。
🖼️ 关键图片

📊 实验亮点
Omni-3DEdit能够在一次前向传递中完成各种3D编辑任务,将推理时间从传统方法的数十分钟缩短到大约两分钟,显著提高了效率。实验结果表明,Omni-3DEdit在多种3D编辑任务上都取得了良好的效果,证明了其有效性和通用性。具体的性能数据和对比基线在论文中进行了详细展示。
🎯 应用场景
Omni-3DEdit具有广泛的应用前景,例如游戏资产生成、虚拟现实内容创作、电商产品展示等。它可以根据用户的指令快速生成高质量的3D编辑结果,降低了3D内容创作的门槛,并有望推动相关产业的发展。未来,该技术还可以应用于3D打印、机器人等领域。
📄 摘要(原文)
Most instruction-driven 3D editing methods rely on 2D models to guide the explicit and iterative optimization of 3D representations. This paradigm, however, suffers from two primary drawbacks. First, it lacks a universal design of different 3D editing tasks because the explicit manipulation of 3D geometry necessitates task-dependent rules, e.g., 3D appearance editing demands inherent source 3D geometry, while 3D removal alters source geometry. Second, the iterative optimization process is highly time-consuming, often requiring thousands of invocations of 2D/3D updating. We present Omni-3DEdit, a unified, learning-based model that generalizes various 3D editing tasks implicitly. One key challenge to achieve our goal is the scarcity of paired source-edited multi-view assets for training. To address this issue, we construct a data pipeline, synthesizing a relatively rich number of high-quality paired multi-view editing samples. Subsequently, we adapt the pre-trained generative model SEVA as our backbone by concatenating source view latents along with conditional tokens in sequence space. A dual-stream LoRA module is proposed to disentangle different view cues, largely enhancing our model's representational learning capability. As a learning-based model, our model is free of the time-consuming online optimization, and it can complete various 3D editing tasks in one forward pass, reducing the inference time from tens of minutes to approximately two minutes. Extensive experiments demonstrate the effectiveness and efficiency of Omni-3DEdit.