TrianguLang: Geometry-Aware Semantic Consensus for Pose-Free 3D Localization
作者: Bryce Grant, Aryeh Rothenberg, Atri Banerjee, Peng Wang
分类: cs.CV
发布日期: 2026-03-09
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
TrianguLang:提出几何感知语义共识的无姿态3D定位方法
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D定位 自然语言理解 几何感知 语义分割 跨视图特征对应
📋 核心要点
- 现有3D定位方法在精度和几何一致性与效率之间存在trade-off,限制了其在实际场景中的应用。
- TrianguLang通过引入几何感知语义注意力(GASA)机制,在无需相机标定的情况下实现高效且几何一致的3D定位。
- 实验表明,TrianguLang在多个基准测试中取得了state-of-the-art的性能,并显著降低了用户交互成本。
📝 摘要(中文)
本文提出TrianguLang,一个用于3D空间中基于自然语言定位物体和部件的前馈框架,无需相机标定即可进行推理。现有方法需要在每场景优化的准确性和几何一致性与前馈推理的效率之间进行权衡。与独立处理视图的先前方法不同,TrianguLang引入了几何感知语义注意力(GASA),它利用预测的几何信息来控制跨视图特征对应,抑制语义上合理但几何上不一致的匹配,而无需ground-truth姿态。在包括ScanNet++和uCO3D在内的五个基准测试中验证,TrianguLang实现了最先进的前馈文本引导分割和定位,将用户工作量从O(N)次点击减少到单个文本查询。该模型以约57ms(约18 FPS)处理1008x1008分辨率的每一帧,无需优化,从而为交互式机器人和AR应用实现实际部署。代码和检查点可在https://cwru-aism.github.io/triangulang/ 获得。
🔬 方法详解
问题定义:现有基于文本的3D物体定位方法通常需要对每个场景进行优化,计算成本高昂,难以满足实时性要求。此外,一些方法依赖于精确的相机姿态信息,限制了其在未知环境中的应用。这些方法往往独立处理各个视图,忽略了视图之间的几何约束,导致定位结果不一致。
核心思路:TrianguLang的核心思路是利用场景的几何信息来约束跨视图的语义匹配,从而在无需相机姿态的情况下实现几何一致的3D定位。通过预测场景几何,并将其融入到跨视图特征对应过程中,可以有效地抑制语义上合理但几何上不一致的匹配,提高定位的准确性和鲁棒性。
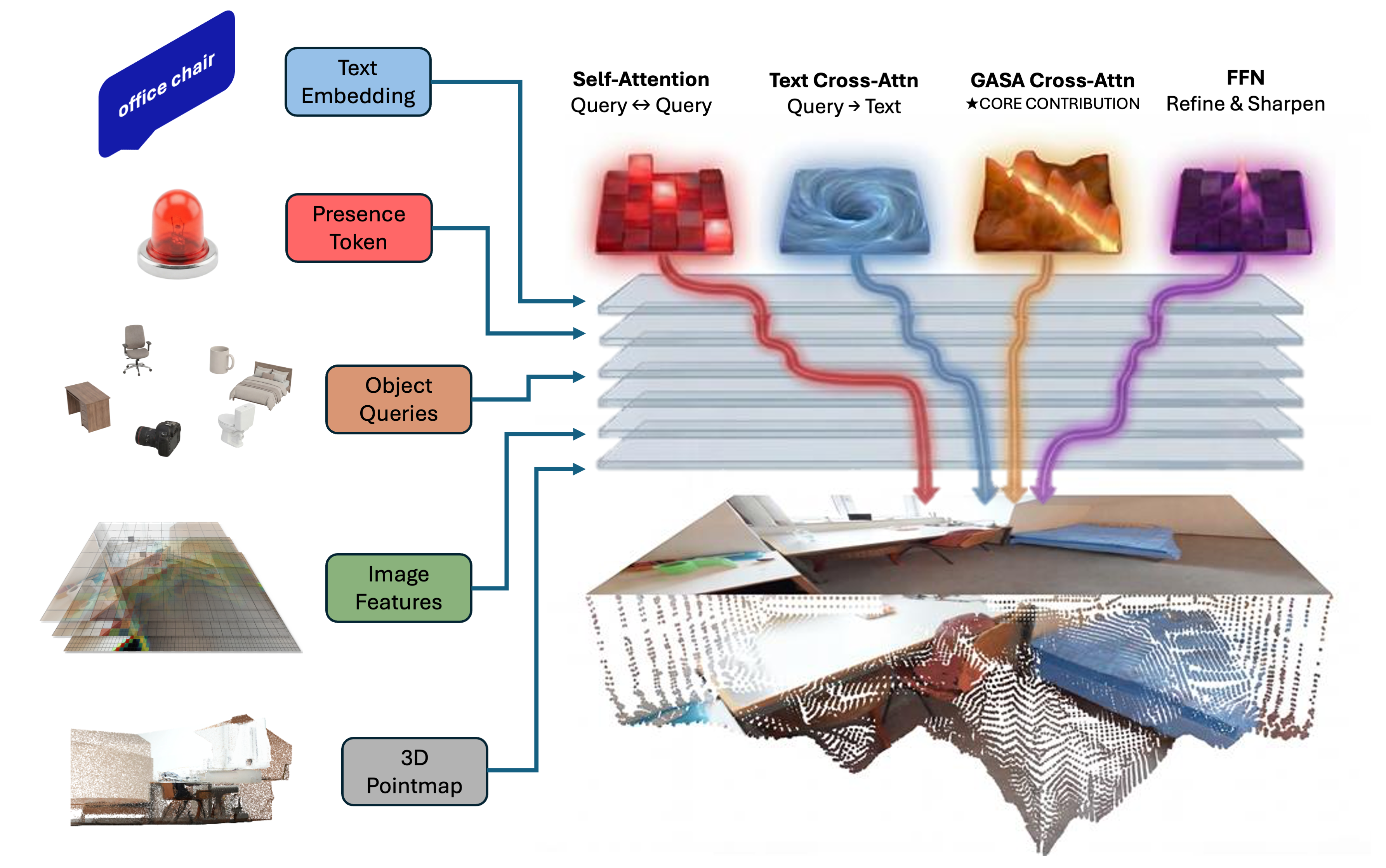
技术框架:TrianguLang是一个前馈框架,主要包含以下几个模块:1) 视觉特征提取模块:用于提取各个视图的视觉特征。2) 几何预测模块:用于预测场景的几何信息,例如深度图或点云。3) 文本特征提取模块:用于提取文本查询的语义特征。4) 几何感知语义注意力(GASA)模块:利用预测的几何信息来控制跨视图特征对应,抑制几何不一致的匹配。5) 3D定位模块:基于跨视图的语义匹配结果,预测目标物体在3D空间中的位置。
关键创新:TrianguLang最重要的技术创新点是Geometry-Aware Semantic Attention (GASA)模块。GASA模块将预测的几何信息融入到跨视图特征对应过程中,通过几何约束来过滤掉不合理的匹配,从而提高定位的准确性和几何一致性。与现有方法相比,GASA模块无需ground-truth姿态信息,可以在未知环境中进行定位。
关键设计:GASA模块的关键设计在于如何有效地利用几何信息来控制跨视图特征对应。具体来说,GASA模块首先计算各个视图的特征之间的相似度矩阵,然后利用预测的深度信息来计算几何一致性得分。最后,将相似度矩阵和几何一致性得分进行融合,得到最终的注意力权重。通过这种方式,GASA模块可以有效地抑制语义上合理但几何上不一致的匹配。
🖼️ 关键图片


📊 实验亮点
TrianguLang在ScanNet++和uCO3D等五个基准测试中取得了state-of-the-art的性能。与现有方法相比,TrianguLang显著提高了文本引导的分割和定位精度,并将用户交互成本从O(N)次点击降低到单个文本查询。该模型能够以约18 FPS的速度处理高分辨率图像,满足实时性要求。
🎯 应用场景
TrianguLang在机器人、增强现实(AR)和具身智能等领域具有广泛的应用前景。例如,在机器人导航中,可以通过自然语言指令引导机器人找到目标物体。在AR应用中,可以将虚拟物体放置在真实场景中的指定位置。此外,TrianguLang还可以用于3D场景理解和语义地图构建等任务。
📄 摘要(原文)
Localizing objects and parts from natural language in 3D space is essential for robotics, AR, and embodied AI, yet existing methods face a trade-off between the accuracy and geometric consistency of per-scene optimization and the efficiency of feed-forward inference. We present TrianguLang, a feed-forward framework for 3D localization that requires no camera calibration at inference. Unlike prior methods that treat views independently, we introduce Geometry-Aware Semantic Attention (GASA), which utilizes predicted geometry to gate cross-view feature correspondence, suppressing semantically plausible but geometrically inconsistent matches without requiring ground-truth poses. Validated on five benchmarks including ScanNet++ and uCO3D, TrianguLang achieves state-of-the-art feed-forward text-guided segmentation and localization, reducing user effort from $O(N)$ clicks to a single text query. The model processes each frame at 1008x1008 resolution in $\sim$57ms ($\sim$18 FPS) without optimization, enabling practical deployment for interactive robotics and AR applications. Code and checkpoints are available at https://cwru-aism.github.io/triangulang/.