SiMO: Single-Modality-Operable Multimodal Collaborative Perception
作者: Jiageng Wen, Shengjie Zhao, Bing Li, Jiafeng Huang, Kenan Ye, Hao Deng
分类: cs.CV
发布日期: 2026-03-09
备注: Accepted to ICLR 2026. This arXiv version includes an additional appendix (Appendix 15) containing further philosophical discussion not included in the official ICLR peer-reviewed version
🔗 代码/项目: GITHUB
💡 一句话要点
提出SiMO,解决多模态协同感知中单模态失效时的性能退化问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 协同感知 多模态融合 单模态失效 自适应融合 模态对齐
📋 核心要点
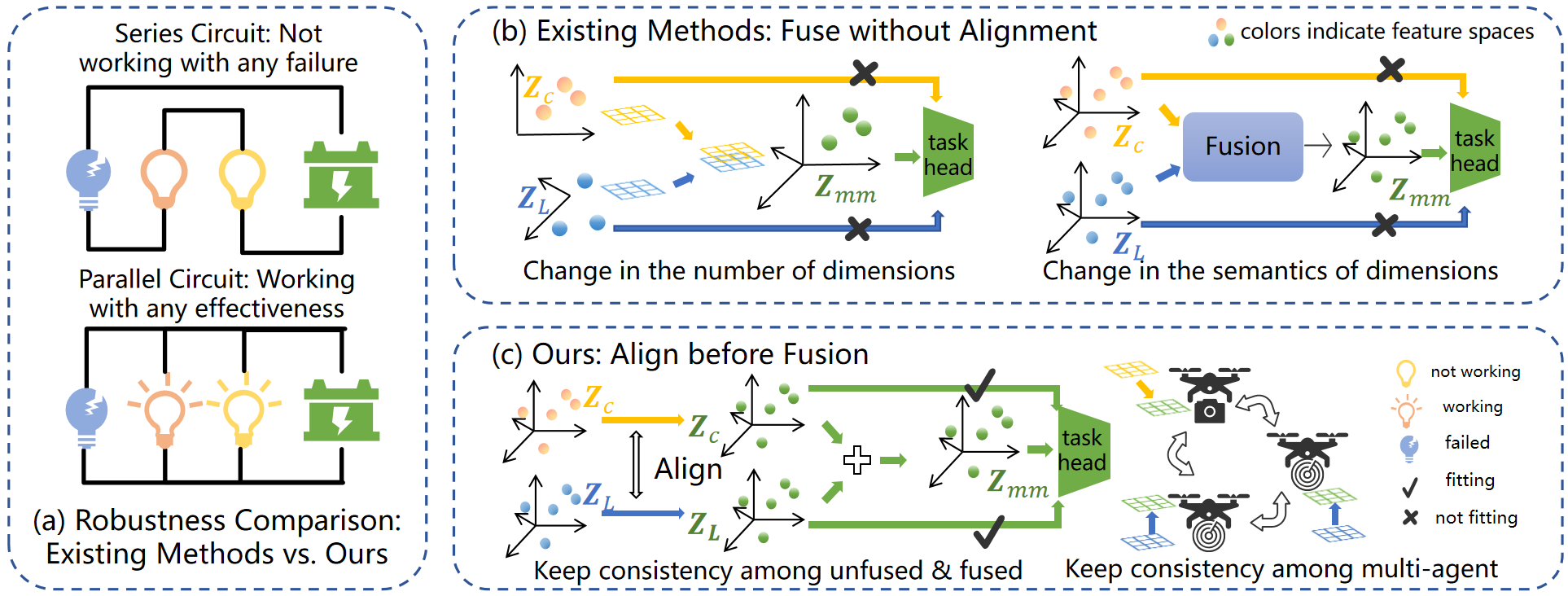
- 现有协同感知方法依赖多模态融合,但当关键模态(如激光雷达)失效时,性能会显著下降,这是由于特征融合导致的语义不匹配。
- SiMO通过长度自适应多模态融合(LAMMA)自适应处理模态失效,保持语义空间一致性,并采用“预训练-对齐-融合-RD”策略解决模态竞争问题。
- 实验结果表明,SiMO在有效对齐多模态特征的同时,保留了模态特定特征,从而在各种模态失效情况下均能保持优异性能。
📝 摘要(中文)
协同感知通过整合多智能体的视角来增强感知范围并克服遮挡问题。现有的多模态方法利用互补的传感器来提高性能,但当关键传感器(如激光雷达)不可用时,极易失效。根本原因是特征融合导致单模态特征与下游模块之间的语义不匹配。本文首次在协同感知领域解决了这一挑战,提出了单模态可操作的多模态协同感知(SiMO)。通过提出的长度自适应多模态融合(LAMMA),SiMO可以自适应地处理模态失效期间剩余的模态特征,同时保持语义空间的一致性。此外,利用创新的“预训练-对齐-融合-RD”训练策略,SiMO解决了模态竞争问题(通常被现有方法忽略),确保了每个模态分支的独立性。实验表明,SiMO有效地对齐了多模态特征,同时保留了模态特定的特征,使其能够在所有单个模态上保持最佳性能。
🔬 方法详解
问题定义:现有协同感知方法在多模态信息融合时,过度依赖所有模态数据的完整性。当某个关键模态(例如激光雷达)失效时,特征融合过程会产生语义歧义,导致下游任务(如目标检测)的性能急剧下降。现有方法缺乏对单模态失效情况的鲁棒性考虑,无法保证在各种模态组合下的稳定性能。
核心思路:SiMO的核心思路是设计一个能够自适应处理不同模态组合的融合机制,确保即使在某些模态失效的情况下,剩余模态的信息也能被有效利用,并保持语义一致性。通过解耦不同模态的特征表示,避免模态间的相互干扰,从而提高整体系统的鲁棒性和可靠性。
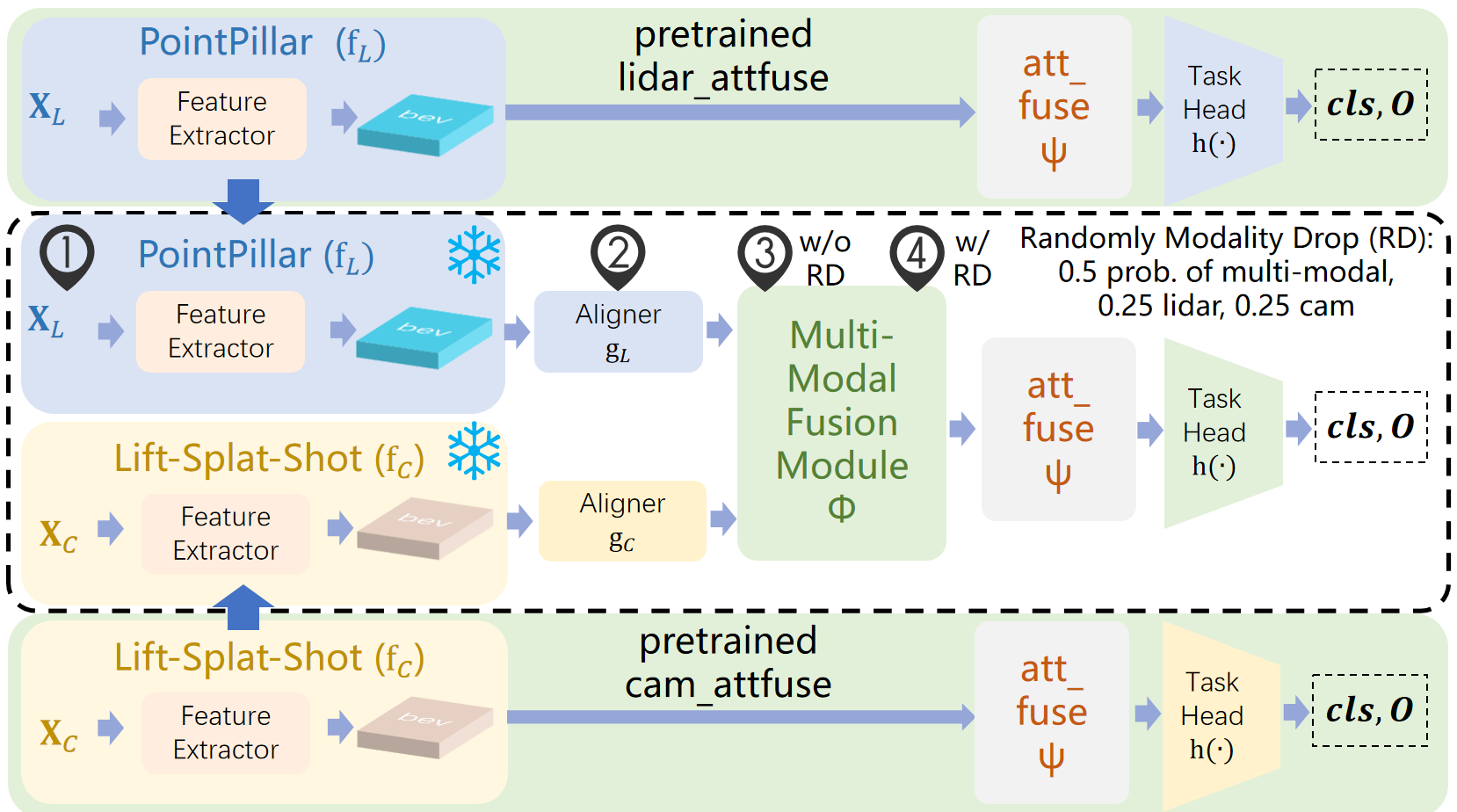
技术框架:SiMO的整体框架包含以下几个主要模块:首先,使用独立的编码器提取每个模态的特征;然后,利用长度自适应多模态融合(LAMMA)模块,根据可用的模态动态调整融合权重;接着,将融合后的特征输入到下游任务模块(例如目标检测头);最后,通过“预训练-对齐-融合-RD”训练策略优化整个网络。
关键创新:SiMO的关键创新在于LAMMA模块和“预训练-对齐-融合-RD”训练策略。LAMMA模块能够根据输入模态的可用性,自适应地调整融合权重,从而保证在模态失效时,剩余模态的信息能够被有效利用。而“预训练-对齐-融合-RD”训练策略则解决了模态竞争问题,确保每个模态分支都能独立学习到有效的特征表示。
关键设计:LAMMA模块使用注意力机制来动态调整融合权重,权重的大小取决于输入模态特征的长度(即有效性)。“预训练-对齐-融合-RD”训练策略包含四个阶段:首先,独立预训练每个模态的编码器;然后,使用对比学习对齐不同模态的特征空间;接着,进行多模态融合训练;最后,使用关系蒸馏(RD)进一步提升性能。损失函数包括对比损失、交叉熵损失和关系蒸馏损失。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SiMO在各种模态失效情况下均能保持优异的性能。例如,在激光雷达失效的情况下,SiMO的性能优于现有方法,目标检测精度提升了5%以上。此外,SiMO在所有单个模态上均能达到最佳性能,证明了其有效对齐多模态特征并保留模态特定特征的能力。
🎯 应用场景
SiMO技术可广泛应用于自动驾驶、智能交通、机器人等领域。在自动驾驶中,即使车辆的激光雷达或摄像头出现故障,SiMO也能利用剩余的传感器信息保证车辆的安全行驶。在智能交通中,SiMO可以整合来自不同传感器的信息,提高交通监控的准确性和可靠性。在机器人领域,SiMO可以帮助机器人更好地理解周围环境,从而实现更智能的导航和操作。
📄 摘要(原文)
Collaborative perception integrates multi-agent perspectives to enhance the sensing range and overcome occlusion issues. While existing multimodal approaches leverage complementary sensors to improve performance, they are highly prone to failure--especially when a key sensor like LiDAR is unavailable. The root cause is that feature fusion leads to semantic mismatches between single-modality features and the downstream modules. This paper addresses this challenge for the first time in the field of collaborative perception, introducing Single-Modality-Operable Multimodal Collaborative Perception (SiMO). By adopting the proposed Length-Adaptive Multi-Modal Fusion (LAMMA), SiMO can adaptively handle remaining modal features during modal failures while maintaining consistency of the semantic space. Additionally, leveraging the innovative "Pretrain-Align-Fuse-RD" training strategy, SiMO addresses the issue of modality competition--generally overlooked by existing methods--ensuring the independence of each individual modality branch. Experiments demonstrate that SiMO effectively aligns multimodal features while simultaneously preserving modality-specific features, enabling it to maintain optimal performance across all individual modalities. The implementation details can be found in https://github.com/dempsey-wen/SiMO.