Rationale Matters: Learning Transferable Rubrics via Proxy-Guided Critique for VLMReward Models
作者: Weijie Qiu, Dai Guan, Junxin Wang, Zhihang Li, Yongbo Gai, Mengyu Zhou, Erchao Zhao, Xiaoxi Jiang, Guanjun Jiang
分类: cs.CV
发布日期: 2026-03-17
备注: 25 pages, 10 figures,
🔗 代码/项目: GITHUB
💡 一句话要点
提出Proxy-GRM,通过代理引导的评价标准学习提升视觉-语言模型奖励模型的性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 奖励模型 评价标准学习 代理学习 强化学习 可迁移性 多模态学习
📋 核心要点
- 现有视觉-语言模型奖励模型(GRM)缺乏对中间评价标准的直接优化,导致性能瓶颈。
- Proxy-GRM通过引入代理引导的评价标准验证,显式提升评价标准的质量和可迁移性。
- 实验表明,Proxy-GRM在多个基准测试中达到SOTA,且学习到的评价标准具有良好的泛化能力。
📝 摘要(中文)
用于视觉-语言模型(VLM)的生成式奖励模型(GRM)通常通过三阶段流程评估输出:评价标准生成、基于标准的评分和最终判断。然而,中间的评价标准很少被直接优化。先前的工作通常将评价标准视为附带的,或者依赖于昂贵的LLM-as-judge检查,这些检查不提供可微信号和有限的训练时指导。我们提出了Proxy-GRM,它将代理引导的评价标准验证引入到强化学习(RL)中,以显式地提高评价标准的质量。具体来说,我们训练轻量级的代理智能体(Proxy-SFT和Proxy-RL),它们将候选评价标准与原始查询和偏好对一起作为输入,然后仅使用评价标准作为证据来预测偏好排序。代理的预测准确性作为评价标准质量的奖励,激励模型生成内部一致且可转移的评价标准。使用约5万个数据样本,Proxy-GRM在VL-Reward Bench、Multimodal Reward Bench和MM-RLHF-Reward Bench上达到了最先进的结果,优于在四倍数据上训练的方法。消融实验表明Proxy-SFT比Proxy-RL更强大,隐式奖励聚合效果最佳。至关重要的是,学习到的评价标准可以转移到未见过的评估器,在测试时提高奖励准确性,而无需额外的训练。我们的代码可在https://github.com/Qwen-Applications/Proxy-GRM上找到。
🔬 方法详解
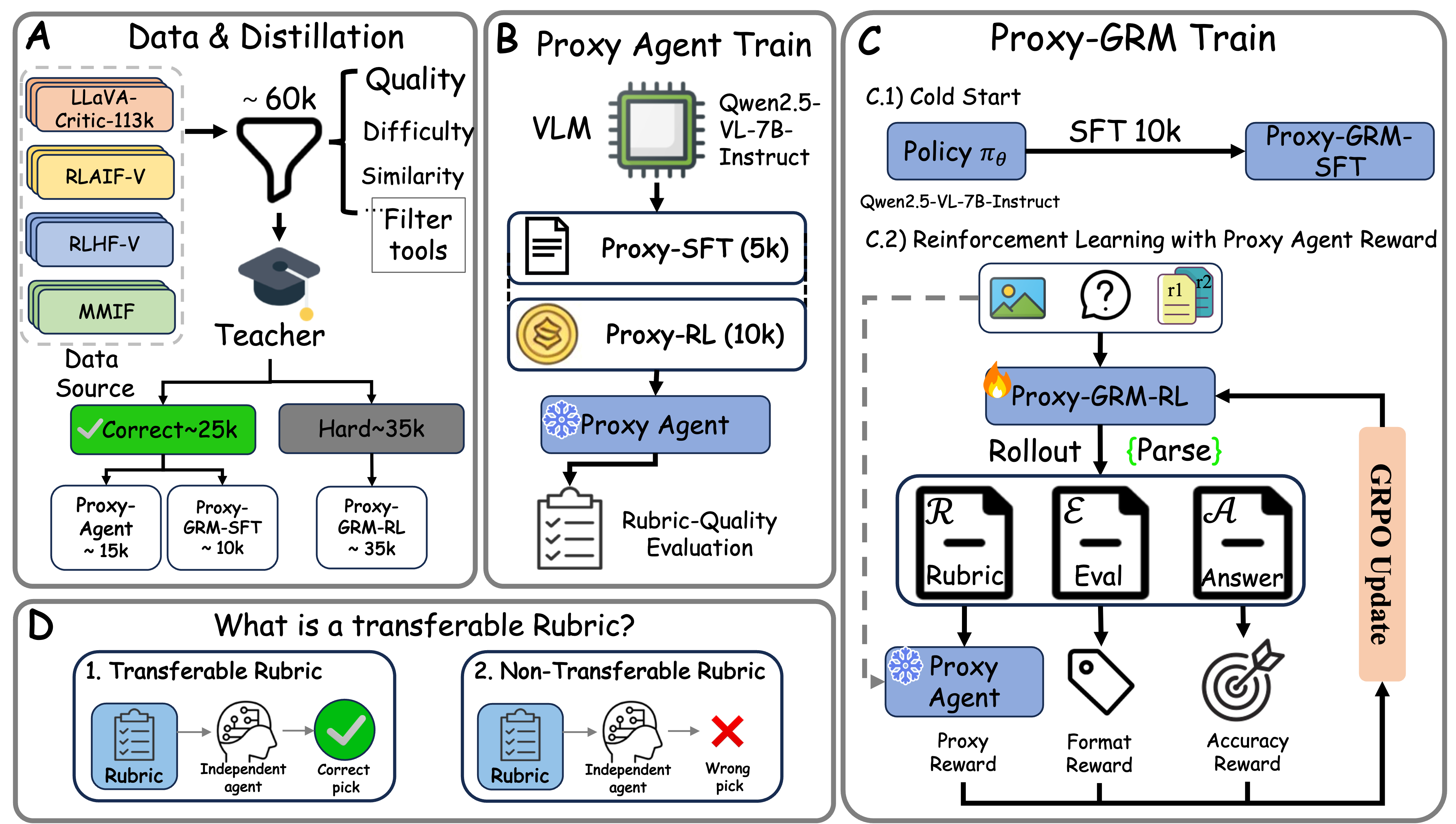
问题定义:现有视觉-语言模型奖励模型(VLMReward Models)在生成奖励时,通常依赖生成评价标准(rubric),然后基于此进行评分。然而,这些模型很少直接优化生成的评价标准,导致评价标准质量不高,影响最终奖励的准确性。此外,使用大型语言模型(LLM)作为裁判进行评价标准验证成本高昂,且缺乏可微信号,难以进行有效训练。
核心思路:Proxy-GRM的核心思路是引入轻量级的代理模型(Proxy Agents)来评估评价标准的质量。这些代理模型以候选评价标准、原始查询和偏好对作为输入,预测偏好排序。代理模型的预测准确性被用作评价标准质量的奖励信号,从而激励模型生成更准确、一致和可迁移的评价标准。
技术框架:Proxy-GRM的整体框架包括以下几个主要模块:1) 评价标准生成器:生成候选的评价标准。2) 代理模型(Proxy-SFT和Proxy-RL):评估候选评价标准的质量,并预测偏好排序。3) 奖励函数:基于代理模型的预测准确性,生成评价标准质量的奖励信号。4) 强化学习(RL)优化:使用奖励信号优化评价标准生成器,使其生成更高质量的评价标准。
关键创新:Proxy-GRM的关键创新在于引入了代理模型来显式地评估和优化评价标准的质量。与现有方法相比,Proxy-GRM不需要昂贵的LLM-as-judge检查,并且能够提供可微的奖励信号,从而实现更有效的训练。此外,Proxy-GRM学习到的评价标准具有良好的可迁移性,可以泛化到未见过的评估器。
关键设计:Proxy-GRM使用了两种类型的代理模型:Proxy-SFT(监督微调)和Proxy-RL(强化学习)。Proxy-SFT通过监督学习的方式,学习预测偏好排序。Proxy-RL则通过强化学习的方式,学习最大化预测准确性。实验表明,Proxy-SFT作为评价标准验证器效果更好。此外,Proxy-GRM使用了隐式奖励聚合,即将代理模型的预测结果直接用于优化评价标准生成器,而无需显式地计算奖励值。
🖼️ 关键图片


📊 实验亮点
Proxy-GRM在VL-Reward Bench、Multimodal Reward Bench和MM-RLHF-Reward Bench等多个基准测试中取得了最先进的结果,超过了使用四倍数据训练的其他方法。消融实验表明,Proxy-SFT作为评价标准验证器比Proxy-RL更有效,隐式奖励聚合策略表现最佳。更重要的是,学习到的评价标准能够成功迁移到未见过的评估器,在测试时提高奖励准确性,无需额外训练。
🎯 应用场景
Proxy-GRM可应用于各种需要视觉-语言模型进行评价和奖励的场景,例如图像描述生成、视觉问答、多模态对话等。该方法能够提高奖励模型的准确性和泛化能力,从而提升视觉-语言模型的性能和用户体验。此外,Proxy-GRM学习到的可迁移评价标准可以降低人工标注成本,提高模型部署效率。
📄 摘要(原文)
Generative reward models (GRMs) for vision-language models (VLMs) often evaluate outputs via a three-stage pipeline: rubric generation, criterion-based scoring, and a final verdict. However, the intermediate rubric is rarely optimized directly. Prior work typically either treats rubrics as incidental or relies on expensive LLM-as-judge checks that provide no differentiable signal and limited training-time guidance. We propose Proxy-GRM, which introduces proxy-guided rubric verification into Reinforcement Learning (RL) to explicitly enhance rubric quality. Concretely, we train lightweight proxy agents (Proxy-SFT and Proxy-RL) that take a candidate rubric together with the original query and preference pair, and then predict the preference ordering using only the rubric as evidence. The proxy's prediction accuracy serves as a rubric-quality reward, incentivizing the model to produce rubrics that are internally consistent and transferable. With ~50k data samples, Proxy-GRM reaches state-of-the-art results on the VL-Reward Bench, Multimodal Reward Bench, and MM-RLHF-Reward Bench, outperforming the methods trained on four times the data. Ablations show Proxy-SFT is a stronger verifier than Proxy-RL, and implicit reward aggregation performs best. Crucially, the learned rubrics transfer to unseen evaluators, improving reward accuracy at test time without additional training. Our code is available at https://github.com/Qwen-Applications/Proxy-GRM.